Which is Better for AI Development: Apple M2 100gb 10cores or NVIDIA A100 PCIe 80GB? Local LLM Token Speed Generation Benchmark
Introduction
In the world of AI, large language models (LLMs) have become the new stars. These powerful models, trained on massive amounts of data, can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. But running these models locally can feel like a marathon for your computer – especially if you're trying to handle large models like Llama 2 7B.
This article will explore the performance of two popular devices for running LLMs locally: the Apple M2 100GB 10-core and the NVIDIA A100PCIe80GB. We'll dig into their strengths and weaknesses in generating tokens, a key metric for LLM performance, and compare their token speed generation capabilities. We'll also consider the impact of different model sizes and quantization techniques. Imagine this comparison like a race between two supercars, and we'll see which one hits the gas pedal harder when it comes to processing language.
Apple M2 Token Speed Generation: An Overview
Let's start with the Apple M2, Apple's latest and greatest silicon chip. It's known for its impressive power efficiency and strong performance, making it a popular choice for a wide range of applications. The M2 is a powerful processor, but how does it handle the demands of running large language models?
Comparing Apple M2 and NVIDIA A100PCIe80GB Token Speed
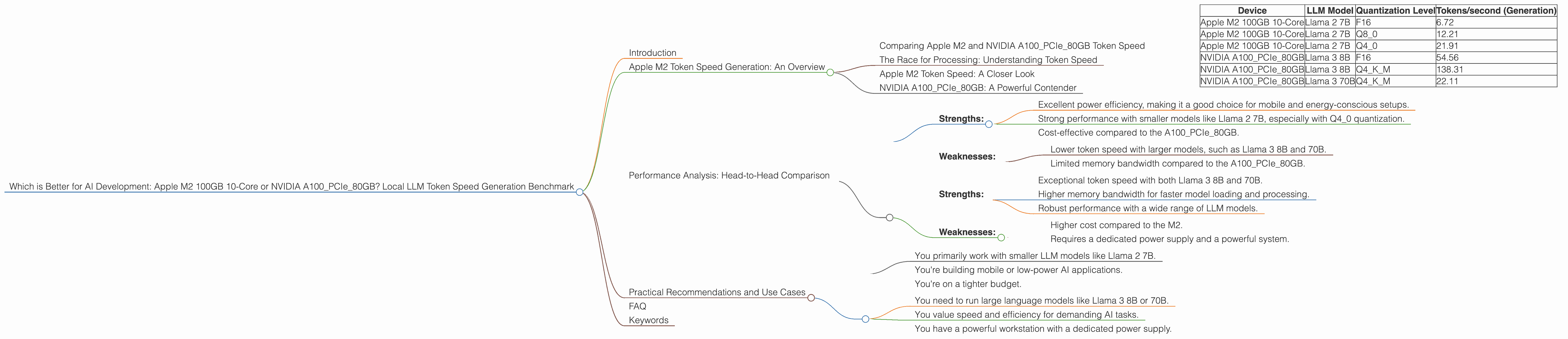
This table showcases the performance of the M2 100GB 10-core compared to the A100PCIe80GB in terms of tokens/second generated for various LLM models and quantization levels:
| Device | LLM Model | Quantization Level | Tokens/second (Generation) |
|---|---|---|---|
| Apple M2 100GB 10-Core | Llama 2 7B | F16 | 6.72 |
| Apple M2 100GB 10-Core | Llama 2 7B | Q8_0 | 12.21 |
| Apple M2 100GB 10-Core | Llama 2 7B | Q4_0 | 21.91 |
| NVIDIA A100PCIe80GB | Llama 3 8B | F16 | 54.56 |
| NVIDIA A100PCIe80GB | Llama 3 8B | Q4KM | 138.31 |
| NVIDIA A100PCIe80GB | Llama 3 70B | Q4KM | 22.11 |
Data Limitations:
- Currently, the data set lacks information on Llama 3 70B with F16 quantization, and the performance of the A100PCIe80GB for Llama 2 7B models.
The Race for Processing: Understanding Token Speed
Token speed is the amount of text a device can process per second, measured in tokens. Think of it as the speed of a car, measured in miles per hour: the higher the token speed, the faster the LLM generates text.
The table reveals that the M2 performs well with Llama 2 7B, particularly when using Q40 quantization. However, the A100PCIe80GB demonstrates a significant speed advantage in processing Llama 3 8B, especially with Q4K_M quantization.
Quantization: Making LLMs More Efficient
Quantization is a technique that reduces the size of LLM models while minimally impacting accuracy. Think of it like compressing a video file. By reducing the file size, you can store more videos on your phone, and your device can process them faster. In our case, quantization reduces the model's memory footprint and allows devices to process it more efficiently.
Apple M2 Token Speed: A Closer Look
The Apple M2 utilizes the M2 Max chip for processing. The performance of the M2 chip is impressive for its size and power consumption, making it a great option for developers looking for a balance between performance and portability. However, the M2 chip doesn't reach the same speed as the NVIDIA A100PCIe80GB, especially when working with larger models.
NVIDIA A100PCIe80GB: A Powerful Contender
The NVIDIA A100PCIe80GB is a high-performance GPU designed for demanding AI workloads. Its impressive memory bandwidth and massive compute power make it well-suited for running large language models. The A100PCIe80GB shines with Llama 3 8B, demonstrating significantly higher token speed than the M2. It excels in generating and processing text, but it comes with a higher price tag and requires a robust system with a dedicated power supply.
Performance Analysis: Head-to-Head Comparison
Apple M2 100GB 10-Core:
Strengths:
- Excellent power efficiency, making it a good choice for mobile and energy-conscious setups.
- Strong performance with smaller models like Llama 2 7B, especially with Q4_0 quantization.
- Cost-effective compared to the A100PCIe80GB.
Weaknesses:
- Lower token speed with larger models, such as Llama 3 8B and 70B.
- Limited memory bandwidth compared to the A100PCIe80GB.
NVIDIA A100PCIe80GB:
Strengths:
- Exceptional token speed with both Llama 3 8B and 70B.
- Higher memory bandwidth for faster model loading and processing.
- Robust performance with a wide range of LLM models.
Weaknesses:
- Higher cost compared to the M2.
- Requires a dedicated power supply and a powerful system.
Practical Recommendations and Use Cases
Choose Apple M2 100GB 10-Core if:
- You primarily work with smaller LLM models like Llama 2 7B.
- You're building mobile or low-power AI applications.
- You're on a tighter budget.
Choose NVIDIA A100PCIe80GB if:
- You need to run large language models like Llama 3 8B or 70B.
- You value speed and efficiency for demanding AI tasks.
- You have a powerful workstation with a dedicated power supply.
FAQ
1. What are LLMs, and why are they important?
LLMs are powerful AI models capable of generating text, translating languages, writing different kinds of creative content, and answering your questions in an informative way. They are transforming how we interact with computers and are essential for applications like chatbots, AI assistants, and content creation tools.
2. What are the advantages of running LLMs locally?
Running LLMs locally provides greater privacy and control over your data. It also allows you to access them offline, making your applications more reliable.
3. What is quantization, and how does it affect LLM performance?
Quantization is a technique that reduces the size of LLM models while minimally impacting accuracy by reducing the number of bits needed to represent the model's data. This results in faster processing times and lower memory usage.
4. Which device is best for beginners?
For beginners, the Apple M2 100GB 10-core offers a good balance between performance and cost. It's well-suited for experimenting with smaller LLM models and developing basic AI applications.
5. How do I choose the right device for my AI development needs?
Consider the size of the LLM models you plan to use, your budget, and the power requirements of your application. The M2 is a good choice for smaller models and mobile applications, while the A100PCIe80GB is ideal for larger models and demanding AI workloads.
Keywords
Apple M2, M2 Max, NVIDIA A100PCIe80GB, LLM, large language model, Llama 2, Llama 3, token speed, tokens/second, performance, benchmark, quantization, F16, Q40, Q80, Q4KM, AI development, AI applications, inference, CPU, GPU, local, cloud, power efficiency, memory bandwidth, cost, use cases, developers, geeks, AI enthusiasts, AI projects, AI tools, AI trends