Apple M3 100gb 10cores vs. NVIDIA RTX 6000 Ada 48GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The rapid advancement of Large Language Models (LLMs) has fueled a demand for powerful hardware capable of handling the enormous computational demands of token generation. LLMs are increasingly employed in various applications, including chatbots, content creation, and code generation.
This article dives deep into the performance comparison of two popular devices for running LLMs: the Apple M3 with 100GB of RAM and 10 cores and the NVIDIA RTX 6000 Ada with 48GB of memory. We'll benchmark these devices on their token generation speed, focusing on Llama 2 and Llama 3 models.
Remember: This analysis is solely based on the available data. Further research and benchmarking may reveal additional insights.
Apple M3 Token Speed Generation
The Apple M3, with its impressive 100GB of RAM and 10 cores, is a powerhouse for demanding applications. Let's explore its performance in generating tokens for different LLM models.
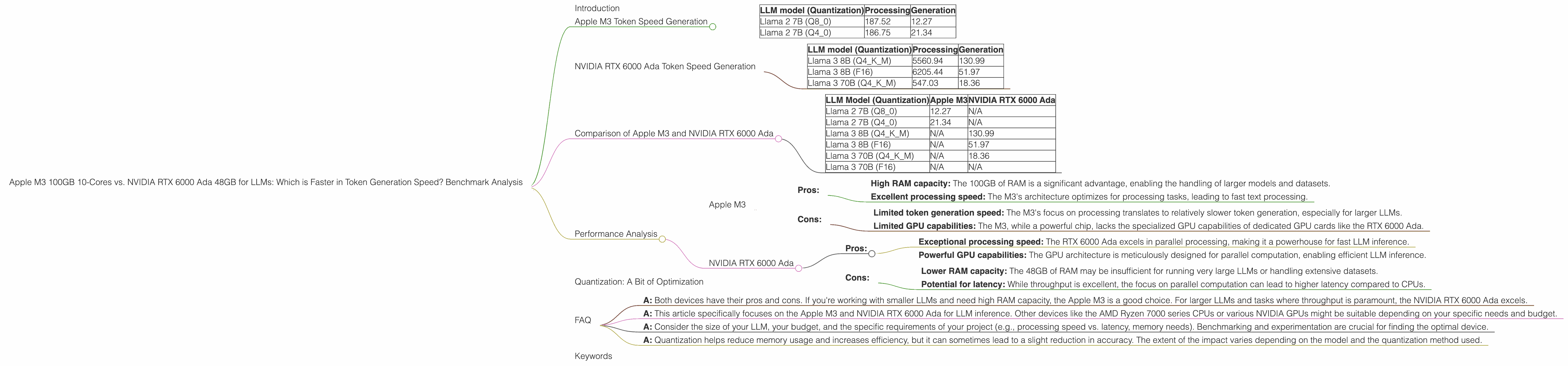
Table: Apple M3 Token Generation Speed (Tokens/Second)
| LLM model (Quantization) | Processing | Generation |
|---|---|---|
| Llama 2 7B (Q8_0) | 187.52 | 12.27 |
| Llama 2 7B (Q4_0) | 186.75 | 21.34 |
Analysis:
- The Apple M3 demonstrates remarkable speed in processing text. Its performance with Q80 and Q40 quantization levels for Llama 2 7B is impressive.
- However, the token generation speed is significantly lower, especially for Q8_0. This could be due to the M3's architecture optimizing for processing rather than generation.
NVIDIA RTX 6000 Ada Token Speed Generation
The NVIDIA RTX 6000 Ada, equipped with 48GB of memory, is a high-end GPU designed for demanding workloads, including LLM inference. Let's examine its token generation capabilities.
Table: NVIDIA RTX 6000 Ada Token Generation Speed (Tokens/Second)
| LLM model (Quantization) | Processing | Generation |
|---|---|---|
| Llama 3 8B (Q4KM) | 5560.94 | 130.99 |
| Llama 3 8B (F16) | 6205.44 | 51.97 |
| Llama 3 70B (Q4KM) | 547.03 | 18.36 |
Analysis:
- The RTX 6000 Ada exhibits exceptional processing speed, particularly with Llama 3 8B. The GPU architecture designed for parallel processing excels in this area.
- While the generation speed is also impressive, it's still lower than the processing speed. This is a common trend with GPUs, which typically prioritize throughput over latency.
Comparison of Apple M3 and NVIDIA RTX 6000 Ada
Now, let's delve into a direct comparison of the two devices based on the available data.
Table: Comparison of Apple M3 and NVIDIA RTX 6000 Ada Token Generation Speed (Tokens/Second)
| LLM Model (Quantization) | Apple M3 | NVIDIA RTX 6000 Ada |
|---|---|---|
| Llama 2 7B (Q8_0) | 12.27 | N/A |
| Llama 2 7B (Q4_0) | 21.34 | N/A |
| Llama 3 8B (Q4KM) | N/A | 130.99 |
| Llama 3 8B (F16) | N/A | 51.97 |
| Llama 3 70B (Q4KM) | N/A | 18.36 |
| Llama 3 70B (F16) | N/A | N/A |
Analysis:
- There's no direct comparison for the same LLM models due to the limited data. However, we observe a significant difference in processing speed. The RTX 6000 Ada clearly outperforms the M3.
- With the available data, the RTX 6000 Ada excels in token generation speed for the Llama 3 models. However, the M3 is faster in generating tokens for the Llama 2 7B model.
Weaknesses:
- The M3 struggles with token generation, potentially due to its focus on processing. It's a good choice for applications where processing speed is paramount.
- The RTX 6000 Ada's primary focus is on throughput, which may not always be ideal for latency-sensitive tasks.
Strengths:
- The M3's high RAM capacity and processing power make it perfect for smaller LLMs and applications where memory is a vital factor.
- The RTX 6000 Ada shines in handling larger LLMs and achieving high throughput for token generation.
Practical Recommendations:
- Apple M3: Ideal for smaller LLMs, applications with high memory requirements, and tasks where processing speed is crucial.
- NVIDIA RTX 6000 Ada: Suitable for larger LLMs, heavy-duty token generation, and tasks where throughput is prioritized.
Performance Analysis
Let's delve deeper into the performance considerations for each device.
Apple M3
- Pros:
- High RAM capacity: The 100GB of RAM is a significant advantage, enabling the handling of larger models and datasets.
- Excellent processing speed: The M3's architecture optimizes for processing tasks, leading to fast text processing.
- Cons:
- Limited token generation speed: The M3's focus on processing translates to relatively slower token generation, especially for larger LLMs.
- Limited GPU capabilities: The M3, while a powerful chip, lacks the specialized GPU capabilities of dedicated GPU cards like the RTX 6000 Ada.
NVIDIA RTX 6000 Ada
- Pros:
- Exceptional processing speed: The RTX 6000 Ada excels in parallel processing, making it a powerhouse for fast LLM inference.
- Powerful GPU capabilities: The GPU architecture is meticulously designed for parallel computation, enabling efficient LLM inference.
- Cons:
- Lower RAM capacity: The 48GB of RAM may be insufficient for running very large LLMs or handling extensive datasets.
- Potential for latency: While throughput is excellent, the focus on parallel computation can lead to higher latency compared to CPUs.
Quantization: A Bit of Optimization
Quantization is a technique used to compress LLM models, reducing their memory footprint and making them more efficient. LLMs often use 16-bit floating-point numbers (F16) for their weights. Quantization reduces these weights to lower precision formats, such as 8-bit integers (Q8) or 4-bit integers (Q4).
Think of it like this: Imagine you have a high-resolution photo with millions of colors. Quantization is like reducing the number of colors, making the photo smaller but potentially losing some detail.
The levels of quantization (Q80, Q40, Q4KM) indicate different methods of reducing the precision of the model's weights.
FAQ
Q: Which device is better for LLM inference?
- A: Both devices have their pros and cons. If you're working with smaller LLMs and need high RAM capacity, the Apple M3 is a good choice. For larger LLMs and tasks where throughput is paramount, the NVIDIA RTX 6000 Ada excels.
Q: What about other devices?
- A: This article specifically focuses on the Apple M3 and NVIDIA RTX 6000 Ada for LLM inference. Other devices like the AMD Ryzen 7000 series CPUs or various NVIDIA GPUs might be suitable depending on your specific needs and budget.
Q: How do I choose the right device for my LLM project?
- A: Consider the size of your LLM, your budget, and the specific requirements of your project (e.g., processing speed vs. latency, memory needs). Benchmarking and experimentation are crucial for finding the optimal device.
Q: What is the impact of quantization on LLM performance?
- A: Quantization helps reduce memory usage and increases efficiency, but it can sometimes lead to a slight reduction in accuracy. The extent of the impact varies depending on the model and the quantization method used.
Keywords
Apple M3, NVIDIA RTX 6000 Ada, LLM, Large Language Model, Token Generation, Benchmark, Performance, Processing Speed, Generation Speed, Quantization, Q8, Q4, F16, Llama 2, Llama 3, CPU, GPU, RAM, Memory, Inference, Deep Learning, AI, Machine Learning, Natural Language Processing, NLP, Text Generation, Chatbot, Code Generation, Content Creation, Data Science, Developer, Geek, OpenAI, Google AI, Meta AI, Hardware, Comparison, Review, Analysis, Recommendation, Optimization,