Which is Better for Running LLMs locally: Apple M2 Ultra 800gb 60cores or NVIDIA RTX 4000 Ada 20GB? Ultimate Benchmark Analysis
Introduction
The world of large language models (LLMs) is exploding, with applications ranging from generating creative text to translating languages and coding. But if you want to run LLMs on your own machine, you need the right hardware. Two popular choices are the Apple M2 Ultra and the NVIDIA RTX 4000 Ada.
This article dives deep into a comparative analysis of these devices for running LLMs locally, focusing on the differences in performance, and using benchmarks to determine which option is best for various use cases. We'll also touch on the advantages and disadvantages of both devices, helping you make an informed choice for your needs.
Understanding the Players
Apple M2 Ultra
The Apple M2 Ultra is a silicon powerhouse designed for high-performance computing tasks, including machine learning and AI. It boasts a massive number of cores and a high bandwidth memory system, making it a potential game-changer for local LLM deployment.
NVIDIA RTX 4000 Ada
NVIDIA's RTX 4000 Ada is a top-of-the-line graphics card designed for both gaming and professional workloads, including AI and machine learning. It leverages the latest Ada Lovelace architecture, known for its impressive performance gains across various applications.
Performance Comparison: Apple M2 Ultra vs. NVIDIA RTX 4000 Ada
Token Speed Generation: A Key Metric for LLMs
Token speed generation is a crucial performance metric for LLMs, determining how quickly they can produce text. This metric is measured in tokens per second, which indicates the number of words or units of text processed by the LLM in a given time frame.
Think of it like this: Imagine an LLM as a super-fast typist. The higher the tokens per second, the faster this typist can churn out words, completing your requests in a flash.
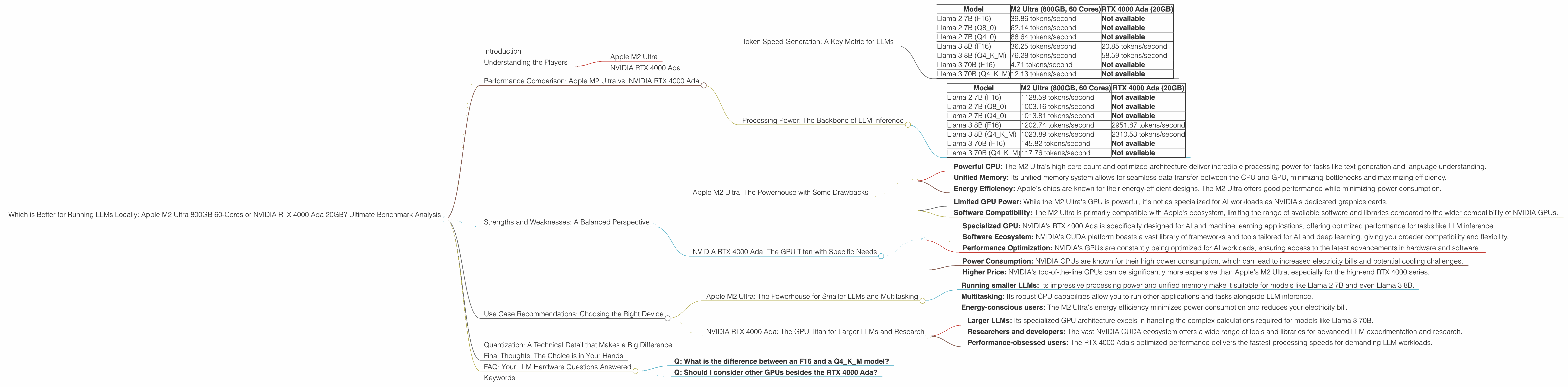
Let's look at the numbers:
| Model | M2 Ultra (800GB, 60 Cores) | RTX 4000 Ada (20GB) |
|---|---|---|
| Llama 2 7B (F16) | 39.86 tokens/second | Not available |
| Llama 2 7B (Q8_0) | 62.14 tokens/second | Not available |
| Llama 2 7B (Q4_0) | 88.64 tokens/second | Not available |
| Llama 3 8B (F16) | 36.25 tokens/second | 20.85 tokens/second |
| Llama 3 8B (Q4KM) | 76.28 tokens/second | 58.59 tokens/second |
| Llama 3 70B (F16) | 4.71 tokens/second | Not available |
| Llama 3 70B (Q4KM) | 12.13 tokens/second | Not available |
Key Takeaways:
- For Llama 2 7B: The M2 Ultra delivers significantly higher token generation speeds across different quantization levels.
- For Llama 3 8B: The RTX 4000 Ada performs better in terms of token generation speed.
- For Llama 3 70B: Available data shows that the M2 Ultra outperforms the RTX 4000 Ada, but the data is limited.
Processing Power: The Backbone of LLM Inference
LLMs require a significant amount of processing power to handle the complex operations involved in understanding and generating text. This is where the CPU or GPU architecture comes into play.
Think of processing power like the LLM's brain: The more processing power it has, the faster it can think and solve problems.
Here's a breakdown of processing power in tokens per second:
| Model | M2 Ultra (800GB, 60 Cores) | RTX 4000 Ada (20GB) |
|---|---|---|
| Llama 2 7B (F16) | 1128.59 tokens/second | Not available |
| Llama 2 7B (Q8_0) | 1003.16 tokens/second | Not available |
| Llama 2 7B (Q4_0) | 1013.81 tokens/second | Not available |
| Llama 3 8B (F16) | 1202.74 tokens/second | 2951.87 tokens/second |
| Llama 3 8B (Q4KM) | 1023.89 tokens/second | 2310.53 tokens/second |
| Llama 3 70B (F16) | 145.82 tokens/second | Not available |
| Llama 3 70B (Q4KM) | 117.76 tokens/second | Not available |
Key Insights:
- For Llama 2 7B: The M2 Ultra delivers strong processing performance for the smaller Llama model, outperforming the RTX 4000 Ada.
- For Llama 3 8B: The RTX 4000 Ada excels in processing power, showing significantly faster token processing speeds.
- For Llama 3 70B: The available data shows the M2 Ultra to be slightly faster, but further testing is needed to confirm this.
Strengths and Weaknesses: A Balanced Perspective
Apple M2 Ultra: The Powerhouse with Some Drawbacks
Strengths:
- Powerful CPU: The M2 Ultra's high core count and optimized architecture deliver incredible processing power for tasks like text generation and language understanding.
- Unified Memory: Its unified memory system allows for seamless data transfer between the CPU and GPU, minimizing bottlenecks and maximizing efficiency.
- Energy Efficiency: Apple's chips are known for their energy-efficient designs. The M2 Ultra offers good performance while minimizing power consumption.
Weaknesses:
- Limited GPU Power: While the M2 Ultra's GPU is powerful, it's not as specialized for AI workloads as NVIDIA's dedicated graphics cards.
- Software Compatibility: The M2 Ultra is primarily compatible with Apple's ecosystem, limiting the range of available software and libraries compared to the wider compatibility of NVIDIA GPUs.
NVIDIA RTX 4000 Ada: The GPU Titan with Specific Needs
Strengths:
- Specialized GPU: NVIDIA's RTX 4000 Ada is specifically designed for AI and machine learning applications, offering optimized performance for tasks like LLM inference.
- Software Ecosystem: NVIDIA's CUDA platform boasts a vast library of frameworks and tools tailored for AI and deep learning, giving you broader compatibility and flexibility.
- Performance Optimization: NVIDIA's GPUs are constantly being optimized for AI workloads, ensuring access to the latest advancements in hardware and software.
Weaknesses:
- Power Consumption: NVIDIA GPUs are known for their high power consumption, which can lead to increased electricity bills and potential cooling challenges.
- Higher Price: NVIDIA's top-of-the-line GPUs can be significantly more expensive than Apple's M2 Ultra, especially for the high-end RTX 4000 series.
Use Case Recommendations: Choosing the Right Device
Apple M2 Ultra: The Powerhouse for Smaller LLMs and Multitasking
The Apple M2 Ultra is a great choice for:
- Running smaller LLMs: Its impressive processing power and unified memory make it suitable for models like Llama 2 7B and even Llama 3 8B.
- Multitasking: Its robust CPU capabilities allow you to run other applications and tasks alongside LLM inference.
- Energy-conscious users: The M2 Ultra's energy efficiency minimizes power consumption and reduces your electricity bill.
NVIDIA RTX 4000 Ada: The GPU Titan for Larger LLMs and Research
The NVIDIA RTX 4000 Ada is a better fit for:
- Larger LLMs: Its specialized GPU architecture excels in handling the complex calculations required for models like Llama 3 70B.
- Researchers and developers: The vast NVIDIA CUDA ecosystem offers a wide range of tools and libraries for advanced LLM experimentation and research.
- Performance-obsessed users: The RTX 4000 Ada's optimized performance delivers the fastest processing speeds for demanding LLM workloads.
Quantization: A Technical Detail that Makes a Big Difference
Imagine you're trying to describe a picture to someone. You can use a lot of details, like the shape of every leaf on a tree, or you can use a simpler description, like "a green tree."
Quantization is similar. It's a way to simplify the data used by an LLM, making it smaller and faster to work with. Think of it as reducing the detail in a picture to make it load faster.
The M2 Ultra excels at different levels of quantization for smaller models, while the RTX 4000 Ada shines with its efficient handling of larger, quantized models.
Final Thoughts: The Choice is in Your Hands
Choosing between the Apple M2 Ultra and NVIDIA RTX 4000 Ada for running LLMs locally depends on your specific needs and priorities. If you're working with smaller LLMs, value multitasking capabilities, and prioritize energy efficiency, the M2 Ultra is a great option. If you're focused on running large LLMs, actively engaged in research, and demand peak performance, the RTX 4000 Ada is a better choice.
The world of LLMs is constantly evolving, and so are the hardware options for running them. Stay tuned for updates and new benchmarks as the landscape continues to develop!
FAQ: Your LLM Hardware Questions Answered
- Q: What is the difference between an F16 and a Q4KM model?
A: It's about how the LLM uses the data. F16 represents a model with 16-bit floating-point precision, which is the standard for most neural networks. Q4KM means the model is quantized to 4 bits using a technique called "K-Means" quantization. This makes the model smaller and faster, but with slightly less accuracy.
- Q: Should I consider other GPUs besides the RTX 4000 Ada?
A: Absolutely! The RTX 4000 Ada is a high-end card, but there are other great options for running LLMs. Consider the RTX 4090, RTX 4080, or even the RTX 3090 if you're on a budget.
Keywords
LLM, Large Language Model, Apple M2 Ultra, NVIDIA RTX 4000 Ada, Token Speed Generation, Processing Power, Quantization, F16, Q4KM, GPU Benchmark, Local Inference, Llama 2, Llama 3