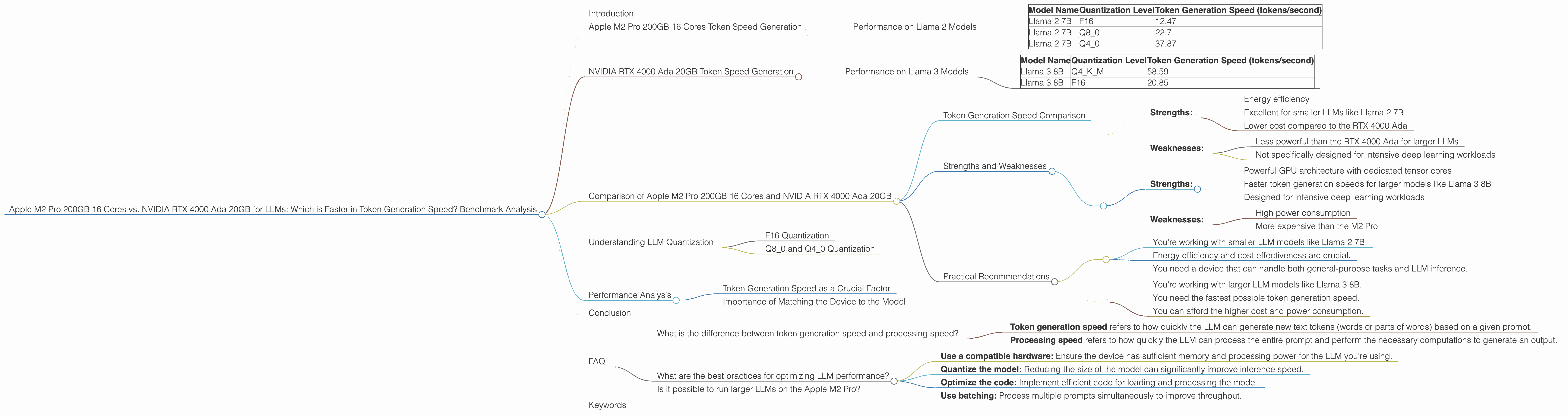
Apple M2 Pro 200gb 16cores vs. NVIDIA RTX 4000 Ada 20GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The world of large language models (LLMs) is exploding, with advancements happening every day. These powerful models are changing the way we interact with computers and are finding a place in countless applications, from generating creative content to automating tasks. But running LLMs effectively requires powerful hardware, and choosing the right device for your specific needs can be a daunting task.
This article compares two popular options for running LLMs: the Apple M2 Pro 200GB 16 cores and the NVIDIA RTX 4000 Ada 20GB. We'll delve into the token generation speed of each device, analyze their performance with various LLM models and configurations, and discuss their strengths and weaknesses to help you make the best decision for your project.
Apple M2 Pro 200GB 16 Cores Token Speed Generation
The Apple M2 Pro 200GB 16 cores is a powerful chip built for performance and efficiency. Let's see how it performs with Llama 2 models:
Performance on Llama 2 Models
The following table presents the token generation speed of the Apple M2 Pro 200GB 16 cores for different Llama 2 models and quantization levels:
| Model Name | Quantization Level | Token Generation Speed (tokens/second) |
|---|---|---|
| Llama 2 7B | F16 | 12.47 |
| Llama 2 7B | Q8_0 | 22.7 |
| Llama 2 7B | Q4_0 | 37.87 |
It's worth noting that the Apple M2 Pro 200GB 16 cores performs well with Llama 2 7B models, especially when using the Q4_0 quantization level. This indicates that the M2 Pro can effectively handle smaller LLMs with good token generation speed.
NVIDIA RTX 4000 Ada 20GB Token Speed Generation
The NVIDIA RTX 4000 Ada 20GB is a high-end graphics card known for its impressive performance in demanding tasks, including deep learning. Let's see how it performs with Llama 3 models:
Performance on Llama 3 Models
The following table presents the token generation speed of the NVIDIA RTX 4000 Ada 20GB for different Llama 3 models and quantization levels:
| Model Name | Quantization Level | Token Generation Speed (tokens/second) |
|---|---|---|
| Llama 3 8B | Q4KM | 58.59 |
| Llama 3 8B | F16 | 20.85 |
We do not have data available for the NVIDIA RTX 4000 Ada 20GB for Llama 3 70B models at this time.
Comparison of Apple M2 Pro 200GB 16 Cores and NVIDIA RTX 4000 Ada 20GB
Token Generation Speed Comparison
Overall, the NVIDIA RTX 4000 Ada 20GB demonstrates faster generation speeds for Llama 3 8B compared to the Apple M2 Pro 200GB 16 cores for Llama 2 7B models. This is likely due to the RTX 4000 Ada's superior GPU architecture and dedicated tensor cores optimized for deep learning workloads.
However, it's essential to remember that the Apple M2 Pro excels in efficiency and low-power consumption. It's a great choice for smaller models like Llama 2 7B where cost-effectiveness and energy consumption are crucial.
Strengths and Weaknesses
Apple M2 Pro 200GB 16 Cores:
Strengths:
- Energy efficiency
- Excellent for smaller LLMs like Llama 2 7B
- Lower cost compared to the RTX 4000 Ada
Weaknesses:
- Less powerful than the RTX 4000 Ada for larger LLMs
- Not specifically designed for intensive deep learning workloads
NVIDIA RTX 4000 Ada 20GB:
Strengths:
- Powerful GPU architecture with dedicated tensor cores
- Faster token generation speeds for larger models like Llama 3 8B
- Designed for intensive deep learning workloads
Weaknesses:
- High power consumption
- More expensive than the M2 Pro
Practical Recommendations
Choose the Apple M2 Pro 200GB 16 Cores if:
- You're working with smaller LLM models like Llama 2 7B.
- Energy efficiency and cost-effectiveness are crucial.
- You need a device that can handle both general-purpose tasks and LLM inference.
Choose the NVIDIA RTX 4000 Ada 20GB if:
- You're working with larger LLM models like Llama 3 8B.
- You need the fastest possible token generation speed.
- You can afford the higher cost and power consumption.
Understanding LLM Quantization
LLM quantization is a technique used to reduce the size of the model and speed up inference by using fewer bits to represent the model's weights. This can significantly improve the performance of smaller devices like the Apple M2 Pro.
F16 Quantization
F16 quantization represents model weights using 16 bits, which is less than the typical 32 bits used for floating-point numbers. This reduces the model size and memory footprint.
Q80 and Q40 Quantization
Q80 and Q40 quantization take this concept further, representing weights using only 8 and 4 bits, respectively. This leads to even smaller models and faster inference speeds but can sometimes result in reduced accuracy.
Performance Analysis
The token generation speed of an LLM is crucial for real-time applications like chatbots and text generation. The results show that the NVIDIA RTX 4000 Ada 20GB excels in generating tokens with the Llama 3 8B model, while the Apple M2 Pro 200GB 16 cores performs well with the Llama 2 7B model.
Token Generation Speed as a Crucial Factor
Think of it this way: the token generation speed is like the speed of a typist. A faster token generation speed means the LLM can process and respond to prompts much more quickly. This is essential for applications that require real-time interaction, like chatbots and virtual assistants.
Importance of Matching the Device to the Model
It's important to match the device to the size and complexity of the LLM. The Apple M2 Pro 200GB 16 cores provides an efficient solution for smaller models, while the NVIDIA RTX 4000 Ada 20GB is a powerhouse for larger models.
Conclusion
Choosing the right device for running LLM models depends on your specific needs and the model you're using. The Apple M2 Pro 200GB 16 cores is an excellent choice for smaller LLM models, offering efficiency and affordability. The NVIDIA RTX 4000 Ada 20GB is a top performer designed for demanding tasks and larger LLMs. Ultimately, the best choice will depend on the specific requirements of your project and your budget constraints.
FAQ
What is the difference between token generation speed and processing speed?
- Token generation speed refers to how quickly the LLM can generate new text tokens (words or parts of words) based on a given prompt.
- Processing speed refers to how quickly the LLM can process the entire prompt and perform the necessary computations to generate an output.
What are the best practices for optimizing LLM performance?
- Use a compatible hardware: Ensure the device has sufficient memory and processing power for the LLM you're using.
- Quantize the model: Reducing the size of the model can significantly improve inference speed.
- Optimize the code: Implement efficient code for loading and processing the model.
- Use batching: Process multiple prompts simultaneously to improve throughput.
Is it possible to run larger LLMs on the Apple M2 Pro?
Yes, it's possible to run larger LLMs on the Apple M2 Pro, but you may experience slower token generation speeds and potential memory limitations.
Keywords
Apple M2 Pro, NVIDIA RTX 4000, LLM, Large Language Model, token generation speed, Llama 2, Llama 3, quantization, F16, Q80, Q40, performance analysis, benchmark, deep learning, GPU, CPU, comparison, strengths, weaknesses, practical recommendations, efficiency, cost-effectiveness, power consumption, inference, machine learning, natural language processing, AI, computer science, technology, development.