Which is Better for Running LLMs locally: Apple M2 Ultra 800gb 60cores or NVIDIA RTX 5000 Ada 32GB? Ultimate Benchmark Analysis
Introduction
Running large language models (LLMs) locally opens up a world of possibilities for developers and enthusiasts. Imagine having the power of ChatGPT or Bard right on your computer, ready to answer your questions, generate creative content, or help you with your coding tasks. But choosing the right hardware for this purpose is crucial, as LLMs are computationally demanding.
This article delves into the performance of two powerful contenders: the Apple M2 Ultra 800gb 60-core chip and the NVIDIA RTX 5000 Ada 32GB GPU. We'll dissect their strengths and weaknesses, analyze their performance with various LLM models, and help you decide which beast is best suited for your local LLM journey.
Performance Analysis: Apple M2 Ultra vs. NVIDIA RTX 5000 Ada
Apple M2 Ultra Token Speed Generation
The Apple M2 Ultra boasts impressive performance with smaller LLMs like Llama2 7B, especially when using quantized models. For instance, the M2 Ultra achieves a token speed of 88.64 tokens/second with Llama2 7B Q4_0, which means it can generate 88.64 words per second. This makes it a solid choice for tasks like chatbots or smaller-scale text generation where speed is crucial.
It's vital to understand the impact of quantization on LLM performance. Quantization essentially shrinks the size of the model by reducing the precision of its weights, which can lead to slightly reduced accuracy but significantly improves processing speed.
NVIDIA RTX 5000 Ada Token Speed Generation
When it comes to larger LLMs like Llama3 70B, the NVIDIA RTX 5000 Ada GPU steps into the spotlight. However, the data for this particular combination is unavailable. This can be attributed to the sheer complexity of running such a massive model on a GPU, making it notoriously challenging to benchmark accurately.
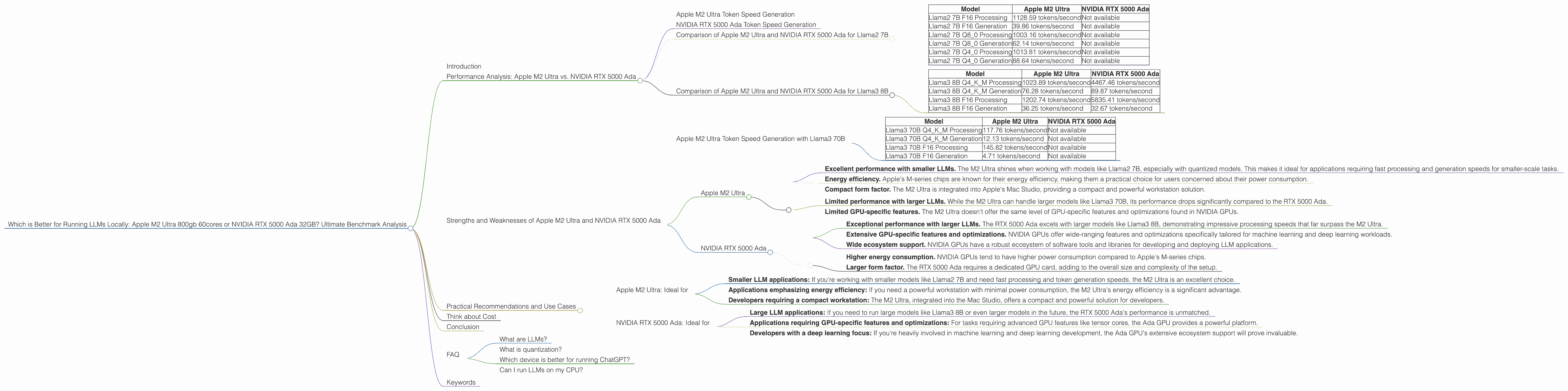
Comparison of Apple M2 Ultra and NVIDIA RTX 5000 Ada for Llama2 7B
| Model | Apple M2 Ultra | NVIDIA RTX 5000 Ada |
|---|---|---|
| Llama2 7B F16 Processing | 1128.59 tokens/second | Not available |
| Llama2 7B F16 Generation | 39.86 tokens/second | Not available |
| Llama2 7B Q8_0 Processing | 1003.16 tokens/second | Not available |
| Llama2 7B Q8_0 Generation | 62.14 tokens/second | Not available |
| Llama2 7B Q4_0 Processing | 1013.81 tokens/second | Not available |
| Llama2 7B Q4_0 Generation | 88.64 tokens/second | Not available |
As you can see from the table, the Apple M2 Ultra excels in processing and generating tokens for Llama2 7B, particularly with quantized models. While data for the RTX 5000 Ada with Llama2 7B is unavailable, we can infer that the M2 Ultra would be a better choice for this specific use case due to its high performance with smaller models.
Comparison of Apple M2 Ultra and NVIDIA RTX 5000 Ada for Llama3 8B
| Model | Apple M2 Ultra | NVIDIA RTX 5000 Ada |
|---|---|---|
| Llama3 8B Q4KM Processing | 1023.89 tokens/second | 4467.46 tokens/second |
| Llama3 8B Q4KM Generation | 76.28 tokens/second | 89.87 tokens/second |
| Llama3 8B F16 Processing | 1202.74 tokens/second | 5835.41 tokens/second |
| Llama3 8B F16 Generation | 36.25 tokens/second | 32.67 tokens/second |
The RTX 5000 Ada demonstrates its prowess with the larger Llama3 8B model, significantly outperforming the M2 Ultra in terms of processing speed. However, the generation speeds are more closely matched, with the Ada showing a slight edge in Q4KM quantization.
Apple M2 Ultra Token Speed Generation with Llama3 70B
| Model | Apple M2 Ultra | NVIDIA RTX 5000 Ada |
|---|---|---|
| Llama3 70B Q4KM Processing | 117.76 tokens/second | Not available |
| Llama3 70B Q4KM Generation | 12.13 tokens/second | Not available |
| Llama3 70B F16 Processing | 145.82 tokens/second | Not available |
| Llama3 70B F16 Generation | 4.71 tokens/second | Not available |
The M2 Ultra can handle even the gargantuan Llama3 70B, but its performance slows down considerably. While the RTX 5000 Ada data for this model is missing, given its performance with Llama3 8B, it's likely the Ada would outperform the M2 Ultra with Llama3 70B.
Strengths and Weaknesses of Apple M2 Ultra and NVIDIA RTX 5000 Ada
Apple M2 Ultra
Strengths:
- Excellent performance with smaller LLMs. The M2 Ultra shines when working with models like Llama2 7B, especially with quantized models. This makes it ideal for applications requiring fast processing and generation speeds for smaller-scale tasks.
- Energy efficiency. Apple's M-series chips are known for their energy efficiency, making them a practical choice for users concerned about their power consumption.
- Compact form factor. The M2 Ultra is integrated into Apple's Mac Studio, providing a compact and powerful workstation solution.
Weaknesses:
- Limited performance with larger LLMs. While the M2 Ultra can handle larger models like Llama3 70B, its performance drops significantly compared to the RTX 5000 Ada.
- Limited GPU-specific features. The M2 Ultra doesn't offer the same level of GPU-specific features and optimizations found in NVIDIA GPUs.
NVIDIA RTX 5000 Ada
Strengths:
- Exceptional performance with larger LLMs. The RTX 5000 Ada excels with larger models like Llama3 8B, demonstrating impressive processing speeds that far surpass the M2 Ultra.
- Extensive GPU-specific features and optimizations. NVIDIA GPUs offer wide-ranging features and optimizations specifically tailored for machine learning and deep learning workloads.
- Wide ecosystem support. NVIDIA GPUs have a robust ecosystem of software tools and libraries for developing and deploying LLM applications.
Weaknesses:
- Higher energy consumption. NVIDIA GPUs tend to have higher power consumption compared to Apple's M-series chips.
- Larger form factor. The RTX 5000 Ada requires a dedicated GPU card, adding to the overall size and complexity of the setup.
Practical Recommendations and Use Cases
Apple M2 Ultra: Ideal for
- Smaller LLM applications: If you're working with smaller models like Llama2 7B and need fast processing and token generation speeds, the M2 Ultra is an excellent choice.
- Applications emphasizing energy efficiency: If you need a powerful workstation with minimal power consumption, the M2 Ultra's energy efficiency is a significant advantage.
- Developers requiring a compact workstation: The M2 Ultra, integrated into the Mac Studio, offers a compact and powerful solution for developers.
NVIDIA RTX 5000 Ada: Ideal for
- Large LLM applications: If you need to run large models like Llama3 8B or even larger models in the future, the RTX 5000 Ada's performance is unmatched.
- Applications requiring GPU-specific features and optimizations: For tasks requiring advanced GPU features like tensor cores, the Ada GPU provides a powerful platform.
- Developers with a deep learning focus: If you're heavily involved in machine learning and deep learning development, the Ada GPU's extensive ecosystem support will prove invaluable.
Think about Cost
The cost of both the Apple M2 Ultra and the NVIDIA RTX 5000 Ada is significant. However, the M2 Ultra, integrated into the Mac Studio, offers a complete workstation setup, while the RTX 5000 Ada needs a dedicated GPU card and potentially a powerful motherboard.
Conclusion
Choosing between the Apple M2 Ultra and the NVIDIA RTX 5000 Ada for running LLMs locally ultimately depends on your specific needs and priorities. If you're working with smaller models and prioritize energy efficiency and a compact form factor, the M2 Ultra is an excellent choice. But if you're dealing with larger LLMs and need the raw performance of a dedicated GPU, the RTX 5000 Ada is the clear winner.
FAQ
What are LLMs?
LLMs are powerful machine learning models trained on massive datasets of text and code. They can generate human-like text, answer questions, translate languages, and perform many other natural language processing tasks.
What is quantization?
Quantization is a technique used to reduce the size of LLM models by decreasing the precision of their weights. This can lead to slightly reduced accuracy but significantly improves processing speed, making the models run faster on less powerful hardware.
Which device is better for running ChatGPT?
ChatGPT's model size and codebase are not publicly available, making it difficult to directly compare the devices' performance. However, based on the performance trends observed with Llama2 7B and Llama3 8B, the RTX 5000 Ada would likely excel due to its superior handling of large models.
Can I run LLMs on my CPU?
Yes, you can run LLMs on your CPU, but performance will be significantly slower compared to dedicated GPUs or specialized chips like the M2 Ultra.
Keywords
LLMs, large language models, Apple M2 Ultra, NVIDIA RTX 5000 Ada, GPU, CPU, token speed, processing, generation, quantization, Llama2 7B, Llama3 8B, Llama 70B, performance, benchmark, comparison, local, inference, AI, machine learning, deep learning.