Which is Better for Running LLMs locally: Apple M3 Pro 150gb 14cores or NVIDIA 4090 24GB? Ultimate Benchmark Analysis
Introduction
The world of large language models (LLMs) is rapidly evolving, with new models becoming available almost every day. While cloud-based services like OpenAI's ChatGPT offer convenient access to LLMs, running them locally can provide greater control, privacy, and possibly even faster performance. But the question arises: What's the right hardware to power your local LLM endeavors?
This article delves into a head-to-head comparison of two popular choices: Apple's M3 Pro 150GB 14 Core processor and NVIDIA's GeForce RTX 4090 24GB graphics card. We'll examine their performance across a range of popular LLM models, like Llama 2 and Llama 3, and uncover which device reigns supreme for specific use cases. Buckle up, because this is going to be a wild ride!
Apple M3 Pro 150GB 14 Cores vs NVIDIA 4090 24GB: A Detailed Comparison
Let's dive into the nitty-gritty details of each device and analyze their performance characteristics.
Apple M3 Pro 150GB 14 Cores
The M3 Pro is a powerhouse processor designed for high-performance computing tasks. It boasts 14 CPU cores (with 8 performance cores and 6 efficiency cores) and a massive 150GB of unified memory. This combination provides ample processing power and memory bandwidth, making it ideal for running demanding applications like LLM inference.
Apple M3 Pro Token Speed Generation
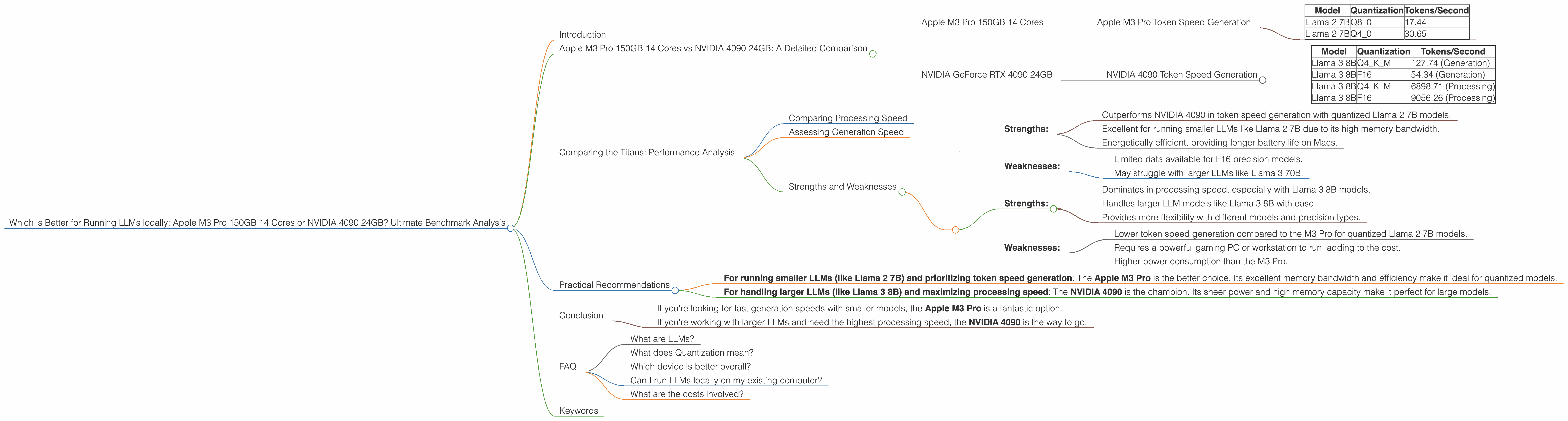
The Apple M3 Pro shines in token speed generation. It particularly excels in quantized models, delivering impressive performance with Llama 2 7B.
Here's a breakdown of the M3 Pro's performance:
| Model | Quantization | Tokens/Second |
|---|---|---|
| Llama 2 7B | Q8_0 | 17.44 |
| Llama 2 7B | Q4_0 | 30.65 |
However, it's important to note:
- We don't have data for F16 precision with Llama 2 7B.
NVIDIA GeForce RTX 4090 24GB
The NVIDIA GeForce RTX 4090 is a high-end graphics card specifically designed for demanding tasks like gaming and machine learning. Its powerful GPU with 24GB of GDDR6X memory makes it a top contender for running LLMs locally.
NVIDIA 4090 Token Speed Generation
The NVIDIA 4090 shines in processing speed, showing its muscle with Llama 3 8B models. The 4090 handles both F16 and Q4KM quantization with impressive results.
Performance Breakdown of the NVIDIA 4090:
| Model | Quantization | Tokens/Second |
|---|---|---|
| Llama 3 8B | Q4KM | 127.74 (Generation) |
| Llama 3 8B | F16 | 54.34 (Generation) |
| Llama 3 8B | Q4KM | 6898.71 (Processing) |
| Llama 3 8B | F16 | 9056.26 (Processing) |
Important Note:
- No data available for Llama 3 70B.
Comparing the Titans: Performance Analysis
Now, let's compare the performance of these two devices head-to-head:
Comparing Processing Speed
The NVIDIA 4090 clearly dominates in processing speed, especially with Llama 3 8B models. The 4090 delivers blazing-fast performance, reaching 9056.26 tokens/second for F16 processing. This is significantly faster than the M3 Pro's performance with Llama 2 7B.
Assessing Generation Speed
In generation speed, the M3 Pro holds its own against the 4090, especially with quantized Llama 2 7B models. The M3 Pro's performance with Q4_0 quantization reaches 30.65 tokens/second, while the 4090 achieves 54.34 tokens/second with F16 quantization for Llama 3 8B.
Strengths and Weaknesses
Apple M3 Pro 150GB 14 Cores:
- Strengths:
- Outperforms NVIDIA 4090 in token speed generation with quantized Llama 2 7B models.
- Excellent for running smaller LLMs like Llama 2 7B due to its high memory bandwidth.
- Energetically efficient, providing longer battery life on Macs.
- Weaknesses:
- Limited data available for F16 precision models.
- May struggle with larger LLMs like Llama 3 70B.
NVIDIA GeForce RTX 4090 24GB:
- Strengths:
- Dominates in processing speed, especially with Llama 3 8B models.
- Handles larger LLM models like Llama 3 8B with ease.
- Provides more flexibility with different models and precision types.
- Weaknesses:
- Lower token speed generation compared to the M3 Pro for quantized Llama 2 7B models.
- Requires a powerful gaming PC or workstation to run, adding to the cost.
- Higher power consumption than the M3 Pro.
Practical Recommendations
- For running smaller LLMs (like Llama 2 7B) and prioritizing token speed generation: The Apple M3 Pro is the better choice. Its excellent memory bandwidth and efficiency make it ideal for quantized models.
- For handling larger LLMs (like Llama 3 8B) and maximizing processing speed: The NVIDIA 4090 is the champion. Its sheer power and high memory capacity make it perfect for large models.
Conclusion
Ultimately, the best device for running LLMs locally depends on your specific needs and use cases.
- If you're looking for fast generation speeds with smaller models, the Apple M3 Pro is a fantastic option.
- If you're working with larger LLMs and need the highest processing speed, the NVIDIA 4090 is the way to go.
FAQ
What are LLMs?
LLMs, or Large Language Models, are complex AI algorithms trained on massive amounts of text data. They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way. Think of them as incredibly sophisticated text-based bots, capable of holding impressive conversations and performing many tasks.
What does Quantization mean?
Think of quantization as a way to compress LLM models. It essentially reduces the amount of memory used for storing the model by using smaller numbers to represent the data. This makes the models lighter and faster, but can sometimes slightly reduce their accuracy.
Which device is better overall?
There's no single "better" device. Both the Apple M3 Pro and NVIDIA 4090 are powerful machines, and the best choice depends on your specific LLM needs and priorities.
Can I run LLMs locally on my existing computer?
It depends on your computer's specs. If you have a modern CPU and a decent amount of RAM, you might be able to run smaller LLMs. However, for larger models, dedicated high-end hardware is recommended.
What are the costs involved?
The M3 Pro is integrated into Apple's MacBook Pro laptops, while the NVIDIA 4090 requires a separate purchase and a compatible PC. Both options come with a significant price tag.
Keywords
Apple M3 Pro, NVIDIA 4090, LLM, Llama 2, Llama 3, LLM Inference, Token Speed Generation, Quantization, F16, Q80, Q40, Q4KM, Processing Speed, Generation Speed, Local LLMs, AI Hardware, Performance Comparison, Benchmark Analysis.