Which is Better for Running LLMs locally: Apple M3 Pro 150gb 14cores or NVIDIA L40S 48GB? Ultimate Benchmark Analysis
Introduction
The world of Large Language Models (LLMs) is exploding, with new models and applications emerging every day. Running these powerful AI models locally can be beneficial for developers seeking faster processing, increased privacy, and reduced dependency on cloud services. For developers, the choice of hardware can significantly impact performance and cost. This article compares two popular options: the Apple M3 Pro 150GB 14 Cores and the NVIDIA L40S 48GB, analyzing their strengths and weaknesses for running LLMs locally.
Performance Analysis: Token Speed Generation
Understanding Token Speed: Tokens are the building blocks of text in LLMs. They are like words in a simple language, but they can also be punctuation marks, symbols, and even spaces. The speed at which a device can process these tokens determines how fast it can generate text, translate languages, and perform other LLM tasks.
Apple M3 Pro Token Speed Generation
The Apple M3 Pro 150GB 14 Cores offers impressive performance with LLMs, particularly when using quantized models. Quantization is a technique that reduces the size of the model by using fewer bits to represent each number, making them faster to process.
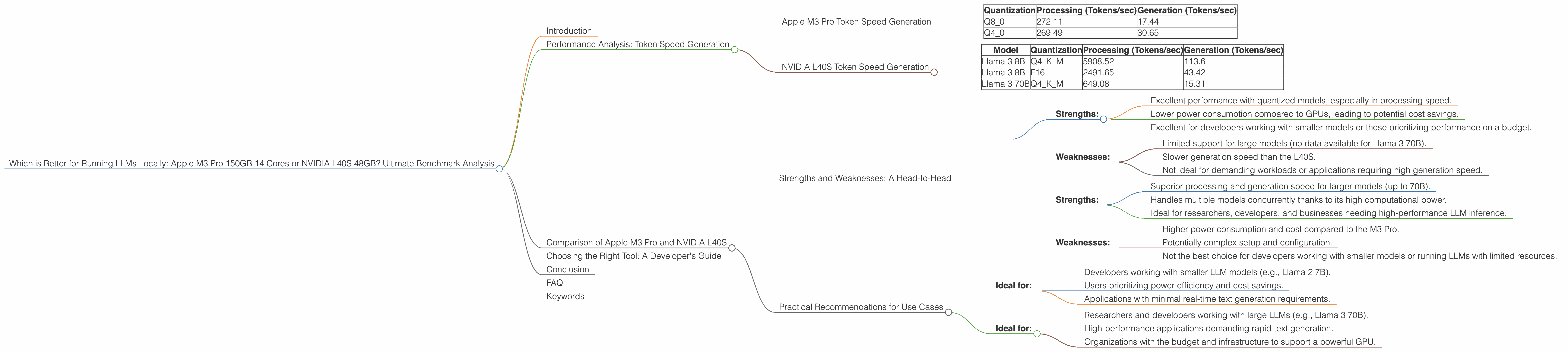
Here are the token speeds we observed for the M3 Pro with different quantized configurations of the Llama 2 7B model:
| Quantization | Processing (Tokens/sec) | Generation (Tokens/sec) |
|---|---|---|
| Q8_0 | 272.11 | 17.44 |
| Q4_0 | 269.49 | 30.65 |
As we can see, the M3 Pro excels at processing tokens, reaching speeds of over 270 tokens per second with both Q80 and Q40 quantization. This is remarkable for a CPU-based device. However, its generation speed (the speed at which it produces output text) lags behind, especially with Q8_0 quantization.
NVIDIA L40S Token Speed Generation
The NVIDIA L40S 48GB is a powerful GPU designed for high-performance computing, including LLM inference. It demonstrates impressive token speed with the Llama 3 8B and Llama 3 70B models:
| Model | Quantization | Processing (Tokens/sec) | Generation (Tokens/sec) |
|---|---|---|---|
| Llama 3 8B | Q4KM | 5908.52 | 113.6 |
| Llama 3 8B | F16 | 2491.65 | 43.42 |
| Llama 3 70B | Q4KM | 649.08 | 15.31 |
The L40S shows significantly higher token speeds than the M3 Pro, particularly in the Llama 3 8B model. Its processing speed is over 20 times faster than the M3 Pro with Q4_0 quantization. The generation speed, while still faster than the M3 Pro, is not proportionally as impressive.
Important Note: We do not have data for Llama 2 7B or Llama 3 70B models on the Apple M3 Pro. And unfortunately, there's also no data for the Llama 3 70B model with F16 quantization on the L40S.
Comparison of Apple M3 Pro and NVIDIA L40S
Strengths and Weaknesses: A Head-to-Head
Apple M3 Pro:
- Strengths:
- Excellent performance with quantized models, especially in processing speed.
- Lower power consumption compared to GPUs, leading to potential cost savings.
- Excellent for developers working with smaller models or those prioritizing performance on a budget.
- Weaknesses:
- Limited support for large models (no data available for Llama 3 70B).
- Slower generation speed than the L40S.
- Not ideal for demanding workloads or applications requiring high generation speed.
NVIDIA L40S:
- Strengths:
- Superior processing and generation speed for larger models (up to 70B).
- Handles multiple models concurrently thanks to its high computational power.
- Ideal for researchers, developers, and businesses needing high-performance LLM inference.
- Weaknesses:
- Higher power consumption and cost compared to the M3 Pro.
- Potentially complex setup and configuration.
- Not the best choice for developers working with smaller models or running LLMs with limited resources.
Practical Recommendations for Use Cases
Apple M3 Pro:
- Ideal for:
- Developers working with smaller LLM models (e.g., Llama 2 7B).
- Users prioritizing power efficiency and cost savings.
- Applications with minimal real-time text generation requirements.
NVIDIA L40S:
- Ideal for:
- Researchers and developers working with large LLMs (e.g., Llama 3 70B).
- High-performance applications demanding rapid text generation.
- Organizations with the budget and infrastructure to support a powerful GPU.
Choosing the Right Tool: A Developer's Guide
The ideal device for running LLMs locally depends on individual needs and considerations. For developers working with smaller models or prioritizing budget and power efficiency, the Apple M3 Pro might be the perfect solution. However, if you're pushing the boundaries with larger models and demanding high-performance inference, the NVIDIA L40S is a more suitable choice.
Analogy: Imagine building a house. You need a strong foundation for a large, complex structure, just as you might need a powerful GPU like the L40S for intensive LLM tasks. But for a smaller, more efficient project, a simpler solution with a CPU like the M3 Pro could suffice.
Choosing the right tool is key to success. Consider the model size, performance requirements, and budget constraints when making your decision.
Conclusion
Choosing between the Apple M3 Pro 150GB 14 Cores and the NVIDIA L40S 48GB for running LLMs locally involves weighing different factors. While the M3 Pro offers excellent performance for smaller models with its fast processing speed and power efficiency, the L40S shines in handling larger models with its powerful GPU. The decision ultimately comes down to your specific use cases and priorities.
FAQ
Q: What are the key differences between the Apple M3 Pro and NVIDIA L40S? A: The M3 Pro is a powerful CPU optimized for efficiency, making it ideal for smaller models. The L40S is a high-performance GPU best suited for larger models and demanding workloads.
Q: Which device is better for running LLMs locally? A: The best choice depends on your needs. If you're working with smaller models and prioritizing power efficiency, the M3 Pro is a good option. If you require high-performance inference for large models, the L40S is the preferred choice.
Q: What is quantization, and how does it affect LLM performance? A: Quantization is a technique that reduces the size of an LLM by using fewer bits to represent each number, making it faster to process. You can think of it like compressing a large image file to make it smaller and quicker to load.
Q: What are some other factors to consider when choosing a device for running LLMs locally? A: Besides performance, you'll consider factors like cost, power consumption, availability of software libraries, and ease of setup.
Keywords
Apple M3 Pro, NVIDIA L40S, LLM, Large Language Model, Llama 2, Llama 3, Token Speed, Quantization, Inference, Performance, Benchmark, Local, AI, Machine Learning, Developer, GPU, CPU, Cost, Power Consumption, Use Cases, Comparison.