Which is Better for Running LLMs locally: Apple M2 100gb 10cores or NVIDIA 3080 10GB? Ultimate Benchmark Analysis
Introduction
The world of Large Language Models (LLMs) is exploding, and with it, the demand for powerful hardware to run these AI-powered marvels. You might be wondering, "Can I run these LLMs on my own computer, without relying on cloud services?" The answer is a resounding yes! But choosing the right hardware for local LLM deployment can be a tricky puzzle.
This article dives deep into the performance of two popular choices for running LLMs locally: the Apple M2 100GB 10-core processor and the NVIDIA GeForce RTX 3080 10GB graphics card. We'll analyze their strengths and weaknesses, comparing them on specific LLM models and providing data-driven insights to help you make an informed decision.
Comparing Apple M2 and NVIDIA 3080 for LLM Performance
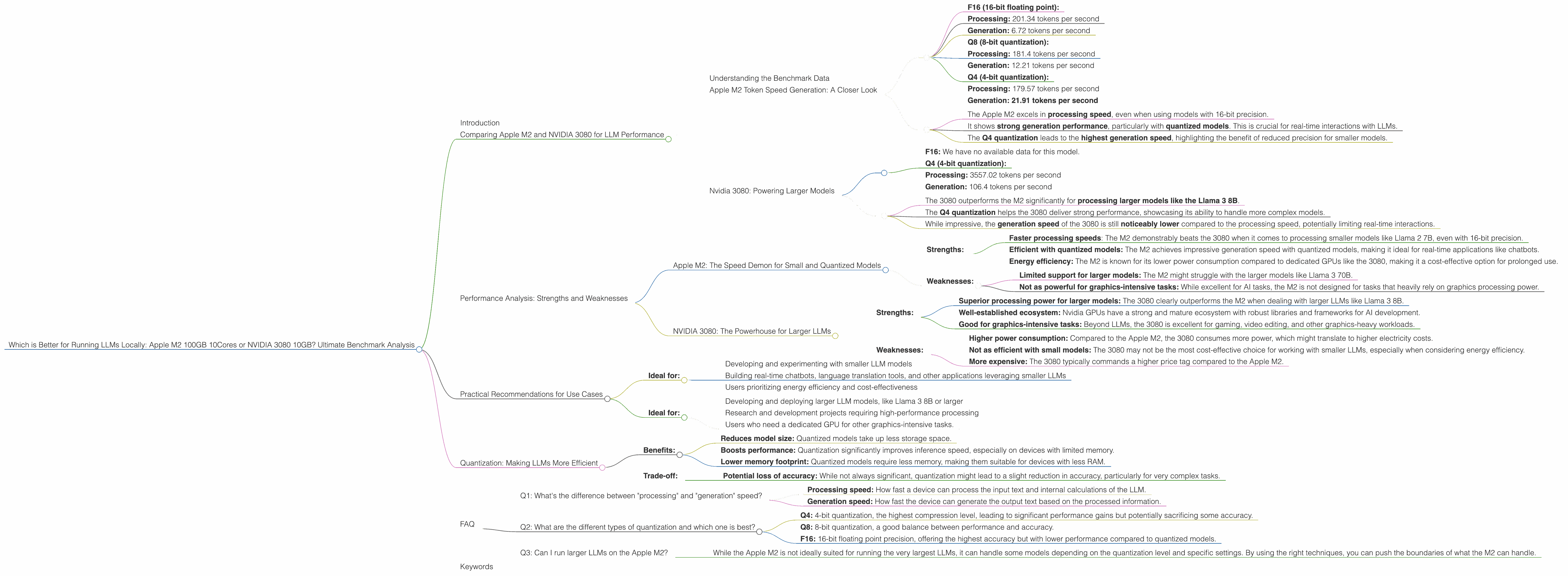
Understanding the Benchmark Data
The numbers we're working with represent the tokens per second, which is a measure of how fast a device can process the text inputs and outputs of an LLM. This metric directly translates to how fast a model can generate text, translate languages, answer questions, and perform other tasks.
Apple M2 Token Speed Generation: A Closer Look
The Apple M2 shines in its performance with smaller LLMs, especially when using quantized models (more on this later). Let's break down its performance:
- Llama 2 7B:
- F16 (16-bit floating point):
- Processing: 201.34 tokens per second
- Generation: 6.72 tokens per second
- Q8 (8-bit quantization):
- Processing: 181.4 tokens per second
- Generation: 12.21 tokens per second
- Q4 (4-bit quantization):
- Processing: 179.57 tokens per second
- Generation: 21.91 tokens per second
Key Takeaways:
- The Apple M2 excels in processing speed, even when using models with 16-bit precision.
- It shows strong generation performance, particularly with quantized models. This is crucial for real-time interactions with LLMs.
- The Q4 quantization leads to the highest generation speed, highlighting the benefit of reduced precision for smaller models.
Nvidia 3080: Powering Larger Models
The NVIDIA 3080 is a powerhouse designed for graphics-intensive tasks. It comes into its own when tackling larger LLMs. Unfortunately, we don't have data for the Llama 2 7B on the 3080, but we can compare its performance with the Llama 3 8B.
- Llama 3 8B:
- F16: We have no available data for this model.
- Q4 (4-bit quantization):
- Processing: 3557.02 tokens per second
- Generation: 106.4 tokens per second
Key Observations:
- The 3080 outperforms the M2 significantly for processing larger models like the Llama 3 8B.
- The Q4 quantization helps the 3080 deliver strong performance, showcasing its ability to handle more complex models.
- While impressive, the generation speed of the 3080 is still noticeably lower compared to the processing speed, potentially limiting real-time interactions.
Important Note: We do not have data for the Llama 3 70B on the 3080.
Performance Analysis: Strengths and Weaknesses
Apple M2: The Speed Demon for Small and Quantized Models
Strengths:
- Faster processing speeds: The M2 demonstrably beats the 3080 when it comes to processing smaller models like Llama 2 7B, even with 16-bit precision.
- Efficient with quantized models: The M2 achieves impressive generation speed with quantized models, making it ideal for real-time applications like chatbots.
- Energy efficiency: The M2 is known for its lower power consumption compared to dedicated GPUs like the 3080, making it a cost-effective option for prolonged use.
Weaknesses:
- Limited support for larger models: The M2 might struggle with the larger models like Llama 3 70B.
- Not as powerful for graphics-intensive tasks: While excellent for AI tasks, the M2 is not designed for tasks that heavily rely on graphics processing power.
NVIDIA 3080: The Powerhouse for Larger LLMs
Strengths:
- Superior processing power for larger models: The 3080 clearly outperforms the M2 when dealing with larger LLMs like Llama 3 8B.
- Well-established ecosystem: Nvidia GPUs have a strong and mature ecosystem with robust libraries and frameworks for AI development.
- Good for graphics-intensive tasks: Beyond LLMs, the 3080 is excellent for gaming, video editing, and other graphics-heavy workloads.
Weaknesses:
- Higher power consumption: Compared to the Apple M2, the 3080 consumes more power, which might translate to higher electricity costs.
- Not as efficient with small models: The 3080 may not be the most cost-effective choice for working with smaller LLMs, especially when considering energy efficiency.
- More expensive: The 3080 typically commands a higher price tag compared to the Apple M2.
Practical Recommendations for Use Cases
Apple M2:
- Ideal for:
- Developing and experimenting with smaller LLM models
- Building real-time chatbots, language translation tools, and other applications leveraging smaller LLMs
- Users prioritizing energy efficiency and cost-effectiveness
NVIDIA 3080:
- Ideal for:
- Developing and deploying larger LLM models, like Llama 3 8B or larger
- Research and development projects requiring high-performance processing
- Users who need a dedicated GPU for other graphics-intensive tasks.
Quantization: Making LLMs More Efficient
Quantization is a technique that reduces the precision of the weights in an LLM, making it smaller and faster to run. Think of it like converting a high-resolution photo to a lower-resolution one – it loses some detail but becomes much smaller and quicker to load.
Benefits:
- Reduces model size: Quantized models take up less storage space.
- Boosts performance: Quantization significantly improves inference speed, especially on devices with limited memory.
- Lower memory footprint: Quantized models require less memory, making them suitable for devices with less RAM.
Trade-off:
- Potential loss of accuracy: While not always significant, quantization might lead to a slight reduction in accuracy, particularly for very complex tasks.
Example: Imagine you want to load a high-quality photo on your smartphone. If the photo is 10MB, it might take a while to load. But if you compress it to 1MB, it'll load instantly. Quantization of LLMs works similarly, compressing them to boost performance.
FAQ
Q1: What's the difference between "processing" and "generation" speed?
- Processing speed: How fast a device can process the input text and internal calculations of the LLM.
- Generation speed: How fast the device can generate the output text based on the processed information.
Think of it like writing a book. Processing is like reading and understanding the chapters, while generation is like writing the final draft. Both are crucial for the overall writing process.
Q2: What are the different types of quantization and which one is best?
- Q4: 4-bit quantization, the highest compression level, leading to significant performance gains but potentially sacrificing some accuracy.
- Q8: 8-bit quantization, a good balance between performance and accuracy.
- F16: 16-bit floating point precision, offering the highest accuracy but with lower performance compared to quantized models.
The best quantization level depends on your specific needs and the complexity of the tasks you're performing.
Q3: Can I run larger LLMs on the Apple M2?
- While the Apple M2 is not ideally suited for running the very largest LLMs, it can handle some models depending on the quantization level and specific settings. By using the right techniques, you can push the boundaries of what the M2 can handle.
Keywords
Apple M2, NVIDIA 3080, LLM, Large Language Model, LLM performance, Token Speed, Quantization, Llama 2 7B, Llama 3 8B, GPU, CPU, Inference, Generation, Processing, Performance Benchmark, Local LLMs, Model Deployment.