Which is Better for AI Development: Apple M2 Max 400gb 30cores or NVIDIA 3090 24GB x2? Local LLM Token Speed Generation Benchmark
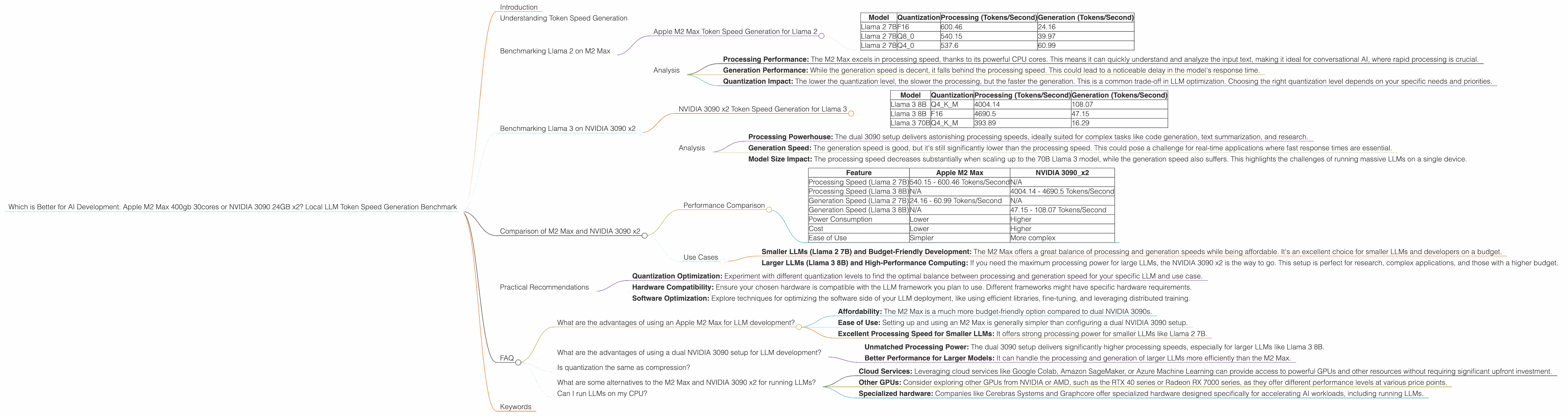
Introduction
The world of large language models (LLMs) is exploding, with new models and applications popping up every day. This has sparked a race to find the best hardware to train and run these massive models. Two contenders often come up: the powerful Apple M2 Max chip and the mighty NVIDIA 3090, often paired in a dual setup for maximum performance.
But which one reigns supreme for local LLM development? This article digs deep into the token speed generation of these two hardware titans, comparing their performance on Llama 2 and Llama 3 models. We'll break down the numbers, analyze the strengths and weaknesses of each, and provide practical recommendations for different use cases. Buckle up, AI enthusiasts, this is going to be a wild ride!
Understanding Token Speed Generation
Before diving into the numbers, let's clarify what we mean by "token speed generation". LLMs process text by breaking it down into individual units called tokens. These tokens can be single words, parts of words, or special punctuation marks.
Token speed generation refers to how fast a device can generate these tokens. Higher token speed means faster model inference, resulting in quicker responses from your AI.
Benchmarking Llama 2 on M2 Max
The Apple M2 Max is a beast, boasting 30 CPU cores and a massive 400GB of RAM. Let's see how it performs with the Llama 2 model, a widely popular and versatile LLM.
Apple M2 Max Token Speed Generation for Llama 2
| Model | Quantization | Processing (Tokens/Second) | Generation (Tokens/Second) |
|---|---|---|---|
| Llama 2 7B | F16 | 600.46 | 24.16 |
| Llama 2 7B | Q8_0 | 540.15 | 39.97 |
| Llama 2 7B | Q4_0 | 537.6 | 60.99 |
As you can see, the M2 Max shines in its processing speed. It churns through tokens at an impressive rate, regardless of the quantization level. However, the generation speed is significantly lower, especially with the F16 quantization.
Analysis
Here's a breakdown of the data:
- Processing Performance: The M2 Max excels in processing speed, thanks to its powerful CPU cores. This means it can quickly understand and analyze the input text, making it ideal for conversational AI, where rapid processing is crucial.
- Generation Performance: While the generation speed is decent, it falls behind the processing speed. This could lead to a noticeable delay in the model's response time.
- Quantization Impact: The lower the quantization level, the slower the processing, but the faster the generation. This is a common trade-off in LLM optimization. Choosing the right quantization level depends on your specific needs and priorities.
Benchmarking Llama 3 on NVIDIA 3090 x2
Now, let's shift gears to the NVIDIA 3090, often used in a dual setup to amplify its power. We'll test it with the more advanced Llama 3 model.
NVIDIA 3090 x2 Token Speed Generation for Llama 3
| Model | Quantization | Processing (Tokens/Second) | Generation (Tokens/Second) |
|---|---|---|---|
| Llama 3 8B | Q4KM | 4004.14 | 108.07 |
| Llama 3 8B | F16 | 4690.5 | 47.15 |
| Llama 3 70B | Q4KM | 393.89 | 16.29 |
The dual 3090 setup demonstrates impressive processing speeds, particularly with the 8B Llama 3 model. However, the generation speed is again lower than the processing speed, though slightly better than the M2 Max.
Analysis
Let's dissect these results:
- Processing Powerhouse: The dual 3090 setup delivers astonishing processing speeds, ideally suited for complex tasks like code generation, text summarization, and research.
- Generation Speed: The generation speed is good, but it's still significantly lower than the processing speed. This could pose a challenge for real-time applications where fast response times are essential.
- Model Size Impact: The processing speed decreases substantially when scaling up to the 70B Llama 3 model, while the generation speed also suffers. This highlights the challenges of running massive LLMs on a single device.
Comparison of M2 Max and NVIDIA 3090 x2
Now, let's pit these two giants against each other to see who comes out on top in different scenarios.
Performance Comparison
| Feature | Apple M2 Max | NVIDIA 3090_x2 |
|---|---|---|
| Processing Speed (Llama 2 7B) | 540.15 - 600.46 Tokens/Second | N/A |
| Processing Speed (Llama 3 8B) | N/A | 4004.14 - 4690.5 Tokens/Second |
| Generation Speed (Llama 2 7B) | 24.16 - 60.99 Tokens/Second | N/A |
| Generation Speed (Llama 3 8B) | N/A | 47.15 - 108.07 Tokens/Second |
| Power Consumption | Lower | Higher |
| Cost | Lower | Higher |
| Ease of Use | Simpler | More complex |
Key Takeaways:
- Processing Prowess: The NVIDIA 3090 x2 clearly dominates in processing speed, especially with the larger models.
- Generation Speed: While both devices struggle in generation speed, the NVIDIA 3090 x2 edges out the M2 Max, particularly with the larger 8B Llama 3 model.
- Cost and Complexity: The M2 Max is more budget-friendly and easier to use. The NVIDIA 3090 x2 requires significant investment, and setting it up can be more complex.
Use Cases
The choice between these two devices depends heavily on your specific use case:
- Smaller LLMs (Llama 2 7B) and Budget-Friendly Development: The M2 Max offers a great balance of processing and generation speeds while being affordable. It's an excellent choice for smaller LLMs and developers on a budget.
- Larger LLMs (Llama 3 8B) and High-Performance Computing: If you need the maximum processing power for large LLMs, the NVIDIA 3090 x2 is the way to go. This setup is perfect for research, complex applications, and those with a higher budget.
Practical Recommendations
- Quantization Optimization: Experiment with different quantization levels to find the optimal balance between processing and generation speed for your specific LLM and use case.
- Hardware Compatibility: Ensure your chosen hardware is compatible with the LLM framework you plan to use. Different frameworks might have specific hardware requirements.
- Software Optimization: Explore techniques for optimizing the software side of your LLM deployment, like using efficient libraries, fine-tuning, and leveraging distributed training.
FAQ
What are the advantages of using an Apple M2 Max for LLM development?
- Affordability: The M2 Max is a much more budget-friendly option compared to dual NVIDIA 3090s.
- Ease of Use: Setting up and using an M2 Max is generally simpler than configuring a dual NVIDIA 3090 setup.
- Excellent Processing Speed for Smaller LLMs: It offers strong processing power for smaller LLMs like Llama 2 7B.
What are the advantages of using a dual NVIDIA 3090 setup for LLM development?
- Unmatched Processing Power: The dual 3090 setup delivers significantly higher processing speeds, especially for larger LLMs like Llama 3 8B.
- Better Performance for Larger Models: It can handle the processing and generation of larger LLMs more efficiently than the M2 Max.
Is quantization the same as compression?
Quantization is a technique used to reduce the size of an LLM model by representing its weights and activations with fewer bits. While compression also reduces the size of a model, it focuses on reducing the amount of storage space used. Quantization is specifically about reducing the precision of the model's data, which can impact its accuracy but can also improve its speed and memory efficiency.
What are some alternatives to the M2 Max and NVIDIA 3090 x2 for running LLMs?
There are several other options available, including:
- Cloud Services: Leveraging cloud services like Google Colab, Amazon SageMaker, or Azure Machine Learning can provide access to powerful GPUs and other resources without requiring significant upfront investment.
- Other GPUs: Consider exploring other GPUs from NVIDIA or AMD, such as the RTX 40 series or Radeon RX 7000 series, as they offer different performance levels at various price points.
- Specialized hardware: Companies like Cerebras Systems and Graphcore offer specialized hardware designed specifically for accelerating AI workloads, including running LLMs.
Can I run LLMs on my CPU?
Yes, you can run LLMs on your CPU, but they will be much slower than using a GPU. For small LLMs, you might get away with using your CPU, but for larger models, you will need a GPU for reasonable performance.
Keywords
Apple M2 Max, NVIDIA 3090, LLM, AI, Token Speed Generation, Llama 2, Llama 3, Quantization, F16, Q80, Q40, Processing Speed, Generation Speed, Performance Benchmark, Local LLM Development, AI Development, AI Hardware, Machine Learning, Deep Learning, GPU, CPU, Cost, Power Consumption, Use Cases, Software Optimization, Hardware Compatibility, AI Frameworks