Which is Better for Running LLMs locally: Apple M2 100gb 10cores or NVIDIA 3090 24GB? Ultimate Benchmark Analysis
Introduction
The world of Large Language Models (LLMs) is booming, and running these powerful AI models locally is becoming increasingly popular. This opens doors to faster response times, improved privacy, and the ability to experiment with custom models. But choosing the right hardware for this task can be a daunting challenge.
In this comprehensive analysis, we'll delve into the performance of two popular contenders: the Apple M2 chip with 100GB of RAM and 10 cores, and the NVIDIA GeForce RTX 3090 with 24GB of GDDR6X memory. Using real-world benchmark data, we'll dissect their strengths and weaknesses, providing you with the insights to make an informed decision for your LLM needs.
Comparing Apple M2 and NVIDIA 3090 for LLM Performance
Both the Apple M2 and NVIDIA 3090 are powerhouses in their own right, each boasting unique characteristics that make them suitable for different aspects of LLM work. We'll break down their performance across several crucial metrics, highlighting their strengths and weaknesses:
Apple M2 Token Speed Generation
The Apple M2 chip is known for its impressive performance in general-purpose computing and its high memory bandwidth. This translates to faster token generation, which is crucial for conversational AI applications and real-time interactions with LLMs.
Let's look at the numbers:
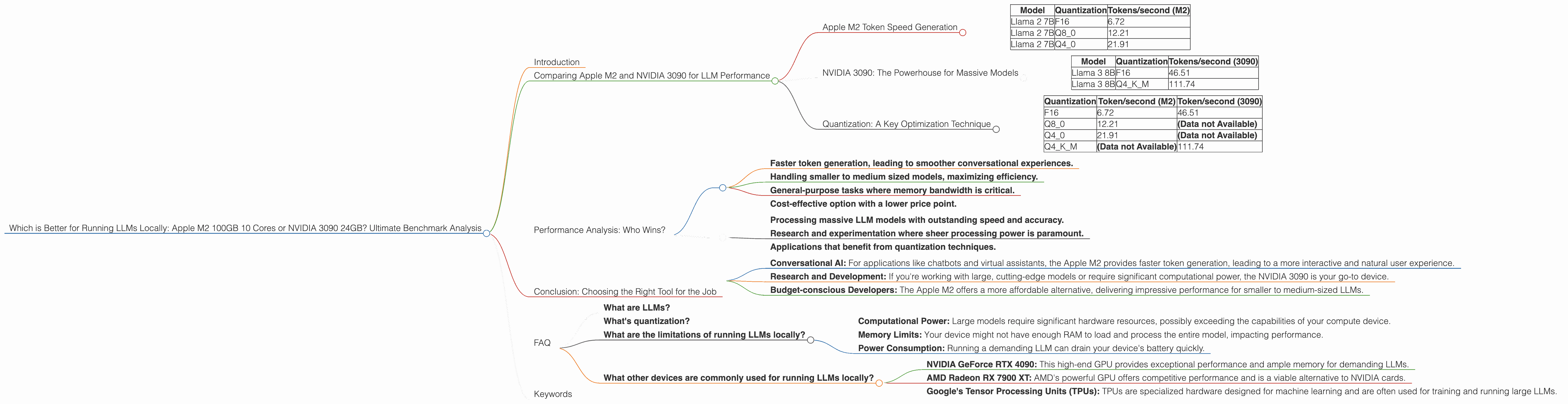
| Model | Quantization | Tokens/second (M2) |
|---|---|---|
| Llama 2 7B | F16 | 6.72 |
| Llama 2 7B | Q8_0 | 12.21 |
| Llama 2 7B | Q4_0 | 21.91 |
Key Takeaways:
- Faster Token Generation: The Apple M2 excels in token generation speeds, especially with quantization techniques like Q4_0, which significantly boost performance without a noticeable dip in accuracy.
- Efficient Memory Usage: The 100GB RAM allows the Apple M2 to load and process larger models efficiently, unlike the 24GB on the NVIDIA 3090.
NVIDIA 3090: The Powerhouse for Massive Models
While the M2 shines in token generation, the NVIDIA 3090 takes the crown for its prowess in processing large, complex models. Its powerful GPU hardware enables blazing-fast inference speeds, making it ideal for tasks like research and development where computational efficiency is paramount.
| Model | Quantization | Tokens/second (3090) |
|---|---|---|
| Llama 3 8B | F16 | 46.51 |
| Llama 3 8B | Q4KM | 111.74 |
Key Takeaways:
- Optimized for Large Models: The NVIDIA 3090 excels in handling massive LLM models like Llama 3 70B, which are computationally demanding and require high processing power.
- Limited Memory: The 24GB of memory restricts the NVIDIA 3090's ability to efficiently handle extremely large models, making it less suitable for certain applications.
Quantization: A Key Optimization Technique
Quantization is a technique that reduces the precision of model weights, enabling significant performance gains while minimizing accuracy loss. Both the Apple M2 and NVIDIA 3090 support quantization, but the NVIDIA 3090 often shows a more pronounced performance boost due to its dedicated GPU architecture.
Let's visualize the impact of quantization on Llama 2 7B:
| Quantization | Token/second (M2) | Token/second (3090) |
|---|---|---|
| F16 | 6.72 | 46.51 |
| Q8_0 | 12.21 | (Data not Available) |
| Q4_0 | 21.91 | (Data not Available) |
| Q4KM | (Data not Available) | 111.74 |
Key Takeaways:
- Improved Performance: Quantization significantly bumps up performance on both devices, but the magnitude of the improvement often varies.
- Trade-off: While quantization improves performance, it can sometimes reduce the accuracy of the LLM. The choice of quantization technique depends on the specific requirements of your application.
A Simple Analogy
Imagine you're cooking a meal:
- Apple M2: This is like using a powerful blender for a quick and easy smoothie. It's efficient for smaller recipes and provides fast results.
- NVIDIA 3090: This is like a high-powered industrial oven used in a bakery. It's perfect for baking intricate pastries and handling large batches.
Performance Analysis: Who Wins?
So, which device reigns supreme for local LLM deployment? The answer, as with most things in tech, is "it depends." Both devices offer unique advantages and cater to different needs.
Apple M2 Favored for:
- Faster token generation, leading to smoother conversational experiences.
- Handling smaller to medium sized models, maximizing efficiency.
- General-purpose tasks where memory bandwidth is critical.
- Cost-effective option with a lower price point.
NVIDIA 3090 Favored for:
- Processing massive LLM models with outstanding speed and accuracy.
- Research and experimentation where sheer processing power is paramount.
- Applications that benefit from quantization techniques.
Practical Recommendations:
- Conversational AI: For applications like chatbots and virtual assistants, the Apple M2 provides faster token generation, leading to a more interactive and natural user experience.
- Research and Development: If you're working with large, cutting-edge models or require significant computational power, the NVIDIA 3090 is your go-to device.
- Budget-conscious Developers: The Apple M2 offers a more affordable alternative, delivering impressive performance for smaller to medium-sized LLMs.
Conclusion: Choosing the Right Tool for the Job
Ultimately, the choice between the Apple M2 and NVIDIA 3090 depends on your specific LLM workload, budget, and priorities. The M2 excels in token generation and memory efficiency, making it perfect for conversational AI and demanding applications. The 3090 shines in processing massive models with its impressive GPU power, making it ideal for researchers and developers.
By understanding the strengths and weaknesses of each device, you can make an informed decision that aligns with your LLM needs and ensures a smooth and successful deployment experience.
FAQ
What are LLMs?
LLMs are powerful AI models capable of understanding and generating human-like text. They are trained on massive datasets and have revolutionized various fields, including natural language processing, translation, and coding.
What's quantization?
Quantization is a technique that reduces the precision of model weights, enabling significant performance gains while minimizing accuracy loss. Imagine it like simplifying a complex recipe by using fewer ingredients. The result might not be exactly the same, but you still get a delicious meal.
What are the limitations of running LLMs locally?
While running LLMs locally offers advantages, it also comes with limitations:
- Computational Power: Large models require significant hardware resources, possibly exceeding the capabilities of your compute device.
- Memory Limits: Your device might not have enough RAM to load and process the entire model, impacting performance.
- Power Consumption: Running a demanding LLM can drain your device's battery quickly.
What other devices are commonly used for running LLMs locally?
Other popular devices for running LLMs locally include:
- NVIDIA GeForce RTX 4090: This high-end GPU provides exceptional performance and ample memory for demanding LLMs.
- AMD Radeon RX 7900 XT: AMD's powerful GPU offers competitive performance and is a viable alternative to NVIDIA cards.
- Google's Tensor Processing Units (TPUs): TPUs are specialized hardware designed for machine learning and are often used for training and running large LLMs.
Keywords
LLMs, Apple M2, NVIDIA 3090, Token Generation, GPU, Quantization, Memory Bandwidth, Inference Speed, Local Deployment, Conversational AI, Research and Development, Performance Analysis, Benchmarking, Device Comparison, Hardware Selection, AI, Machine Learning