Which is Better for Running LLMs locally: Apple M2 Max 400gb 30cores or NVIDIA A100 PCIe 80GB? Ultimate Benchmark Analysis
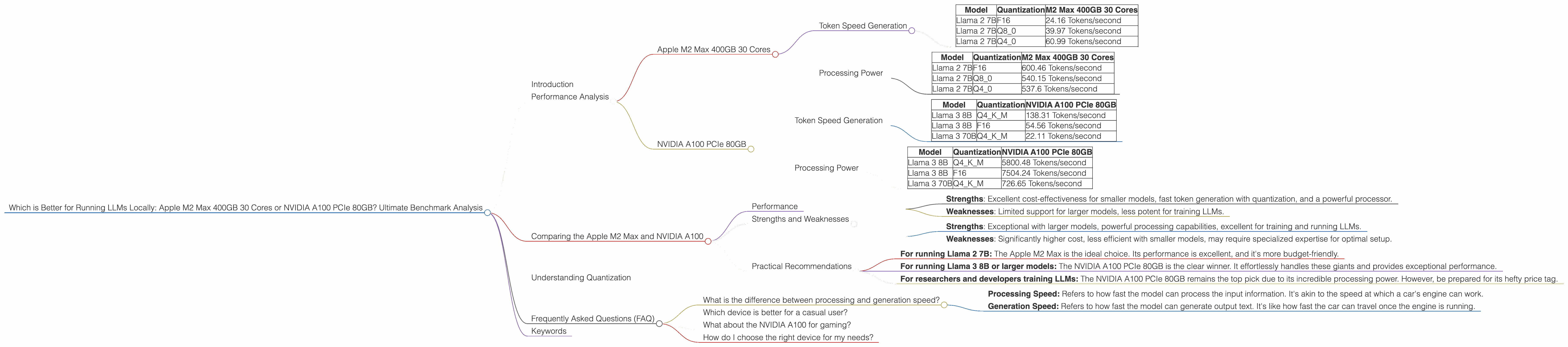
Introduction
The world of Large Language Models (LLMs) is exploding, with new advancements happening daily. These models allow us to interact with computers in ways never before imagined; they can write poems, translate languages, write code, and even answer complex questions. But the power to run these LLMs often comes with demanding hardware requirements.
This article delves into the head-to-head comparison of two powerful devices: the Apple M2 Max 400GB 30 Cores and the NVIDIA A100 PCIe 80GB. We'll examine their performance running popular LLM models, provide insights into their strengths and weaknesses, and ultimately help you decide which device best suits your needs.
Performance Analysis
Apple M2 Max 400GB 30 Cores
The Apple M2 Max boasts impressive performance, especially when using the optimized llama.cpp library. It shows great capabilities handling Llama 2 models, making it a compelling choice for those working with these models.
Token Speed Generation
| Model | Quantization | M2 Max 400GB 30 Cores |
|---|---|---|
| Llama 2 7B | F16 | 24.16 Tokens/second |
| Llama 2 7B | Q8_0 | 39.97 Tokens/second |
| Llama 2 7B | Q4_0 | 60.99 Tokens/second |
Let's break down these numbers. The M2 Max excels at generating tokens when utilizing quantized models. For example, the Q4_0 quantized version of Llama 2 7B achieves a remarkable 60.99 tokens per second. That's pretty impressive, right? It's like the M2 Max is spitting out text at lightning speed compared to other devices.
Processing Power
| Model | Quantization | M2 Max 400GB 30 Cores |
|---|---|---|
| Llama 2 7B | F16 | 600.46 Tokens/second |
| Llama 2 7B | Q8_0 | 540.15 Tokens/second |
| Llama 2 7B | Q4_0 | 537.6 Tokens/second |
When it comes to processing power, the M2 Max also shines. It handles the Llama 2 7B models, even in F16 format, at a blazing speed. It's like a computational powerhouse, crunching through the model's calculations in a blink of an eye.
NVIDIA A100 PCIe 80GB
The NVIDIA A100 PCIe 80GB is a powerhouse in the world of GPUs. It's not just a chip; it's a beast designed for high-performance computing tasks, including training and running LLMs.
Token Speed Generation
| Model | Quantization | NVIDIA A100 PCIe 80GB |
|---|---|---|
| Llama 3 8B | Q4KM | 138.31 Tokens/second |
| Llama 3 8B | F16 | 54.56 Tokens/second |
| Llama 3 70B | Q4KM | 22.11 Tokens/second |
The A100 excels at generating tokens when running larger models. For example, the Llama 3 8B model with Q4KM quantization achieves a remarkable 138.31 tokens per second. It's a testament to the A100's power handling these intricate models.
Processing Power
| Model | Quantization | NVIDIA A100 PCIe 80GB |
|---|---|---|
| Llama 3 8B | Q4KM | 5800.48 Tokens/second |
| Llama 3 8B | F16 | 7504.24 Tokens/second |
| Llama 3 70B | Q4KM | 726.65 Tokens/second |
The A100 is a processing powerhouse. It handles even the massive Llama 3 70B model with Q4KM quantization with impressive speed. Let's put it this way: The A100 is like a turbocharged engine, tackling complex computations with ease.
Comparing the Apple M2 Max and NVIDIA A100
Performance
The Apple M2 Max shines when working with smaller models like Llama 2 7B, especially with quantized versions. It's a great option for those seeking a balance between performance and affordability. The NVIDIA A100, on the other hand, is the undisputed champion when it comes to running larger models like Llama 3 8B and even the massive 70B models. It's a true powerhouse for those pushing the boundaries of LLM operations.
Strengths and Weaknesses
Apple M2 Max
- Strengths: Excellent cost-effectiveness for smaller models, fast token generation with quantization, and a powerful processor.
- Weaknesses: Limited support for larger models, less potent for training LLMs.
NVIDIA A100 PCIe 80GB
- Strengths: Exceptional with larger models, powerful processing capabilities, excellent for training and running LLMs.
- Weaknesses: Significantly higher cost, less efficient with smaller models, may require specialized expertise for optimal setup.
Practical Recommendations
- For running Llama 2 7B: The Apple M2 Max is the ideal choice. Its performance is excellent, and it's more budget-friendly.
- For running Llama 3 8B or larger models: The NVIDIA A100 PCIe 80GB is the clear winner. It effortlessly handles these giants and provides exceptional performance.
- For researchers and developers training LLMs: The NVIDIA A100 PCIe 80GB remains the top pick due to its incredible processing power. However, be prepared for its hefty price tag.
Understanding Quantization
Quantization is a technique used to reduce the size of LLM models by representing the model's parameters with fewer bits. It's like taking a high-resolution image and compressing it into a smaller file size without significantly sacrificing quality. This process makes the models faster and more memory-efficient, especially on devices with limited resources.
Think of it like this: Instead of storing each number with 32 bits, you can represent them with 8 bits or even just 4 bits, significantly reducing the memory footprint. This allows you to run larger models on less powerful machines or achieve a significant speed boost.
Frequently Asked Questions (FAQ)
What is the difference between processing and generation speed?
- Processing Speed: Refers to how fast the model can process the input information. It's akin to the speed at which a car's engine can work.
- Generation Speed: Refers to how fast the model can generate output text. It's like how fast the car can travel once the engine is running.
Which device is better for a casual user?
For a casual user, the Apple M2 Max 400GB 30 Cores is a fantastic choice. It's more affordable and offers excellent performance for smaller models like Llama 2 7B.
What about the NVIDIA A100 for gaming?
The NVIDIA A100 is a powerful GPU but not specifically designed for gaming. It's geared towards high-performance computing tasks like LLM processing and training. Dedicated gaming GPUs like the RTX 4090 would be better suited for gaming purposes.
How do I choose the right device for my needs?
Consider the size of the models you'll be running, your budget, and your overall computing needs. If you're working with smaller models and prioritize affordability, the Apple M2 Max is an excellent option. However, if you need to handle large models or train your LLMs, the NVIDIA A100 PCIe 80GB is the superior choice despite its higher cost.
Keywords
Large Language Models, LLM, Apple M2 Max, NVIDIA A100 PCIe 80GB, llama.cpp, Llama 2, Llama 3, Token Speed, Processing Speed, Quantization, F16, Q80, Q40, Q4KM, Performance Analysis, Benchmark, Deep Learning, Machine Learning, GPU, CPU, AI, Natural Language Processing, NLP, Inference, Training, Cost-Effectiveness