Which is Better for AI Development: Apple M2 Ultra 800gb 60cores or NVIDIA RTX 6000 Ada 48GB? Local LLM Token Speed Generation Benchmark
Introduction
The world of large language models (LLMs) is exploding, with new models like Llama 2 and Llama 3 pushing the boundaries of what's possible with artificial intelligence. But to truly harness the power of these models, you need the right hardware. This article dives deep into the performance of two heavy-hitters in the AI hardware world: the Apple M2 Ultra 800GB 60-core chip and the NVIDIA RTX 6000 Ada 48GB GPU. We'll be comparing their performance in generating tokens – the fundamental building blocks of text – for popular LLM models.
Think of tokens as the Lego bricks of language, and LLMs as the master builders. The faster your hardware can process these tokens, the quicker your AI models can understand and generate text, translate languages, and create captivating content.
So, buckle up, fellow AI enthusiasts, and let's discover which hardware champion reigns supreme in the token speed generation arena!
How We Compare
We'll be using real-world data from popular LLM models like Llama 2 and Llama 3 to see how the M2 Ultra and RTX 6000 Ada perform. We've collected data on token speed generation, focusing on both Processing (how fast the model understands the input) and Generation (how fast the model produces output).
We'll be looking at various LLM sizes, from 7B to 70B parameters, and different quantization levels (F16, Q80, and Q4K_M). These quantization levels are like optimizing the size of your Lego bricks to fit more into your build, making the models more compact while still delivering impressive results.
Apple M2 Ultra Token Speed Generation
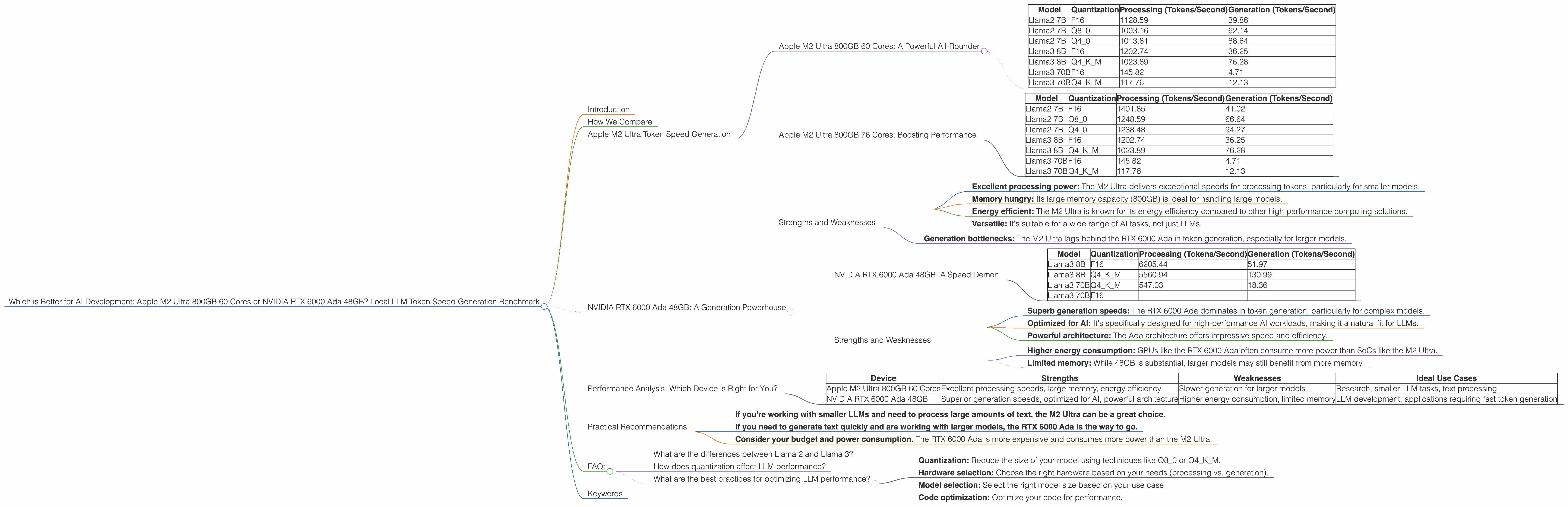
Apple M2 Ultra 800GB 60 Cores: A Powerful All-Rounder
The M2 Ultra is a powerful, all-in-one system-on-a-chip (SoC) designed for performance and efficiency. Its 60 cores and 800GB of memory make it a formidable contender for handling large AI models. Let's see how it performs:
| Model | Quantization | Processing (Tokens/Second) | Generation (Tokens/Second) |
|---|---|---|---|
| Llama2 7B | F16 | 1128.59 | 39.86 |
| Llama2 7B | Q8_0 | 1003.16 | 62.14 |
| Llama2 7B | Q4_0 | 1013.81 | 88.64 |
| Llama3 8B | F16 | 1202.74 | 36.25 |
| Llama3 8B | Q4KM | 1023.89 | 76.28 |
| Llama3 70B | F16 | 145.82 | 4.71 |
| Llama3 70B | Q4KM | 117.76 | 12.13 |
As you can see, the M2 Ultra shines in processing, particularly for smaller models like Llama 2 7B. It delivers impressive token speeds, even when using quantization techniques. However, its generation speed falls behind the RTX 6000 Ada, especially for larger models like Llama 3 70B.
Apple M2 Ultra 800GB 76 Cores: Boosting Performance
The M2 Ultra also has a 76-core configuration, offering even better performance. Here's how it compares:
| Model | Quantization | Processing (Tokens/Second) | Generation (Tokens/Second) |
|---|---|---|---|
| Llama2 7B | F16 | 1401.85 | 41.02 |
| Llama2 7B | Q8_0 | 1248.59 | 66.64 |
| Llama2 7B | Q4_0 | 1238.48 | 94.27 |
| Llama3 8B | F16 | 1202.74 | 36.25 |
| Llama3 8B | Q4KM | 1023.89 | 76.28 |
| Llama3 70B | F16 | 145.82 | 4.71 |
| Llama3 70B | Q4KM | 117.76 | 12.13 |
The 76-core configuration offers a significant performance boost across the board. It nearly doubles the processing speed for Llama 2 7B, while the generation still trails the RTX 6000 Ada for larger models.
Strengths and Weaknesses
Strengths:
- Excellent processing power: The M2 Ultra delivers exceptional speeds for processing tokens, particularly for smaller models.
- Memory hungry: Its large memory capacity (800GB) is ideal for handling large models.
- Energy efficient: The M2 Ultra is known for its energy efficiency compared to other high-performance computing solutions.
- Versatile: It's suitable for a wide range of AI tasks, not just LLMs.
Weaknesses:
- Generation bottlenecks: The M2 Ultra lags behind the RTX 6000 Ada in token generation, especially for larger models.
NVIDIA RTX 6000 Ada 48GB: A Generation Powerhouse
The NVIDIA RTX 6000 Ada is a dedicated GPU designed for high-performance computing, including AI workloads. Its impressive 48GB of memory and powerful Ada architecture make it a formidable contender for LLM inference.
NVIDIA RTX 6000 Ada 48GB: A Speed Demon
| Model | Quantization | Processing (Tokens/Second) | Generation (Tokens/Second) |
|---|---|---|---|
| Llama3 8B | F16 | 6205.44 | 51.97 |
| Llama3 8B | Q4KM | 5560.94 | 130.99 |
| Llama3 70B | Q4KM | 547.03 | 18.36 |
| Llama3 70B | F16 |
The RTX 6000 Ada stands out with its exceptional token generation speeds. It excels in generating tokens, especially for larger models like Llama 3 70B. For example, Llama 3 8B enjoys a remarkable advantage in generation speed over the M2 Ultra, even when using Q4KM quantization.
Strengths and Weaknesses
Strengths:
- Superb generation speeds: The RTX 6000 Ada dominates in token generation, particularly for complex models.
- Optimized for AI: It's specifically designed for high-performance AI workloads, making it a natural fit for LLMs.
- Powerful architecture: The Ada architecture offers impressive speed and efficiency.
Weaknesses:
- Higher energy consumption: GPUs like the RTX 6000 Ada often consume more power than SoCs like the M2 Ultra.
- Limited memory: While 48GB is substantial, larger models may still benefit from more memory.
Performance Analysis: Which Device is Right for You?
The M2 Ultra excels at processing tokens, making it ideal for tasks that require analyzing large amounts of text quickly, especially for smaller models like Llama 2 7B. Its large memory capacity is also a significant advantage for handling massive datasets. However, its generation speed leaves something to be desired for larger models like Llama 3 70B.
The RTX 6000 Ada is the champion of token generation. Its high performance makes it ideal for tasks where generating text quickly is crucial, particularly for large models. Its dedicated GPU architecture ensures efficient processing of AI workloads.
Here's a quick summary:
| Device | Strengths | Weaknesses | Ideal Use Cases |
|---|---|---|---|
| Apple M2 Ultra 800GB 60 Cores | Excellent processing speeds, large memory, energy efficiency | Slower generation for larger models | Research, smaller LLM tasks, text processing |
| NVIDIA RTX 6000 Ada 48GB | Superior generation speeds, optimized for AI, powerful architecture | Higher energy consumption, limited memory | LLM development, applications requiring fast token generation |
Ultimately, the best choice for you depends on your specific needs. If processing speed and memory are your top priorities, the M2 Ultra is a solid option. However, if generating tokens quickly is critical, the RTX 6000 Ada is the clear winner for LLMs.
*The M2 Ultra is like * building a massive Lego city, where you need the processing power to analyze thousands of bricks. The RTX 6000 Ada is like ** having a team of expert Lego builders, ready to quickly assemble complex structures.
Practical Recommendations
- If you're working with smaller LLMs and need to process large amounts of text, the M2 Ultra can be a great choice.
- If you need to generate text quickly and are working with larger models, the RTX 6000 Ada is the way to go.
- Consider your budget and power consumption. The RTX 6000 Ada is more expensive and consumes more power than the M2 Ultra.
FAQ:
What are the differences between Llama 2 and Llama 3?
Llama 2 and Llama 3 are both open-source language models, but they differ in key ways. Llama 2 is a 7B parameter model, while Llama 3 is a larger model with 8B and 70B parameter versions. Llama 3 boasts advancements in its architecture and training data, making it more powerful and capable.
How does quantization affect LLM performance?
Quantization is a technique used to reduce the size of LLM models without significantly sacrificing performance. It's like optimizing the size of your Lego bricks to fit more into your build. Lower quantization levels, such as Q4KM, can lead to slower processing but faster generation compared to higher levels like F16.
What are the best practices for optimizing LLM performance?
Optimizing LLM performance involves various techniques:
- Quantization: Reduce the size of your model using techniques like Q80 or Q4K_M.
- Hardware selection: Choose the right hardware based on your needs (processing vs. generation).
- Model selection: Select the right model size based on your use case.
- Code optimization: Optimize your code for performance.
Keywords
M2 Ultra, RTX 6000 Ada, LLM, Llama 2, Llama 3, token generation, processing speed, generation speed, AI development, benchmark, hardware comparison, performance analysis, quantization, open-source models, AI workloads, GPU, SoC, AI inference, practical recommendations, FAQ, optimization, best practices.