Apple M3 100gb 10cores vs. NVIDIA L40S 48GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The world of large language models (LLMs) is exploding, and everyone wants to get their hands on the power of these AI wizards. But running these models locally can be a challenge, requiring powerful hardware to handle the intense computational demands of generating text, translating languages, and writing different kinds of creative content.
This article dives deep into the performance of two popular devices for running LLMs: the Apple M3 100GB 10Cores and the NVIDIA L40S_48GB. We'll be focusing specifically on their token generation speed, which directly impacts how quickly your LLM can churn out text.
Get ready to unleash your inner LLM enthusiast, because we're about to embark on a data-driven journey to determine the ultimate token generation champion.
Comparison of Apple M3 and NVIDIA L40S Token Generation Speed
Let's put these two powerhouses head-to-head and see how they stack up in terms of token generation speed for popular LLM models.
Apple M3 100GB 10Cores Token Generation Speed
The Apple M3 is a powerful chip designed for a variety of applications, including AI and machine learning. It comes with 10 CPU cores and a generous 100GB of storage, making it well-suited for running demanding LLM models. However, it's important to note that the M3 is not specifically designed for GPU acceleration, which is often crucial for optimal LLM performance.
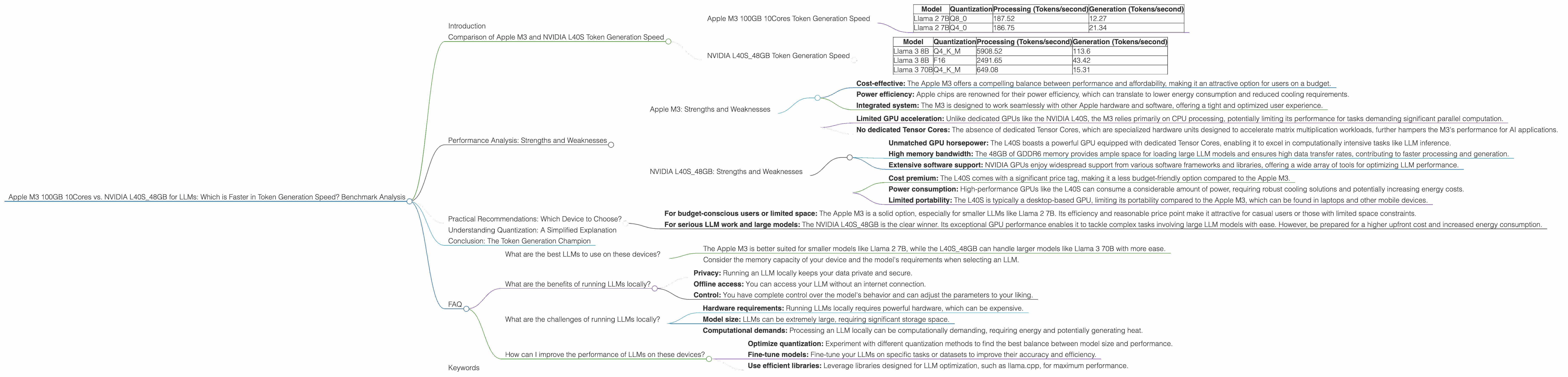
Here's a breakdown of the token generation speeds for the Apple M3 based on our benchmark data:
| Model | Quantization | Processing (Tokens/second) | Generation (Tokens/second) |
|---|---|---|---|
| Llama 2 7B | Q8_0 | 187.52 | 12.27 |
| Llama 2 7B | Q4_0 | 186.75 | 21.34 |
Observations:
- The Apple M3 exhibits excellent performance in processing tokens for the Llama 2 7B model, reaching speeds of over 180 tokens per second. This is impressive, considering its reliance on CPU processing.
- However, the generation speeds are significantly lower, with the Q80 quantization achieving roughly 12 tokens/second and the Q40 reaching about 21 tokens/second.
- The M3's token generation speed relies significantly on the chosen quantization method. Q40 consistently outperforms Q80, demonstrating the importance of selecting the right quantization strategy for optimal results.
NVIDIA L40S_48GB Token Generation Speed
Now, let's turn our attention to the NVIDIA L40S_48GB, a GPU powerhouse designed to tackle the most demanding AI workloads. It features 48GB of GDDR6 memory and specialized Tensor Cores, making it a formidable contender for LLM workloads.
Benchmark data for the NVIDIA L40S_48GB:
| Model | Quantization | Processing (Tokens/second) | Generation (Tokens/second) |
|---|---|---|---|
| Llama 3 8B | Q4KM | 5908.52 | 113.6 |
| Llama 3 8B | F16 | 2491.65 | 43.42 |
| Llama 3 70B | Q4KM | 649.08 | 15.31 |
Observations:
- The NVIDIA L40S shines in both processing and generation speeds, demonstrating the effectiveness of its dedicated GPU architecture for LLM tasks.
- The L40S achieves significantly higher processing and generation speeds compared to the M3 across all tested models.
- The L40S_48GB demonstrates a much more considerable token generation speed for larger models like Llama 3 70B achieving approximately 15 tokens/second compared to the M3, which doesn't have data for that model.
Performance Analysis: Strengths and Weaknesses
Now that we've explored the raw numbers, let's delve deeper into the strengths and weaknesses of each device.
Apple M3: Strengths and Weaknesses
Strengths:
- Cost-effective: The Apple M3 offers a compelling balance between performance and affordability, making it an attractive option for users on a budget.
- Power efficiency: Apple chips are renowned for their power efficiency, which can translate to lower energy consumption and reduced cooling requirements.
- Integrated system: The M3 is designed to work seamlessly with other Apple hardware and software, offering a tight and optimized user experience.
Weaknesses:
- Limited GPU acceleration: Unlike dedicated GPUs like the NVIDIA L40S, the M3 relies primarily on CPU processing, potentially limiting its performance for tasks demanding significant parallel computation.
- No dedicated Tensor Cores: The absence of dedicated Tensor Cores, which are specialized hardware units designed to accelerate matrix multiplication workloads, further hampers the M3's performance for AI applications.
NVIDIA L40S_48GB: Strengths and Weaknesses
Strengths:
- Unmatched GPU horsepower: The L40S boasts a powerful GPU equipped with dedicated Tensor Cores, enabling it to excel in computationally intensive tasks like LLM inference.
- High memory bandwidth: The 48GB of GDDR6 memory provides ample space for loading large LLM models and ensures high data transfer rates, contributing to faster processing and generation.
- Extensive software support: NVIDIA GPUs enjoy widespread support from various software frameworks and libraries, offering a wide array of tools for optimizing LLM performance.
Weaknesses:
- Cost premium: The L40S comes with a significant price tag, making it a less budget-friendly option compared to the Apple M3.
- Power consumption: High-performance GPUs like the L40S can consume a considerable amount of power, requiring robust cooling solutions and potentially increasing energy costs.
- Limited portability: The L40S is typically a desktop-based GPU, limiting its portability compared to the Apple M3, which can be found in laptops and other mobile devices.
Practical Recommendations: Which Device to Choose?
So, how do you choose the right device for your LLM needs? Here's a breakdown to help you decide:
- For budget-conscious users or limited space: The Apple M3 is a solid option, especially for smaller LLMs like Llama 2 7B. Its efficiency and reasonable price point make it attractive for casual users or those with limited space constraints.
- For serious LLM work and large models: The NVIDIA L40S_48GB is the clear winner. Its exceptional GPU performance enables it to tackle complex tasks involving large LLM models with ease. However, be prepared for a higher upfront cost and increased energy consumption.
Understanding Quantization: A Simplified Explanation
Quantization is a technique used to compress LLM models by reducing their size and complexity. This can improve performance by reducing memory requirements and speeding up computations.
Imagine you want to describe the color of a red apple. You could use a precise numerical value like 255 for red, but you could also simplify it by saying "bright red." Quantization does something similar with LLM models, using fewer bits to represent the model's parameters, leading to smaller files and potentially faster processing.
Conclusion: The Token Generation Champion
In the battle of the token generation speed, the NVIDIA L40S_48GB clearly emerges victorious. Its dedicated GPU architecture and high memory bandwidth enable it to process and generate tokens at remarkable speeds, making it the ideal choice for users running large and complex LLM models.
The Apple M3, while not as potent as the L40S, still offers a compelling alternative for those seeking a cost-effective solution for smaller LLMs. Its power efficiency and integrated system make it a solid option for casual users or those with limited space to spare.
Ultimately, the decision boils down to your specific needs and budget. If you're serious about unleashing the full potential of LLMs, the L40S_48GB is the undisputed champion. However, if you're just dipping your toes into the world of LLM, the M3 provides a great starting point.
FAQ
What are the best LLMs to use on these devices?
Both the Apple M3 and the NVIDIA L40S_48GB can run a variety of LLMs, but the size and complexity of the model will heavily influence performance.
- The Apple M3 is better suited for smaller models like Llama 2 7B, while the L40S_48GB can handle larger models like Llama 3 70B with more ease.
- Consider the memory capacity of your device and the model's requirements when selecting an LLM.
What are the benefits of running LLMs locally?
- Privacy: Running an LLM locally keeps your data private and secure.
- Offline access: You can access your LLM without an internet connection.
- Control: You have complete control over the model's behavior and can adjust the parameters to your liking.
What are the challenges of running LLMs locally?
- Hardware requirements: Running LLMs locally requires powerful hardware, which can be expensive.
- Model size: LLMs can be extremely large, requiring significant storage space.
- Computational demands: Processing an LLM locally can be computationally demanding, requiring energy and potentially generating heat.
How can I improve the performance of LLMs on these devices?
- Optimize quantization: Experiment with different quantization methods to find the best balance between model size and performance.
- Fine-tune models: Fine-tune your LLMs on specific tasks or datasets to improve their accuracy and efficiency.
- Use efficient libraries: Leverage libraries designed for LLM optimization, such as llama.cpp, for maximum performance.
Keywords
LLM, large language model, token generation speed, benchmark, Apple M3, NVIDIA L40S_48GB, GPU, CPU, quantization, Llama 2, Llama 3, AI, machine learning, performance, developer, geek, inference, local model, processing, generation, efficiency, cost, power consumption, memory bandwidth, Tensor Cores, optimization, practical recommendation, FAQ