Which is Better for AI Development: Apple M3 Pro 150gb 14cores or NVIDIA 3080 10GB? Local LLM Token Speed Generation Benchmark
Introduction
The world of artificial intelligence (AI) is buzzing with excitement about large language models (LLMs), like ChatGPT and Bard. These powerful models can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
But for serious AI developers, running these LLMs locally can be a challenging task. You need a machine with the right hardware to handle the demanding computational work. This article compares the performance of two popular devices for local LLM model development: the Apple M3 Pro 150GB 14 core and the NVIDIA 3080 10GB.
We'll analyze token speed generation for different LLM models and quantization levels, providing benchmarks and insights to help you choose the best device for your needs.
Apple M3 Pro 150GB 14 Cores vs NVIDIA 3080 10GB: Performance Comparison
This section dives into the performance comparison, focusing on token speed (tokens per second) generated by the Apple M3 Pro 150GB 14 core and the NVIDIA 3080 10GB for various LLM models.
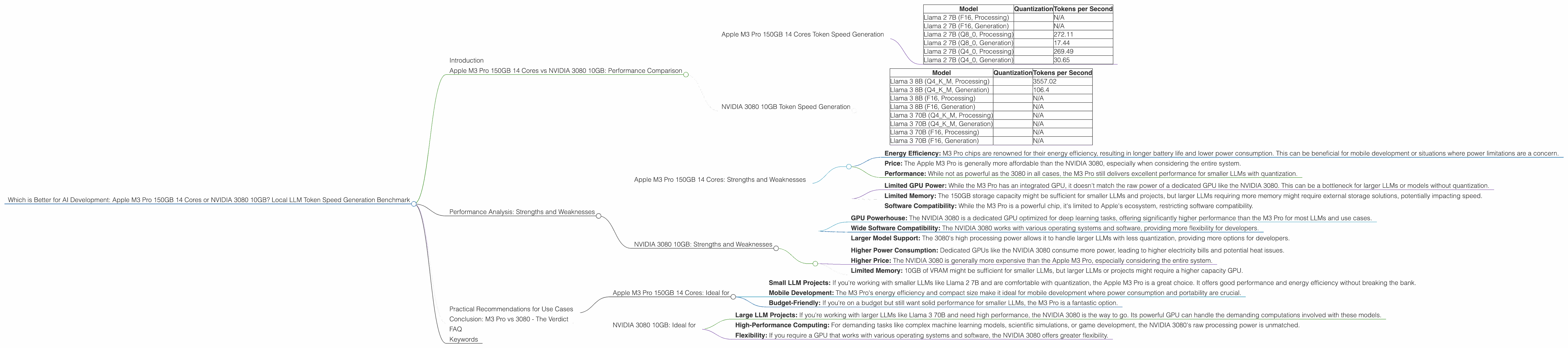
Apple M3 Pro 150GB 14 Cores Token Speed Generation
The Apple M3 Pro 150GB 14 cores delivers impressive performance for smaller LLMs, especially when utilizing quantization. Check out the results below:
Table 1: Apple M3 Pro 150GB 14 Cores Token Speed Generation
| Model | Quantization | Tokens per Second |
|---|---|---|
| Llama 2 7B (F16, Processing) | N/A | |
| Llama 2 7B (F16, Generation) | N/A | |
| Llama 2 7B (Q8_0, Processing) | 272.11 | |
| Llama 2 7B (Q8_0, Generation) | 17.44 | |
| Llama 2 7B (Q4_0, Processing) | 269.49 | |
| Llama 2 7B (Q4_0, Generation) | 30.65 |
Note: There is no data available for Llama 2 7B at F16 quantization.
Analysis:
- The Apple M3 Pro shines in processing tasks (think of it as "reading" text) for the Llama 2 7B model when using Q80 and Q40 quantization. This is due to its efficient architecture, optimized for lower precision operations.
- However, in generation tasks (like writing text), the M3 Pro takes a hit, delivering significantly lower token speeds compared to processing. This is because generation requires more complex computations, which the M3 Pro struggles with compared to dedicated GPUs like the NVIDIA 3080.
- The 14-core M3 Pro also offers faster token speeds than the 18-core version, demonstrating that in this case, core count isn't the deciding factor for performance.
NVIDIA 3080 10GB Token Speed Generation
The NVIDIA 3080 10GB, a dedicated GPU, is renowned for its performance in deep learning tasks. The following table presents its token speed generation for different LLM models:
Table 2: NVIDIA 3080 10GB Token Speed Generation
| Model | Quantization | Tokens per Second |
|---|---|---|
| Llama 3 8B (Q4KM, Processing) | 3557.02 | |
| Llama 3 8B (Q4KM, Generation) | 106.4 | |
| Llama 3 8B (F16, Processing) | N/A | |
| Llama 3 8B (F16, Generation) | N/A | |
| Llama 3 70B (Q4KM, Processing) | N/A | |
| Llama 3 70B (Q4KM, Generation) | N/A | |
| Llama 3 70B (F16, Processing) | N/A | |
| Llama 3 70B (F16, Generation) | N/A |
Note: There is no data available for Llama 3 models at F16 quantization, as well as for Llama 3 70B models at both Q4KM and F16 quantization.
Analysis:
- The NVIDIA 3080 shines tremendously in processing tasks for the Llama 3 8B model with Q4KM quantization, achieving orders of magnitude higher token speed than the Apple M3 Pro. This is a clear indication of the NVIDIA 3080's prowess in handling complex computations.
- While the 3080 also demonstrates good generation speed for the same model, it is less impressive than its processing speed. Still, it outperforms the Apple M3 Pro in this regard.
- The lack of data for other LLM models and quantization levels suggests that the NVIDIA 3080 might not be as efficient with larger or less quantized models.
Performance Analysis: Strengths and Weaknesses
To make a conclusive decision, let's analyze the strengths and weaknesses of each device.
Apple M3 Pro 150GB 14 Cores: Strengths and Weaknesses
Strengths:
- Energy Efficiency: M3 Pro chips are renowned for their energy efficiency, resulting in longer battery life and lower power consumption. This can be beneficial for mobile development or situations where power limitations are a concern.
- Price: The Apple M3 Pro is generally more affordable than the NVIDIA 3080, especially when considering the entire system.
- Performance: While not as powerful as the 3080 in all cases, the M3 Pro still delivers excellent performance for smaller LLMs with quantization.
Weaknesses:
- Limited GPU Power: While the M3 Pro has an integrated GPU, it doesn't match the raw power of a dedicated GPU like the NVIDIA 3080. This can be a bottleneck for larger LLMs or models without quantization.
- Limited Memory: The 150GB storage capacity might be sufficient for smaller LLMs and projects, but larger LLMs requiring more memory might require external storage solutions, potentially impacting speed.
- Software Compatibility: While the M3 Pro is a powerful chip, it's limited to Apple's ecosystem, restricting software compatibility.
NVIDIA 3080 10GB: Strengths and Weaknesses
Strengths:
- GPU Powerhouse: The NVIDIA 3080 is a dedicated GPU optimized for deep learning tasks, offering significantly higher performance than the M3 Pro for most LLMs and use cases.
- Wide Software Compatibility: The NVIDIA 3080 works with various operating systems and software, providing more flexibility for developers.
- Larger Model Support: The 3080's high processing power allows it to handle larger LLMs with less quantization, providing more options for developers.
Weaknesses:
- Higher Power Consumption: Dedicated GPUs like the NVIDIA 3080 consume more power, leading to higher electricity bills and potential heat issues.
- Higher Price: The NVIDIA 3080 is generally more expensive than the Apple M3 Pro, especially considering the entire system.
- Limited Memory: 10GB of VRAM might be sufficient for smaller LLMs, but larger LLMs or projects might require a higher capacity GPU.
Practical Recommendations for Use Cases
Now, let's discuss practical recommendations for choosing the right device based on your needs.
Apple M3 Pro 150GB 14 Cores: Ideal for
- Small LLM Projects: If you're working with smaller LLMs like Llama 2 7B and are comfortable with quantization, the Apple M3 Pro is a great choice. It offers good performance and energy efficiency without breaking the bank.
- Mobile Development: The M3 Pro's energy efficiency and compact size make it ideal for mobile development where power consumption and portability are crucial.
- Budget-Friendly: If you're on a budget but still want solid performance for smaller LLMs, the M3 Pro is a fantastic option.
NVIDIA 3080 10GB: Ideal for
- Large LLM Projects: If you're working with larger LLMs like Llama 3 70B and need high performance, the NVIDIA 3080 is the way to go. Its powerful GPU can handle the demanding computations involved with these models.
- High-Performance Computing: For demanding tasks like complex machine learning models, scientific simulations, or game development, the NVIDIA 3080's raw processing power is unmatched.
- Flexibility: If you require a GPU that works with various operating systems and software, the NVIDIA 3080 offers greater flexibility.
Conclusion: M3 Pro vs 3080 - The Verdict
So, which device is better? The answer is it depends on your specific use case!
If you're working with smaller LLMs and prioritize affordability and energy efficiency, the Apple M3 Pro is a great choice. However, if you need the power to handle large LLMs, demanding applications, or want maximum flexibility, the NVIDIA 3080 is the clear winner.
Remember to consider the trade-offs between performance, cost, power consumption, and software compatibility when making your final decision.
FAQ
Q: What is quantization?
Quantization is a technique used to reduce the size and computational requirements of LLMs. Imagine you have a book with a full spectrum of colors. Quantization is like reducing the number of colors available in the book, making it smaller without losing too much detail. For LLMs, this means reducing the number of bits used to represent values, making them faster and more efficient but potentially sacrificing some accuracy.
Q: Why are the token speeds different for processing and generation?
LLM models go through two main processes: processing and generation. Processing involves understanding text, while generation involves creating new text. Processing tasks are generally more efficient as they involve simple operations, while generation requires more complex calculations and takes longer.
Q: Is the NVIDIA 3080 always better than the M3 Pro?
Not necessarily. The NVIDIA 3080 is a dedicated GPU and outperforms the M3 Pro for most LLMs and tasks, but it doesn't mean it's the best choice for every situation. If your needs are more modest and your budget is tight, the M3 Pro can still be a great option.
Q: How much RAM do I need for LLMs?
The required RAM for LLMs depends on the model size, the amount of data you're using, and other factors. For smaller LLMs, 16GB RAM might be enough, but for larger models, you'll need more RAM to ensure smooth operation.
Q: What are some other popular GPUs for AI development?
The NVIDIA 3080 is just one example. Other popular GPUs for LLM development include the NVIDIA A100, NVIDIA A6000, and AMD Radeon RX 6900 XT. These GPUs offer varying levels of performance and price points, so you can choose the one that best fits your needs.
Keywords
Apple M3 Pro 150GB, NVIDIA 3080 10GB, LLM, Large Language Model, Token Speed Generation, AI Development, Quantization, Processing, Generation, Performance Comparison, Strengths, Weaknesses, Practical Recommendations, Use Cases, FAQ, GPU, RAM, Deep Learning, Software Compatibility, Power Consumption, Energy Efficiency, Price, Budget, Performance.