Which is Better for AI Development: Apple M2 Ultra 800gb 60cores or NVIDIA 3090 24GB x2? Local LLM Token Speed Generation Benchmark
Introduction
The world of AI is booming, with Large Language Models (LLMs) taking center stage. These powerful models are used in everything from chatbots to code generation, but they require significant computational resources to run. Many developers are exploring the possibility of running LLMs locally, which can offer speed and privacy benefits but raises the question: Which hardware is best for local LLM development?
This article delves into the performance of two popular choices: the Apple M2 Ultra 800gb 60cores (affectionately known as the "M2 Ultra" for short) and two Nvidia 3090 24GB GPUs (let's call this "Dual 3090"). We will compare their token speed generation for various LLMs and explore their strengths and weaknesses for different use cases.
Think of token speed generation as the number of words a model can process and generate per second. Imagine a typist furiously banging away on a keyboard. The faster the typist, the more words they can produce in a given time. In our case, the faster the tokens are generated (words processed), the quicker you get answers and complete your tasks.
Let's dive into the benchmarks and see how these titans of hardware perform.
Comparison of Apple M2 Ultra and Dual 3090 Token Generation Speeds
To get the most out of this comparison, we need to understand the various LLM models and their configurations.
LLMs:
- Llama2 7B: A relatively smaller model that's great for experimentation and smaller projects.
- Llama3 8B: Slightly larger than Llama2 7B, balancing performance and resource consumption.
- Llama3 70B: A powerful model capable of complex tasks and advanced applications.
Configurations:
- F16: This is a common quantization level that uses 16 bits to represent each number. It's a good balance between accuracy and speed.
- Q8_0: A lower precision format, using 8 bits to represent a number. It might slightly impact accuracy but provides significant speed improvements.
- Q4KM: A more aggressive quantization, using 4 bits per number. It's often used to make LLMs fit on smaller devices, but might reduce accuracy further.
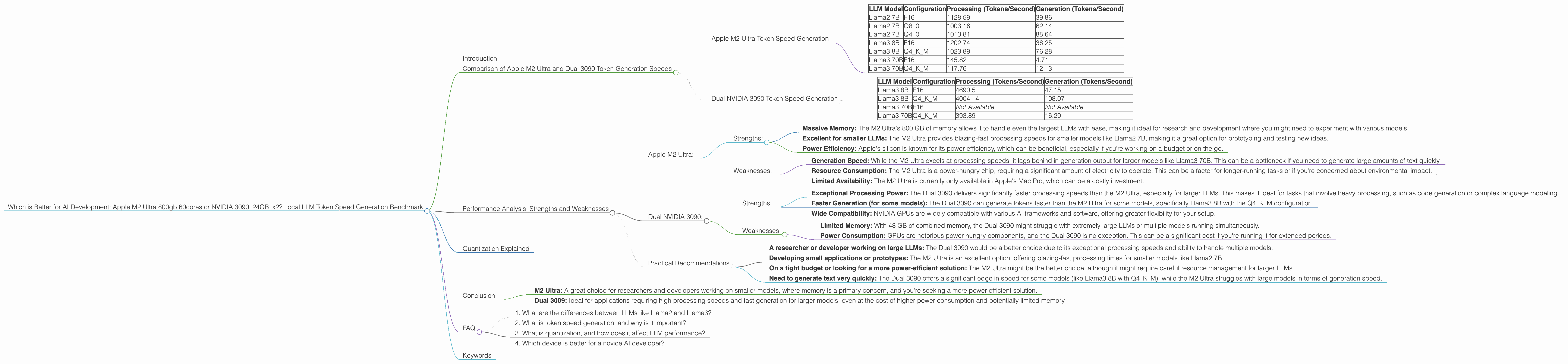
Apple M2 Ultra Token Speed Generation
The Apple M2 Ultra is a beast of a processor with 60 CPU cores and 800 GB of memory. Its massive memory capacity is a significant advantage when handling large LLM models.
Let's break down the M2 Ultra's performance:
| LLM Model | Configuration | Processing (Tokens/Second) | Generation (Tokens/Second) |
|---|---|---|---|
| Llama2 7B | F16 | 1128.59 | 39.86 |
| Llama2 7B | Q8_0 | 1003.16 | 62.14 |
| Llama2 7B | Q4_0 | 1013.81 | 88.64 |
| Llama3 8B | F16 | 1202.74 | 36.25 |
| Llama3 8B | Q4KM | 1023.89 | 76.28 |
| Llama3 70B | F16 | 145.82 | 4.71 |
| Llama3 70B | Q4KM | 117.76 | 12.13 |
Observations:
- The M2 Ultra shines in processing speeds, particularly with the Llama2 7B model, delivering impressive results across all configurations.
- The M2 Ultra's generation speed is significantly lower, especially with larger models like Llama3 70B.
Dual NVIDIA 3090 Token Speed Generation
Dual 3090 is a formidable GPU setup with 24GB of memory on each card, totaling a whopping 48GB. While it lacks the massive memory of the M2 Ultra, the GPUs can process information in parallel, making it powerful for certain tasks.
| LLM Model | Configuration | Processing (Tokens/Second) | Generation (Tokens/Second) |
|---|---|---|---|
| Llama3 8B | F16 | 4690.5 | 47.15 |
| Llama3 8B | Q4KM | 4004.14 | 108.07 |
| Llama3 70B | F16 | Not Available | Not Available |
| Llama3 70B | Q4KM | 393.89 | 16.29 |
Observations:
- Compared to the M2 Ultra, the Dual 3090 has significantly faster processing speeds, especially with the Llama3 8B model.
- The Dual 3090 also shows a noticeable improvement in generation speed for the Llama3 8B model compared to the M2 Ultra, specifically with the Q4KM configuration.
Performance Analysis: Strengths and Weaknesses
We've seen some impressive numbers, but how do these two devices stack up for real-world AI development? Let's break down their strengths and weaknesses:
Apple M2 Ultra:
Strengths:
- Massive Memory: The M2 Ultra's 800 GB of memory allows it to handle even the largest LLMs with ease, making it ideal for research and development where you might need to experiment with various models.
- Excellent for smaller LLMs: The M2 Ultra provides blazing-fast processing speeds for smaller models like Llama2 7B, making it a great option for prototyping and testing new ideas.
- Power Efficiency: Apple's silicon is known for its power efficiency, which can be beneficial, especially if you're working on a budget or on the go.
Weaknesses:
- Generation Speed: While the M2 Ultra excels at processing speeds, it lags behind in generation output for larger models like Llama3 70B. This can be a bottleneck if you need to generate large amounts of text quickly.
- Resource Consumption: The M2 Ultra is a power-hungry chip, requiring a significant amount of electricity to operate. This can be a factor for longer-running tasks or if you're concerned about environmental impact.
- Limited Availability: The M2 Ultra is currently only available in Apple's Mac Pro, which can be a costly investment.
Dual NVIDIA 3090:
Strengths;
- Exceptional Processing Power: The Dual 3090 delivers significantly faster processing speeds than the M2 Ultra, especially for larger LLMs. This makes it ideal for tasks that involve heavy processing, such as code generation or complex language modeling.
- Faster Generation (for some models): The Dual 3090 can generate tokens faster than the M2 Ultra for some models, specifically Llama3 8B with the Q4KM configuration.
- Wide Compatibility: NVIDIA GPUs are widely compatible with various AI frameworks and software, offering greater flexibility for your setup.
Weaknesses:
- Limited Memory: With 48 GB of combined memory, the Dual 3090 might struggle with extremely large LLMs or multiple models running simultaneously.
- Power Consumption: GPUs are notorious power-hungry components, and the Dual 3090 is no exception. This can be a significant cost if you're running it for extended periods.
Practical Recommendations
If you are...
- A researcher or developer working on large LLMs: The Dual 3090 would be a better choice due to its exceptional processing speeds and ability to handle multiple models.
- Developing small applications or prototypes: The M2 Ultra is an excellent option, offering blazing-fast processing times for smaller models like Llama2 7B.
- On a tight budget or looking for a more power-efficient solution: The M2 Ultra might be the better choice, although it might require careful resource management for larger LLMs.
- Need to generate text very quickly: The Dual 3090 offers a significant edge in speed for some models (like Llama3 8B with Q4KM), while the M2 Ultra struggles with large models in terms of generation speed.
Quantization Explained
Quantization might sound like a complex term, but it's simply a way to make LLMs smaller and faster. Think of it like compressing a large file into a smaller, more manageable one.
Imagine a large photo file that takes up a lot of storage space. You can "quantize" it by reducing the number of colors used, resulting in a smaller file that's easier to share and faster to load.
Similarly, quantization in LLMs reduces the number of bits used to store the weights of the model. F16 uses 16 bits per weight, Q80 uses 8 bits, and Q4K_M uses only 4 bits! This significantly reduces the memory footprint and improves processing speeds, but might slightly impact the accuracy.
Conclusion
The Apple M2 Ultra and Dual NVIDIA 3090 are both powerful devices, each with strengths and weaknesses. The "best" device for you depends heavily on your specific needs and application:
- M2 Ultra: A great choice for researchers and developers working on smaller models, where memory is a primary concern, and you're seeking a more power-efficient solution.
- Dual 3009: Ideal for applications requiring high processing speeds and fast generation for larger models, even at the cost of higher power consumption and potentially limited memory.
FAQ
1. What are the differences between LLMs like Llama2 and Llama3?
Llama2 and Llama3 are large language models developed by different teams. Llama2 is generally considered more accessible and easier to use, while Llama3 is known for its advanced capabilities and often requires more computational resources to run.
2. What is token speed generation, and why is it important?
Token speed generation refers to the number of words or "tokens" a language model can process and generate each second. A higher token generation speed means faster text processing and generation, leading to quicker results and improved user experience.
3. What is quantization, and how does it affect LLM performance?
Quantization is a technique that reduces the size of an LLM by using fewer bits to represent each number. It enhances processing speeds but might slightly impact the model's accuracy. Imagine compressing a large photo file; the smaller file still retains the essence of the image, but with a slight reduction in detail.
4. Which device is better for a novice AI developer?
For a novice AI developer, the M2 Ultra might be a good starting point. Its massive memory is excellent for experimentation, and the relatively lower power consumption can be more budget-friendly. However, if you're serious about building large-scale applications or exploring advanced models, the Dual 3090 might be a better investment.
Keywords
Apple M2 Ultra, NVIDIA 3090, LLM Token Speed, Local LLM Development, Generation Speed, Processing Speed, Quantization, Llama2 7B, Llama3 8B, Llama3 70B, AI Development, GPU, CPU, AI Hardware, Machine Learning, Deep Learning, AI Performance, Tokenization, AI Benchmark, F16, Q80, Q4K_M