Which is Better for Running LLMs locally: Apple M2 Max 400gb 30cores or NVIDIA 3080 Ti 12GB? Ultimate Benchmark Analysis
Introduction
The world of Large Language Models (LLMs) is booming, and with it comes the urge to run these powerful AI models locally. But with so many different hardware options, it's tough to know which one will give you the best performance. Today, we'll dive into the performance of two popular choices for running LLMs locally: the Apple M2 Max 400gb 30cores and the NVIDIA 3080 Ti 12GB. We'll compare their strengths and weaknesses, and provide practical recommendations for which one is best suited for your use cases.
Imagine you're a developer trying to build a new AI-powered application, or you're just a tech-savvy person who wants to explore the capabilities of LLMs. The first question you might ask is: "Where do I run these models?" The answer, of course, depends on your needs and your budget. But for this article, we're focusing on running LLMs locally, as it offers flexibility, privacy, and control over your data.
Comparing the M2 Max and the 3080 Ti for Local LLMs
It's like choosing between a sleek, fast sports car (M2 Max) designed for a smooth and efficient ride, and a powerful, rugged off-road vehicle (3080 Ti) capable of handling tough terrain. Both have their strengths, and it all comes down to your needs and what you want to achieve.
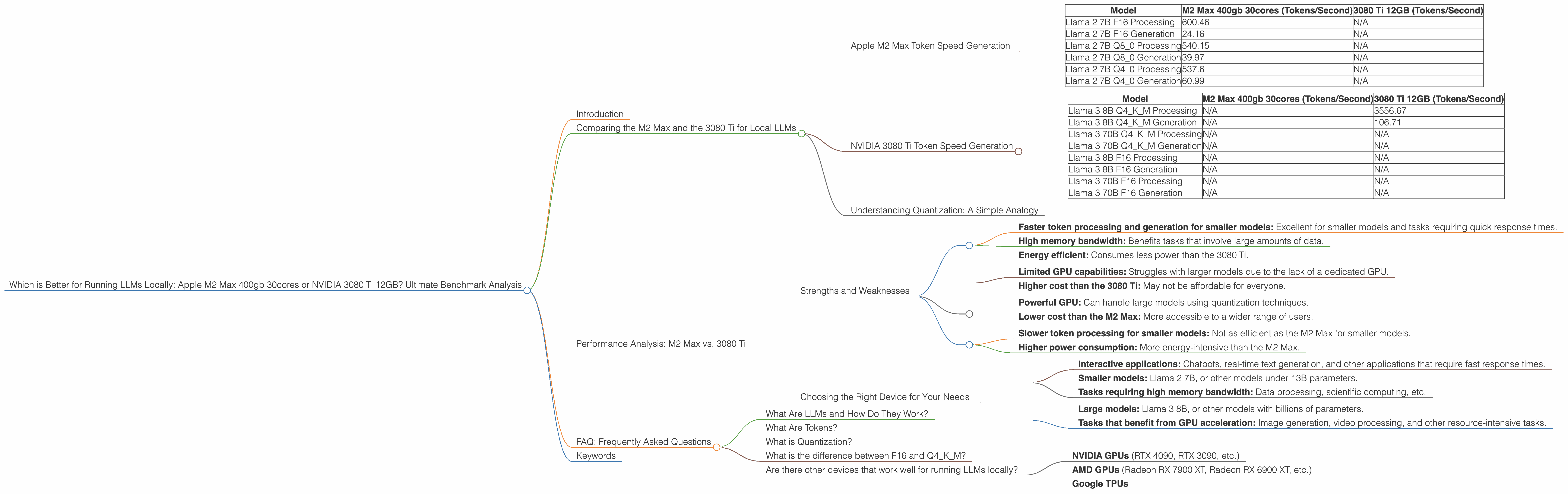
Apple M2 Max Token Speed Generation
Imagine tokens as the building blocks of language. One of the key metrics for evaluating LLM performance is the token speed, which is the number of tokens a device can process per second.
| Model | M2 Max 400gb 30cores (Tokens/Second) | 3080 Ti 12GB (Tokens/Second) |
|---|---|---|
| Llama 2 7B F16 Processing | 600.46 | N/A |
| Llama 2 7B F16 Generation | 24.16 | N/A |
| Llama 2 7B Q8_0 Processing | 540.15 | N/A |
| Llama 2 7B Q8_0 Generation | 39.97 | N/A |
| Llama 2 7B Q4_0 Processing | 537.6 | N/A |
| Llama 2 7B Q4_0 Generation | 60.99 | N/A |
- N/A: We lack data for the 3080 Ti 12GB for Llama 2 7B.
The M2 Max shines in this regard, excelling in processing and generating tokens, especially when using smaller models like Llama 2 7B. Its high-performance CPU architecture and optimized memory bandwidth contribute to its speed, making it ideal for tasks requiring quick response times, like interactive chatbots or real-time text generation.
However, the M2 Max doesn't have dedicated GPUs, which can be a drawback for larger models.
NVIDIA 3080 Ti Token Speed Generation
The 3080 Ti, with its dedicated NVIDIA CUDA cores, is designed to handle more demanding tasks, especially when it comes to larger models.
| Model | M2 Max 400gb 30cores (Tokens/Second) | 3080 Ti 12GB (Tokens/Second) |
|---|---|---|
| Llama 3 8B Q4KM Processing | N/A | 3556.67 |
| Llama 3 8B Q4KM Generation | N/A | 106.71 |
| Llama 3 70B Q4KM Processing | N/A | N/A |
| Llama 3 70B Q4KM Generation | N/A | N/A |
| Llama 3 8B F16 Processing | N/A | N/A |
| Llama 3 8B F16 Generation | N/A | N/A |
| Llama 3 70B F16 Processing | N/A | N/A |
| Llama 3 70B F16 Generation | N/A | N/A |
- N/A: We lack data for the M2 Max 400gb 30cores for Llama 3 8B and Llama 3 70B and for the 3080 Ti 12GB for Llama 3 70B and for both devices for models using F16 precision.
The 3080 Ti excels in processing large models with quantization techniques, like Q4KM. Quantization is like reducing the size of a model without sacrificing too much accuracy, and it's particularly helpful for running larger models on devices with limited memory.
Understanding Quantization: A Simple Analogy
Think of quantization like compressing a large file. You can shrink it down without losing too much detail. In this case, it's like making a model smaller to fit into a device with less memory. Q4KM is a type of quantization that uses 4 bits to represent a value, which can significantly reduce the model's memory footprint and improve performance.
Performance Analysis: M2 Max vs. 3080 Ti
The M2 Max seems to have a clear advantage in performance when running smaller models like Llama 2 7B. However, when it comes to larger models, the 3080 Ti takes the lead, especially when using techniques like quantization.
Strengths and Weaknesses
Apple M2 Max 400gb 30cores:
Strengths: * Faster token processing and generation for smaller models: Excellent for smaller models and tasks requiring quick response times. * High memory bandwidth: Benefits tasks that involve large amounts of data. * Energy efficient: Consumes less power than the 3080 Ti.
Weaknesses: * Limited GPU capabilities: Struggles with larger models due to the lack of a dedicated GPU. * Higher cost than the 3080 Ti: May not be affordable for everyone.
NVIDIA 3080 Ti 12GB:
Strengths: * Powerful GPU: Can handle large models using quantization techniques. * Lower cost than the M2 Max: More accessible to a wider range of users.
Weaknesses: * Slower token processing for smaller models: Not as efficient as the M2 Max for smaller models. * Higher power consumption: More energy-intensive than the M2 Max.
Choosing the Right Device for Your Needs
Use the M2 Max for:
- Interactive applications: Chatbots, real-time text generation, and other applications that require fast response times.
- Smaller models: Llama 2 7B, or other models under 13B parameters.
- Tasks requiring high memory bandwidth: Data processing, scientific computing, etc.
Use the 3080 Ti for:
- Large models: Llama 3 8B, or other models with billions of parameters.
- Tasks that benefit from GPU acceleration: Image generation, video processing, and other resource-intensive tasks.
FAQ: Frequently Asked Questions
What Are LLMs and How Do They Work?
LLMs are powerful AI models trained on massive datasets of text and code. They can understand and generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way. They work by learning patterns and relationships between words, which allows them to generate coherent and contextually relevant text.
What Are Tokens?
Tokens are like the individual building blocks of language. Imagine them as the words or parts of words that a language model uses to create an output. When you type a sentence, the model breaks it down into tokens to understand its meaning.
What is Quantization?
Quantization is a technique used to reduce the size of an LLM model without losing significant accuracy. It's like compressing a large file—you can make it smaller without taking away too much detail. The smaller size allows you to run the model on devices with less memory, improving performance.
What is the difference between F16 and Q4KM?
F16 refers to the precision used to represent numbers in the LLM. It uses 16 bits to represent a number, while Q4KM uses only 4 bits. Q4KM is a quantization technique that reduces the model's size and memory footprint.
Are there other devices that work well for running LLMs locally?
Yes, there are several other devices that can be used for running LLMs locally. These include:
- NVIDIA GPUs (RTX 4090, RTX 3090, etc.)
- AMD GPUs (Radeon RX 7900 XT, Radeon RX 6900 XT, etc.)
- Google TPUs
Keywords
LLMs, Large Language Models, M2 Max, NVIDIA 3080 Ti, token speed, quantization, Q4KM, processing, generation, performance, benchmark, comparison, Apple, NVIDIA, local, inference, AI, models, GPU, CPU, memory bandwidth, energy efficient, power consumption, use cases