Apple M3 100gb 10cores vs. NVIDIA A100 SXM 80GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The world of large language models (LLMs) is rapidly evolving, with new models and applications emerging every day. As LLMs become more sophisticated, the need for powerful hardware to run them efficiently becomes increasingly important. If you're a developer working with LLMs, you're likely considering the best hardware for your needs.
This deep dive compares the performance of two popular devices, the Apple M3 100GB 10-core and the NVIDIA A100SXM80GB, in token generation speed when running various LLM models. Buckle up, it's time for a high-speed comparison!
Apple M3 Token Generation Speed
Let's start with the Apple M3. It boasts a generous 100GB of memory and 10 cores, making it an attractive option for running LLMs locally (that's right, no cloud needed!). However, the M3 is a bit of a newcomer to the LLM scene, so let's see how it performs.
Apple M3 Performance with Llama 2 7B
We're focusing on the Llama 2 7B model, a popular choice due to its balance of size and capability. Here's the breakdown of the M3's performance based on the Llama 2 7B:
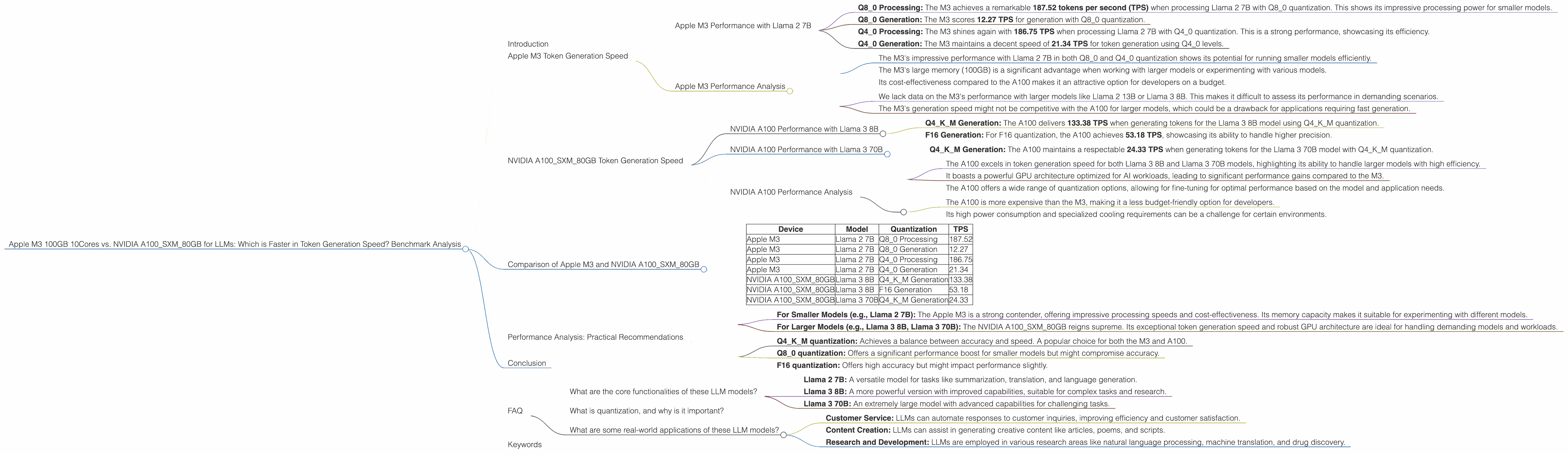
- Q80 Processing: The M3 achieves a remarkable 187.52 tokens per second (TPS) when processing Llama 2 7B with Q80 quantization. This shows its impressive processing power for smaller models.
- Q80 Generation: The M3 scores 12.27 TPS for generation with Q80 quantization.
- Q40 Processing: The M3 shines again with 186.75 TPS when processing Llama 2 7B with Q40 quantization. This is a strong performance, showcasing its efficiency.
- Q40 Generation: The M3 maintains a decent speed of 21.34 TPS for token generation using Q40 levels.
Apple M3 Performance Analysis
Strengths:
- The M3's impressive performance with Llama 2 7B in both Q80 and Q40 quantization shows its potential for running smaller models efficiently.
- The M3's large memory (100GB) is a significant advantage when working with larger models or experimenting with various models.
- Its cost-effectiveness compared to the A100 makes it an attractive option for developers on a budget.
Weaknesses:
- We lack data on the M3's performance with larger models like Llama 2 13B or Llama 3 8B. This makes it difficult to assess its performance in demanding scenarios.
- The M3's generation speed might not be competitive with the A100 for larger models, which could be a drawback for applications requiring fast generation.
NVIDIA A100SXM80GB Token Generation Speed
The NVIDIA A100SXM80GB is a powerful GPU designed for high-performance computing, making it a serious contender for LLM work. Let's examine its token generation performance:
NVIDIA A100 Performance with Llama 3 8B
The A100 demonstrates its prowess with the Llama 3 8B model:
- Q4KM Generation: The A100 delivers 133.38 TPS when generating tokens for the Llama 3 8B model using Q4KM quantization.
- F16 Generation: For F16 quantization, the A100 achieves 53.18 TPS, showcasing its ability to handle higher precision.
NVIDIA A100 Performance with Llama 3 70B
We also have data for the impressive Llama 3 70B model:
- Q4KM Generation: The A100 maintains a respectable 24.33 TPS when generating tokens for the Llama 3 70B model with Q4KM quantization.
NVIDIA A100 Performance Analysis
Strengths:
- The A100 excels in token generation speed for both Llama 3 8B and Llama 3 70B models, highlighting its ability to handle larger models with high efficiency.
- It boasts a powerful GPU architecture optimized for AI workloads, leading to significant performance gains compared to the M3.
- The A100 offers a wide range of quantization options, allowing for fine-tuning for optimal performance based on the model and application needs.
Weaknesses:
- The A100 is more expensive than the M3, making it a less budget-friendly option for developers.
- Its high power consumption and specialized cooling requirements can be a challenge for certain environments.
Comparison of Apple M3 and NVIDIA A100SXM80GB
Let's summarize the performance of both devices through a simple table for clarity:
| Device | Model | Quantization | TPS |
|---|---|---|---|
| Apple M3 | Llama 2 7B | Q8_0 Processing | 187.52 |
| Apple M3 | Llama 2 7B | Q8_0 Generation | 12.27 |
| Apple M3 | Llama 2 7B | Q4_0 Processing | 186.75 |
| Apple M3 | Llama 2 7B | Q4_0 Generation | 21.34 |
| NVIDIA A100SXM80GB | Llama 3 8B | Q4KM Generation | 133.38 |
| NVIDIA A100SXM80GB | Llama 3 8B | F16 Generation | 53.18 |
| NVIDIA A100SXM80GB | Llama 3 70B | Q4KM Generation | 24.33 |
Performance Analysis: Practical Recommendations
- For Smaller Models (e.g., Llama 2 7B): The Apple M3 is a strong contender, offering impressive processing speeds and cost-effectiveness. Its memory capacity makes it suitable for experimenting with different models.
- For Larger Models (e.g., Llama 3 8B, Llama 3 70B): The NVIDIA A100SXM80GB reigns supreme. Its exceptional token generation speed and robust GPU architecture are ideal for handling demanding models and workloads.
Quantization: A Key Factor:
- Q4KM quantization: Achieves a balance between accuracy and speed. A popular choice for both the M3 and A100.
- Q8_0 quantization: Offers a significant performance boost for smaller models but might compromise accuracy.
- F16 quantization: Offers high accuracy but might impact performance slightly.
Think of it this way:
Imagine you're building a house. The M3 is like a compact, efficient construction crew that's great for small projects. The A100 is like a heavy-duty construction company with a powerful crane, perfect for building skyscrapers!
Conclusion
Both the Apple M3 and NVIDIA A100SXM80GB offer compelling solutions for running LLMs locally. The M3 excels with smaller models, providing a cost-effective and efficient option. However, for handling larger models and demanding workloads, the A100's superior performance and GPU architecture are unmatched. Ultimately, the best choice depends on your specific needs, budget, and the LLM models you intend to work with.
FAQ
What are the core functionalities of these LLM models?
- Llama 2 7B: A versatile model for tasks like summarization, translation, and language generation.
- Llama 3 8B: A more powerful version with improved capabilities, suitable for complex tasks and research.
- Llama 3 70B: An extremely large model with advanced capabilities for challenging tasks.
What is quantization, and why is it important?
Quantization is a technique that reduces the precision of numbers used in a LLM, making it smaller and faster to run. The types of quantization mentioned (Q80, Q4K_M, F16) represent different levels of precision.
What are some real-world applications of these LLM models?
- Customer Service: LLMs can automate responses to customer inquiries, improving efficiency and customer satisfaction.
- Content Creation: LLMs can assist in generating creative content like articles, poems, and scripts.
- Research and Development: LLMs are employed in various research areas like natural language processing, machine translation, and drug discovery.
Keywords
Apple M3, NVIDIA A100SXM80GB, LLM, Token Generation Speed, Llama 2 7B, Llama 3 8B, Llama 3 70B, Quantization, Performance Comparison, GPU, CPU, AI, Machine Learning, Natural Language Processing, Development, Research, Applications, Benchmark Analysis.