Apple M3 100gb 10cores vs. NVIDIA 4070 Ti 12GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
Choosing the right hardware for running Large Language Models (LLMs) can be a daunting task, especially with the constant influx of new devices and software advancements. In this article, we'll dive deep into the performance of two popular contenders: the Apple M3 100GB 10 Cores and the NVIDIA 4070 Ti 12GB. Our focus will be on their token generation speeds across different LLM models.
Tokenization breaks down text into smaller units, allowing LLMs to process and understand language. Token generation speed is crucial for smooth and responsive interactions with LLMs, whether you're building a chatbot, generating creative content, or performing data analysis.
Apple M3 Token Speed Generation: A Closer Look
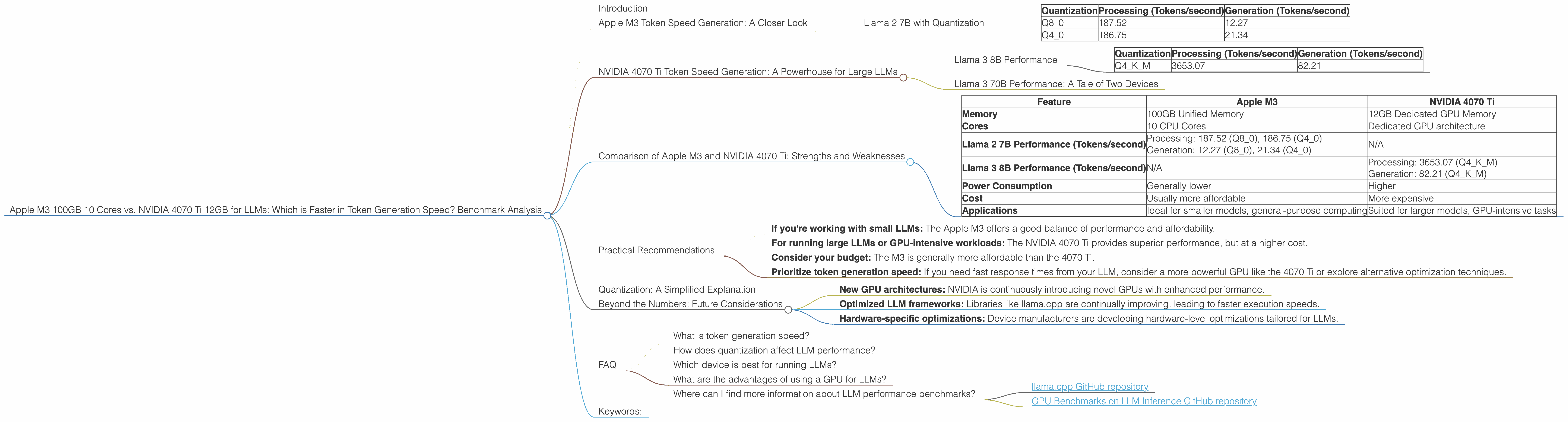
The Apple M3 boasts a remarkable 100GB of unified memory and 10 powerful cores. This combination makes it a formidable force for handling complex LLM tasks. Let's analyze its performance on the Llama 2 7B model with varying quantization levels:
Llama 2 7B with Quantization
The Apple M3 excels in processing Llama 2 7B models, with particularly impressive speeds for Q80 and Q40 quantization:
| Quantization | Processing (Tokens/second) | Generation (Tokens/second) |
|---|---|---|
| Q8_0 | 187.52 | 12.27 |
| Q4_0 | 186.75 | 21.34 |
Note: Data for Llama 2 7B with F16 precision is unavailable for the M3.
The Q8_0 setting achieves a remarkable 187.52 tokens/second in processing, demonstrating the M3's efficiency in handling smaller data sizes. However, its generation speed of 12.27 tokens/second is considerably slower.
Switching to Q4_0 boosts generation speed to 21.34 tokens/second, but it's still significantly lower than the processing speed. This suggests a potential bottleneck in the token generation process on the M3.
NVIDIA 4070 Ti Token Speed Generation: A Powerhouse for Large LLMs
The NVIDIA 4070 Ti, with its dedicated GPU power, is a popular choice for AI and machine learning workloads. Let's examine its performance with the Llama 3 8B and 70B models:
Llama 3 8B Performance
The NVIDIA 4070 Ti delivers impressive performance for the Llama 3 8B model, both in processing and generation, particularly with Q4KM quantization:
| Quantization | Processing (Tokens/second) | Generation (Tokens/second) |
|---|---|---|
| Q4KM | 3653.07 | 82.21 |
Note: Data for Llama 3 8B with F16 precision is unavailable for the 4070 Ti.
The 4070 Ti achieves a 3653.07 tokens/second processing speed with Q4KM, showcasing its ability to handle larger models with speed. While its 82.21 tokens/second generation speed is slower than its processing speed, it's still significantly faster than the M3's performance with Llama 2 7B.
Llama 3 70B Performance: A Tale of Two Devices
Unfortunately, no data is available for the Llama 3 70B model on either the Apple M3 or the NVIDIA 4070 Ti. This could be due to limitations of the benchmark tools or the complex nature of running such a large model on these specific devices.
Comparison of Apple M3 and NVIDIA 4070 Ti: Strengths and Weaknesses
Now that we've analyzed the individual performance of each device, let's compare their strengths and weaknesses, offering insights for developers:
| Feature | Apple M3 | NVIDIA 4070 Ti |
|---|---|---|
| Memory | 100GB Unified Memory | 12GB Dedicated GPU Memory |
| Cores | 10 CPU Cores | Dedicated GPU architecture |
| Llama 2 7B Performance (Tokens/second) | Processing: 187.52 (Q80), 186.75 (Q40) Generation: 12.27 (Q80), 21.34 (Q40) |
N/A |
| Llama 3 8B Performance (Tokens/second) | N/A | Processing: 3653.07 (Q4KM) Generation: 82.21 (Q4KM) |
| Power Consumption | Generally lower | Higher |
| Cost | Usually more affordable | More expensive |
| Applications | Ideal for smaller models, general-purpose computing | Suited for larger models, GPU-intensive tasks |
Key Takeaways:
- The M3 shines with smaller models: Its unified memory and efficient processing speed make it a great choice for running smaller LLMs like the Llama 2 7B.
- The 4070 Ti is a powerhouse for large models: Its dedicated GPU architecture and high memory bandwidth make it a top contender for running larger models like Llama 3 8B.
- Quantization matters: The M3's performance is strongly influenced by quantization levels.
- Generation speed is a bottleneck: While both devices excel in processing speed, their token generation speeds lag behind. This suggests that optimization efforts should focus on improving token generation efficiency.
Practical Recommendations
Choosing the right device depends on your specific needs:
- If you're working with small LLMs: The Apple M3 offers a good balance of performance and affordability.
- For running large LLMs or GPU-intensive workloads: The NVIDIA 4070 Ti provides superior performance, but at a higher cost.
- Consider your budget: The M3 is generally more affordable than the 4070 Ti.
- Prioritize token generation speed: If you need fast response times from your LLM, consider a more powerful GPU like the 4070 Ti or explore alternative optimization techniques.
Quantization: A Simplified Explanation
Quantization is a technique that reduces the precision of model weights, leading to smaller model sizes and faster processing speeds. Here's a simple analogy:
Imagine you're trying to measure the length of a table using a ruler with really fine markings (float precision). This gives you a very accurate measurement, but it takes time. Quantization is like using a ruler with fewer markings (quantized precision). You might lose some accuracy, but you can measure the table much faster.
Beyond the Numbers: Future Considerations
While this article highlights the current performance of the Apple M3 and NVIDIA 4070 Ti, the landscape of LLM technology is constantly evolving. Future developments may see new devices and techniques with even greater performance gains. Keep an eye out for:
- New GPU architectures: NVIDIA is continuously introducing novel GPUs with enhanced performance.
- Optimized LLM frameworks: Libraries like llama.cpp are continually improving, leading to faster execution speeds.
- Hardware-specific optimizations: Device manufacturers are developing hardware-level optimizations tailored for LLMs.
FAQ
What is token generation speed?
Token generation speed refers to how fast an LLM can generate text. It's measured in tokens per second, and a higher number means a faster response time.
How does quantization affect LLM performance?
Quantization reduces the size of model weights, potentially leading to faster processing speeds and lower memory requirements. However, it can also impact accuracy.
Which device is best for running LLMs?
The best device depends on your specific needs. Smaller LLMs might run well on the Apple M3, while larger LLMs benefit from the power of a GPU like the NVIDIA 4070 Ti.
What are the advantages of using a GPU for LLMs?
GPUs offer parallel processing capabilities, making them ideal for the intensive computations involved in LLM training and inference.
Where can I find more information about LLM performance benchmarks?
You can explore the following resources for more information:
Keywords:
Apple M3, NVIDIA 4070 Ti, LLM, Large Language Models, Token Generation Speed, Llama 2, Llama 3, Quantization, Benchmark Analysis, GPU, CPU, Performance Comparison, AI, Machine Learning, Deep Learning, Inference, Tokenization, NLP, Natural Language Processing, Developer, Hardware, Software, Cost, Power Consumption, Speed, Efficiency, Future Trends, LLM Frameworks, Optimization, FAQ, Benchmarking, Hardware Acceleration, Model Weights, Precision, Accuracy, Data Science, Machine Learning Engineer, AI Developer.