Apple M3 Pro 150gb 14cores vs. NVIDIA RTX A6000 48GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The world of Large Language Models (LLMs) is rapidly evolving, with new models and applications emerging constantly. As LLMs become more powerful, they require more computational resources to run effectively. Choosing the right hardware for your LLM needs can be crucial - impacting speed, efficiency, and overall experience. This article will compare the performance of two popular devices - the Apple M3 Pro 150GB 14cores and the NVIDIA RTX A6000 48GB - specifically focusing on their token generation speed for various LLM models.
Imagine you're building a chatbot or a content generation tool powered by an LLM. You want your users to get quick and seamless responses, not wait endlessly. Your choice of hardware can make or break this experience. This article will help you navigate this choice by breaking down the performance differences and highlighting the pros and cons of each device in the context of LLMs.
Benchmark Analysis: Apple M3 Pro 150GB 14cores vs. NVIDIA RTX A6000 48GB
Methodology and Data Source
The benchmark data used in this analysis was sourced from the following publicly available repositories:
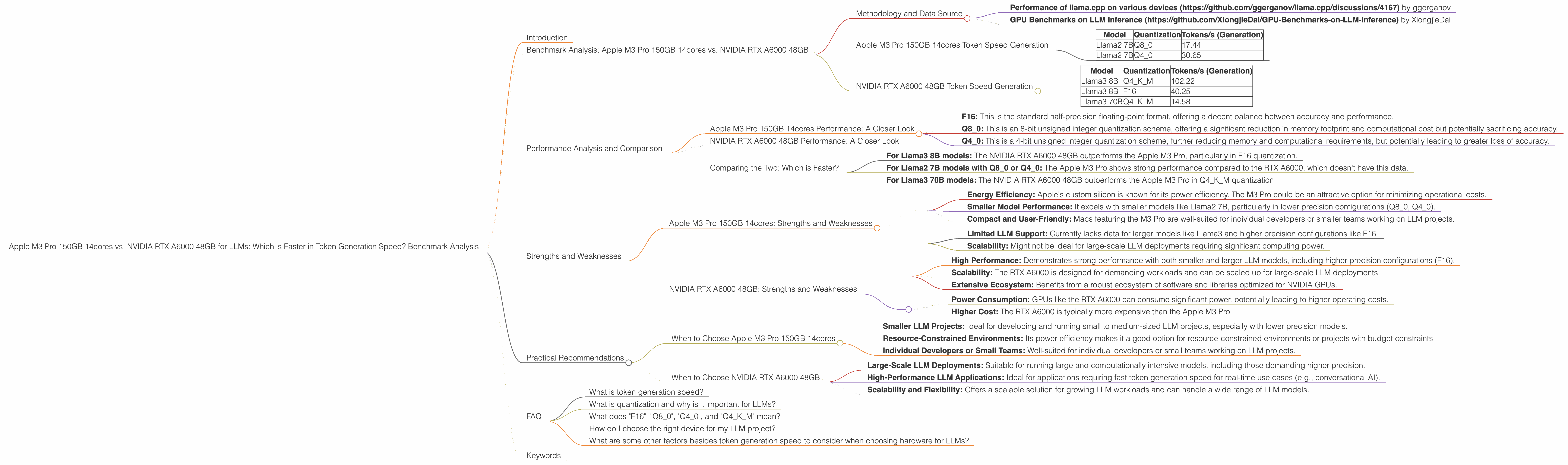
- Performance of llama.cpp on various devices (https://github.com/ggerganov/llama.cpp/discussions/4167) by ggerganov
- GPU Benchmarks on LLM Inference (https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference) by XiongjieDai
The analysis focuses on token generation speed expressed in tokens per second (tokens/s). The benchmark data includes different LLM models in various configurations, including different quantization levels (F16, Q80, Q40, Q4KM) for the Apple M3 Pro. We'll delve into the meaning of these configurations later in the article.
Apple M3 Pro 150GB 14cores Token Speed Generation
| Model | Quantization | Tokens/s (Generation) |
|---|---|---|
| Llama2 7B | Q8_0 | 17.44 |
| Llama2 7B | Q4_0 | 30.65 |
Note: The Apple M3 Pro 150GB 14cores has no data available for the Llama2 7B model in F16 quantization and no data available for Llama3 models.
NVIDIA RTX A6000 48GB Token Speed Generation
| Model | Quantization | Tokens/s (Generation) |
|---|---|---|
| Llama3 8B | Q4KM | 102.22 |
| Llama3 8B | F16 | 40.25 |
| Llama3 70B | Q4KM | 14.58 |
Note: The NVIDIA RTX A6000 48GB has no data available for the Llama3 70B model in F16 quantization and no data available for Llama2 models.
Performance Analysis and Comparison
Apple M3 Pro 150GB 14cores Performance: A Closer Look
The Apple M3 Pro 150GB 14cores shows impressive performance in processing Llama2 7B models with Q80 and Q40 quantization. However, it's important to note the absence of data for both F16 quantization and Llama3 models. This suggests that the M3 Pro might be suitable for smaller, less demanding LLM tasks, particularly with lower precision models like Llama2 7B.
Let's understand the different quantization levels:
- F16: This is the standard half-precision floating-point format, offering a decent balance between accuracy and performance.
- Q8_0: This is an 8-bit unsigned integer quantization scheme, offering a significant reduction in memory footprint and computational cost but potentially sacrificing accuracy.
- Q4_0: This is a 4-bit unsigned integer quantization scheme, further reducing memory and computational requirements, but potentially leading to greater loss of accuracy.
The Apple M3 Pro's strong performance with Q80 and Q40 quantization illustrates its ability to handle lower-precision models efficiently. This could be beneficial for tasks where speed and resource efficiency are prioritized over absolute accuracy.
NVIDIA RTX A6000 48GB Performance: A Closer Look
The NVIDIA RTX A6000 48GB excels with both Llama3 8B and Llama3 70B models, demonstrating its ability to handle large and computationally intensive models. It outperforms the Apple M3 Pro in F16 quantization for Llama3 8B, showcasing its strength in handling higher-precision models.
The RTX A6000's performance with Q4KM quantization for both Llama3 models highlights its versatility in managing different precision levels. This flexibility makes it a strong candidate for a wider range of LLM applications.
Comparing the Two: Which is Faster?
Direct comparison is tricky since the benchmark data doesn't cover exactly the same models and quantization levels. Nevertheless, we can draw some conclusions based on the available information:
- For Llama3 8B models: The NVIDIA RTX A6000 48GB outperforms the Apple M3 Pro, particularly in F16 quantization.
- For Llama2 7B models with Q80 or Q40: The Apple M3 Pro shows strong performance compared to the RTX A6000, which doesn't have this data.
- For Llama3 70B models: The NVIDIA RTX A6000 48GB outperforms the Apple M3 Pro in Q4KM quantization.
It's safe to say that the NVIDIA RTX A6000 48GB is generally faster for larger, more complex LLM models, especially when higher precision is desired. The Apple M3 Pro holds its ground with smaller models, particularly when lower precision is acceptable.
Strengths and Weaknesses
Apple M3 Pro 150GB 14cores: Strengths and Weaknesses
Strengths:
- Energy Efficiency: Apple's custom silicon is known for its power efficiency. The M3 Pro could be an attractive option for minimizing operational costs.
- Smaller Model Performance: It excels with smaller models like Llama2 7B, particularly in lower precision configurations (Q80, Q40).
- Compact and User-Friendly: Macs featuring the M3 Pro are well-suited for individual developers or smaller teams working on LLM projects.
Weaknesses:
- Limited LLM Support: Currently lacks data for larger models like Llama3 and higher precision configurations like F16.
- Scalability: Might not be ideal for large-scale LLM deployments requiring significant computing power.
NVIDIA RTX A6000 48GB: Strengths and Weaknesses
Strengths:
- High Performance: Demonstrates strong performance with both smaller and larger LLM models, including higher precision configurations (F16).
- Scalability: The RTX A6000 is designed for demanding workloads and can be scaled up for large-scale LLM deployments.
- Extensive Ecosystem: Benefits from a robust ecosystem of software and libraries optimized for NVIDIA GPUs.
Weaknesses:
- Power Consumption: GPUs like the RTX A6000 can consume significant power, potentially leading to higher operating costs.
- Higher Cost: The RTX A6000 is typically more expensive than the Apple M3 Pro.
Practical Recommendations
When to Choose Apple M3 Pro 150GB 14cores
- Smaller LLM Projects: Ideal for developing and running small to medium-sized LLM projects, especially with lower precision models.
- Resource-Constrained Environments: Its power efficiency makes it a good option for resource-constrained environments or projects with budget constraints.
- Individual Developers or Small Teams: Well-suited for individual developers or small teams working on LLM projects.
When to Choose NVIDIA RTX A6000 48GB
- Large-Scale LLM Deployments: Suitable for running large and computationally intensive models, including those demanding higher precision.
- High-Performance LLM Applications: Ideal for applications requiring fast token generation speed for real-time use cases (e.g., conversational AI).
- Scalability and Flexibility: Offers a scalable solution for growing LLM workloads and can handle a wide range of LLM models.
FAQ
What is token generation speed?
Token generation speed refers to the rate at which an LLM can produce tokens, the building blocks of text. Higher token generation speed means faster processing and response times for your LLM applications.
What is quantization and why is it important for LLMs?
Quantization is a technique used to reduce the size of a model by representing its weights and activations with lower precision numbers (e.g., 8-bit instead of 32-bit). This can significantly reduce memory footprint and computational overhead, leading to faster inference speeds. However, it can also impact accuracy, so choosing the right quantization level is crucial.
What does "F16", "Q80", "Q40", and "Q4KM" mean?
These are different levels of quantization used in LLMs. "F16" stands for half-precision floating-point format, "Q80" and "Q40" stand for 8-bit and 4-bit unsigned integer quantization schemes, while "Q4KM" is a specialized 4-bit quantization scheme for the Llama family of models.
How do I choose the right device for my LLM project?
Consider the size of your LLM model, the desired level of precision, the available computing resources, and your budget. If you're working with smaller models and prioritize efficiency, the Apple M3 Pro could be a good choice. For larger, more complex models and high-performance applications, the NVIDIA RTX A6000 might be more suitable.
What are some other factors besides token generation speed to consider when choosing hardware for LLMs?
Other factors include memory capacity, power consumption, cooling solutions, and the availability of software and libraries optimized for the chosen device.
Keywords
LLM, Large Language Model, token generation speed, Apple M3 Pro, NVIDIA RTX A6000, Llama2, Llama3, F16, Q80, Q40, Q4KM, quantization, benchmark, performance, comparison, strengths, weaknesses, practical recommendations, GPU, CPU, AI, machine learning, deep learning, natural language processing, NLP