Which is Better for Running LLMs locally: Apple M2 Max 400gb 30cores or NVIDIA RTX A6000 48GB? Ultimate Benchmark Analysis
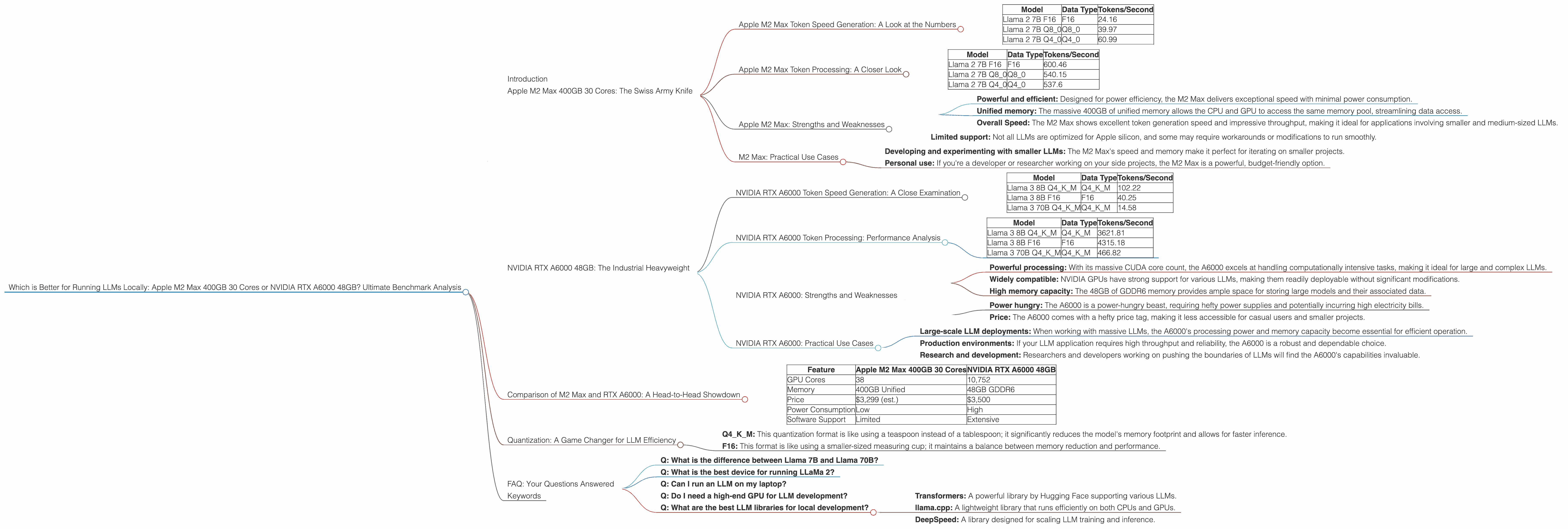
Introduction
The world of large language models (LLMs) is booming, and everyone wants to experience their magic firsthand. But running these powerful models on your own machine can be a challenge. Two titans in the hardware world, Apple's M2 Max and NVIDIA's RTX A6000, are vying for the top spot in local LLM performance. This article will dissect their capabilities, comparing their strengths and weaknesses, and offering practical recommendations for your specific use case.
Imagine you're trying to fit a massive jigsaw puzzle. You have two different tools: a powerful handheld jigsaw saw and a robust stationary table saw. Each boasts its own benefits, but which one is better for the task? This article is your guide to understanding which tool is best suited for your LLM puzzles.
Apple M2 Max 400GB 30 Cores: The Swiss Army Knife
The Apple M2 Max packs a punch with its massive 38-core GPU and 400GB of unified memory. This makes it a compelling force for running LLMs locally, particularly when dealing with smaller models and even some medium-sized ones. But is it truly a heavyweight contender? Let's dive in.
Apple M2 Max Token Speed Generation: A Look at the Numbers
The M2 Max, with its impressive core count, shines in token generation.
| Model | Data Type | Tokens/Second |
|---|---|---|
| Llama 2 7B F16 | F16 | 24.16 |
| Llama 2 7B Q8_0 | Q8_0 | 39.97 |
| Llama 2 7B Q4_0 | Q4_0 | 60.99 |
For context, token generation is the process of turning text into a series of numbers that the LLM can understand. This is a crucial part of the LLM's operation.
Apple M2 Max Token Processing: A Closer Look
Where the M2 Max really shines is with its processing power. Imagine your LLM as a high-speed train; processing is the engine, and token generation is the train's ability to pick up passengers (tokens) along the way.
| Model | Data Type | Tokens/Second |
|---|---|---|
| Llama 2 7B F16 | F16 | 600.46 |
| Llama 2 7B Q8_0 | Q8_0 | 540.15 |
| Llama 2 7B Q4_0 | Q4_0 | 537.6 |
These numbers reveal that the M2 Max is a true speed demon when it comes to processing tokens, which is essential for generating outputs and powering the LLM's reasoning.
Apple M2 Max: Strengths and Weaknesses
Strengths:
- Powerful and efficient: Designed for power efficiency, the M2 Max delivers exceptional speed with minimal power consumption.
- Unified memory: The massive 400GB of unified memory allows the CPU and GPU to access the same memory pool, streamlining data access.
- Overall Speed: The M2 Max shows excellent token generation speed and impressive throughput, making it ideal for applications involving smaller and medium-sized LLMs.
Weaknesses:
- Limited support: Not all LLMs are optimized for Apple silicon, and some may require workarounds or modifications to run smoothly.
M2 Max: Practical Use Cases
The Apple M2 Max shines brightly in the following scenarios:
- Developing and experimenting with smaller LLMs: The M2 Max's speed and memory make it perfect for iterating on smaller projects.
- Personal use: If you're a developer or researcher working on your side projects, the M2 Max is a powerful, budget-friendly option.
NVIDIA RTX A6000 48GB: The Industrial Heavyweight
The NVIDIA RTX A6000 is a powerhouse designed for professional workloads, boasting 48GB of GDDR6 memory and a whopping 10,752 CUDA cores. It's a true champion in the world of high-performance computing, and its capabilities are impressive even for the most demanding LLMs.
NVIDIA RTX A6000 Token Speed Generation: A Close Examination
The A6000's power is evident in its ability to generate tokens, especially for larger models:
| Model | Data Type | Tokens/Second |
|---|---|---|
| Llama 3 8B Q4KM | Q4KM | 102.22 |
| Llama 3 8B F16 | F16 | 40.25 |
| Llama 3 70B Q4KM | Q4KM | 14.58 |
This demonstrates that the A6000 excels at generating tokens for larger models, making it a strong contender for more advanced applications.
NVIDIA RTX A6000 Token Processing: Performance Analysis
The A6000 sets a new standard for token processing as well:
| Model | Data Type | Tokens/Second |
|---|---|---|
| Llama 3 8B Q4KM | Q4KM | 3621.81 |
| Llama 3 8B F16 | F16 | 4315.18 |
| Llama 3 70B Q4KM | Q4KM | 466.82 |
Its processing power is unparalleled, enabling it to handle vast amounts of data efficiently.
NVIDIA RTX A6000: Strengths and Weaknesses
Strengths:
- Powerful processing: With its massive CUDA core count, the A6000 excels at handling computationally intensive tasks, making it ideal for large and complex LLMs.
- Widely compatible: NVIDIA GPUs have strong support for various LLMs, making them readily deployable without significant modifications.
- High memory capacity: The 48GB of GDDR6 memory provides ample space for storing large models and their associated data.
Weaknesses:
- Power hungry: The A6000 is a power-hungry beast, requiring hefty power supplies and potentially incurring high electricity bills.
- Price: The A6000 comes with a hefty price tag, making it less accessible for casual users and smaller projects.
NVIDIA RTX A6000: Practical Use Cases
The NVIDIA RTX A6000 is best suited for:
- Large-scale LLM deployments: When working with massive LLMs, the A6000's processing power and memory capacity become essential for efficient operation.
- Production environments: If your LLM application requires high throughput and reliability, the A6000 is a robust and dependable choice.
- Research and development: Researchers and developers working on pushing the boundaries of LLMs will find the A6000's capabilities invaluable.
Comparison of M2 Max and RTX A6000: A Head-to-Head Showdown
Now that we've examined each device, let's pit them against each other to see how they measure up:
| Feature | Apple M2 Max 400GB 30 Cores | NVIDIA RTX A6000 48GB |
|---|---|---|
| GPU Cores | 38 | 10,752 |
| Memory | 400GB Unified | 48GB GDDR6 |
| Price | $3,299 (est.) | $3,500 |
| Power Consumption | Low | High |
| Software Support | Limited | Extensive |
Token Speed Generation:
- Smaller LLMs: M2 Max is faster for smaller models like Llama 2 7B.
- Larger LLMs: A6000 takes the lead with its ability to handle larger models like Llama 3 8B and Llama 3 70B.
Token Processing:
- Overall: A6000 reigns supreme with its sheer processing horsepower, showcasing its capabilities even with larger models.
Practical Considerations:
- Budget: The M2 Max offers a more affordable option, while the A6000 is a significant investment.
- Power consumption: The M2 Max consumes less power, while the A6000 requires a heavy-duty power supply.
- Software support: The A6000 offers wider compatibility with various LLM software and frameworks.
Conclusion:
The choice between the M2 Max and the RTX A6000 ultimately hinges on your specific needs and priorities. If you're dealing with smaller LLMs or focusing on cost-effectiveness, the M2 Max is a compelling choice. However, if your work involves larger models, demanding workloads, or you prioritize software compatibility, the RTX A6000 is the clear winner.
Quantization: A Game Changer for LLM Efficiency
Quantization, which is like reducing the size of a large recipe by using smaller ingredients without changing the taste too much, is a key technique for scaling LLMs. It compresses the model's weights, allowing it to run more efficiently on devices with limited memory.
- Q4KM: This quantization format is like using a teaspoon instead of a tablespoon; it significantly reduces the model's memory footprint and allows for faster inference.
- F16: This format is like using a smaller-sized measuring cup; it maintains a balance between memory reduction and performance.
FAQ: Your Questions Answered
Q: What is the difference between Llama 7B and Llama 70B?
A: The numbers (7B and 70B) represent the size of the LLM, measured in billions of parameters. A larger model, like Llama 70B, typically has a greater understanding of language and can generate more complex and nuanced responses.
Q: What is the best device for running LLaMa 2?
A: For Llama 2 7B, the Apple M2 Max is a solid choice due to its speed and memory efficiency. However, for larger Llama 2 models, the NVIDIA RTX A6000 is recommended for its processing power and wider software compatibility.
Q: Can I run an LLM on my laptop?
A: Yes, you can run smaller LLMs on your laptop if it has a powerful GPU. However, for larger LLMs, a dedicated GPU like the RTX A6000 is typically required.
Q: Do I need a high-end GPU for LLM development?
A: While a good GPU is helpful, it's more important to choose a device that balances performance with your budget. If you are just starting out with LLM development, you can experiment with smaller models on your laptop's GPU.
Q: What are the best LLM libraries for local development?
A: Popular libraries for local LLM development include:
- Transformers: A powerful library by Hugging Face supporting various LLMs.
- llama.cpp: A lightweight library that runs efficiently on both CPUs and GPUs.
- DeepSpeed: A library designed for scaling LLM training and inference.
Keywords
LLMs, Large Language Models, Apple M2 Max, NVIDIA RTX A6000, Token Generation, Token Processing, Quantization, Q4KM, F16, Inference, Performance Comparison, Local LLM Development, Transformers, llama.cpp, DeepSpeed, GPU, GPU Benchmarks, CUDA, Unified Memory, GDDR6, Llama 2 7B, Llama 3 8B, Llama 3 70B, Parameters, Memory Footprint, Speed, Efficiency, Cost-effective, Power Consumption, Software Support.