Which is Better for AI Development: Apple M2 Pro 200gb 16cores or NVIDIA 4090 24GB x2? Local LLM Token Speed Generation Benchmark
Introduction
The world of AI development is constantly evolving, and with it comes the need for powerful hardware to support complex tasks like training and running Large Language Models (LLMs). We're exploring the capabilities of two industry-leading devices: the Apple M2 Pro and the NVIDIA 4090. This article will compare the performance of these devices in the context of generating tokens locally, a key aspect of LLM inference. Our goal is to provide developers with a clear understanding of their strengths and weaknesses, enabling them to choose the best device for their specific needs.
Performance Analysis: M2 Pro vs. 409024GBx2
This section dives deep into the performance of the M2 Pro and the 409024GBx2 in local LLM token generation.
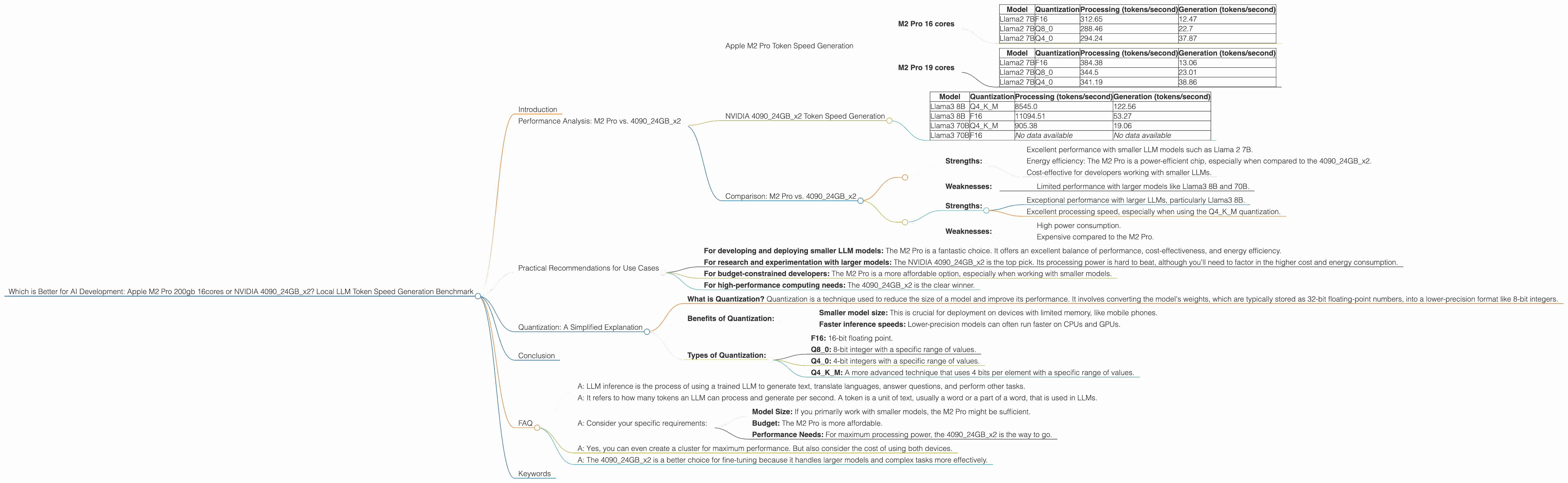
Apple M2 Pro Token Speed Generation
The M2 Pro is an impressive piece of hardware. We'll look at the M2 Pro with two different configurations: 16 cores and 19 cores as per our dataset.
M2 Pro 16 cores
The M2 Pro (16 cores) delivers impressive speeds, but only for smaller models. It shines with the Llama 2 7B model, showcasing remarkable performance in all quantization modes.
Here's a breakdown of token speeds:
| Model | Quantization | Processing (tokens/second) | Generation (tokens/second) |
|---|---|---|---|
| Llama2 7B | F16 | 312.65 | 12.47 |
| Llama2 7B | Q8_0 | 288.46 | 22.7 |
| Llama2 7B | Q4_0 | 294.24 | 37.87 |
Key takeaway: The M2 Pro (16 cores) is a strong contender for developers focusing on smaller models.
M2 Pro 19 cores
The M2 Pro (19 cores) provides a slight enhancement over the 16 core version.
Here's a breakdown of token speeds:
| Model | Quantization | Processing (tokens/second) | Generation (tokens/second) |
|---|---|---|---|
| Llama2 7B | F16 | 384.38 | 13.06 |
| Llama2 7B | Q8_0 | 344.5 | 23.01 |
| Llama2 7B | Q4_0 | 341.19 | 38.86 |
Key takeaway: The M2 Pro (19 cores) delivers a performance boost, but it still struggles with larger models.
NVIDIA 409024GBx2 Token Speed Generation
The NVIDIA 409024GBx2 is a powerhouse designed for demanding tasks including LLM inference. Let's see how it stacks up:
Here's a breakdown of token speeds:
| Model | Quantization | Processing (tokens/second) | Generation (tokens/second) |
|---|---|---|---|
| Llama3 8B | Q4KM | 8545.0 | 122.56 |
| Llama3 8B | F16 | 11094.51 | 53.27 |
| Llama3 70B | Q4KM | 905.38 | 19.06 |
| Llama3 70B | F16 | No data available | No data available |
Observations:
- Impressive performance with Llama3 8B: The 4090 shines when processing the Llama3 8B model. The processing speeds are significantly higher than the M2 Pro, exceeding 10,000 tokens per second in F16.
- Generation speed: The 409024GBx2 handles generation effectively, with speeds reaching 122.56 tokens per second for the Llama3 8B model.
- Larger model performance: While the 4090 struggles with the Llama3 70B model's generation speed, as seen in the limited data provided, its processing speed is still impressive.
Comparison: M2 Pro vs. 409024GBx2
Let's compare the two devices:
M2 Pro: * Strengths: * Excellent performance with smaller LLM models such as Llama 2 7B. * Energy efficiency: The M2 Pro is a power-efficient chip, especially when compared to the 409024GBx2. * Cost-effective for developers working with smaller LLMs. * Weaknesses: * Limited performance with larger models like Llama3 8B and 70B.
409024GBx2: * Strengths: * Exceptional performance with larger LLMs, particularly Llama3 8B. * Excellent processing speed, especially when using the Q4KM quantization. * Weaknesses: * High power consumption. * Expensive compared to the M2 Pro.
Example analogy: Think of the M2 Pro as a nimble sprinter, excelling in shorter races (smaller models) but losing steam in long distances (larger models). The 409024GBx2 is a marathon runner, built for endurance and handling large, complex workload (LLMs).
Practical Recommendations for Use Cases
Based on the performance data and our analysis, here are some practical recommendations based on your specific development needs:
- For developing and deploying smaller LLM models: The M2 Pro is a fantastic choice. It offers an excellent balance of performance, cost-effectiveness, and energy efficiency.
- For research and experimentation with larger models: The NVIDIA 409024GBx2 is the top pick. Its processing power is hard to beat, although you'll need to factor in the higher cost and energy consumption.
- For budget-constrained developers: The M2 Pro is a more affordable option, especially when working with smaller models.
- For high-performance computing needs: The 409024GBx2 is the clear winner.
Quantization: A Simplified Explanation
- What is Quantization? Quantization is a technique used to reduce the size of a model and improve its performance. It involves converting the model's weights, which are typically stored as 32-bit floating-point numbers, into a lower-precision format like 8-bit integers.
- Benefits of Quantization:
- Smaller model size: This is crucial for deployment on devices with limited memory, like mobile phones.
- Faster inference speeds: Lower-precision models can often run faster on CPUs and GPUs.
- Types of Quantization:
- F16: 16-bit floating point.
- Q80: 8-bit integer with a specific range of values.
- Q40: 4-bit integers with a specific range of values.
- Q4KM: A more advanced technique that uses 4 bits per element with a specific range of values.
Conclusion
The choice between the Apple M2 Pro and NVIDIA 409024GBx2 depends on your specific LLM development needs. For smaller models, the M2 Pro is a powerful, cost-effective option, while the 409024GBx2 takes the lead for handling larger models and demanding workloads.
FAQ
Q: What is LLM inference? * A: LLM inference is the process of using a trained LLM to generate text, translate languages, answer questions, and perform other tasks.
Q: What does "token speed generation" mean? * A: It refers to how many tokens an LLM can process and generate per second. A token is a unit of text, usually a word or a part of a word, that is used in LLMs.
Q: What's the best way to choose between these two devices? * A: Consider your specific requirements: * Model Size: If you primarily work with smaller models, the M2 Pro might be sufficient. * Budget: The M2 Pro is more affordable. * Performance Needs: For maximum processing power, the 409024GBx2 is the way to go.
Q: Is it possible to use both devices together? * A: Yes, you can even create a cluster for maximum performance. But also consider the cost of using both devices.
Q: Which device is better for fine-tuning LLMs? * A: The 409024GBx2 is a better choice for fine-tuning because it handles larger models and complex tasks more effectively.
Keywords
Apple M2 Pro, NVIDIA 4090, LLM, token speed generation, Llama 2 7B, Llama3 70B, Llama3 8B, AI development, local inference, quantization, F16, Q80, Q40, Q4KM, performance benchmark, processing speed, generation speed, cost-effectiveness, power consumption, use cases.