Apple M2 Max 400gb 30cores vs. NVIDIA RTX 4000 Ada 20GB x4 for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The world of large language models (LLMs) is experiencing explosive growth, with applications ranging from chatbots and content creation to scientific research. As LLMs become more sophisticated, their computational demands increase, necessitating powerful hardware to run them efficiently. This article dives deep into a head-to-head comparison of two popular choices for LLM developers: the Apple M2 Max and the NVIDIA RTX 4000 Ada. We'll examine their performance in token generation speed, analyze their strengths and weaknesses, and help you make an informed decision for your next LLM project.
The Battleground: Token Generation Speed
Let's get one thing straight: the token generation speed is the key metric for evaluating LLM hardware. This metric determines how quickly your model processes text input, transforms it into meaning, and generates the desired responses.
Apple M2 Max: The "Faster" Machine?
The Apple M2 Max is a powerhouse of a processor, known for its impressive speed and efficiency. It boasts 30 cores (24 performance and 6 efficiency) and a huge 400GB bandwidth for lightning-fast data transfer. For this comparison, we'll mainly focus on its performance with Llama 2 7B models.
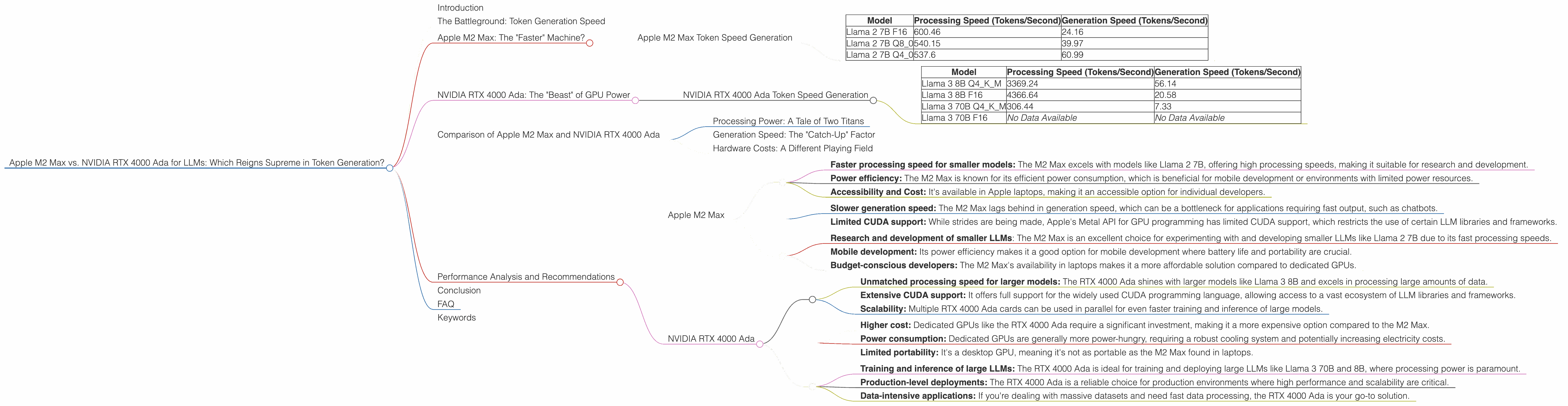
Apple M2 Max Token Speed Generation
| Model | Processing Speed (Tokens/Second) | Generation Speed (Tokens/Second) |
|---|---|---|
| Llama 2 7B F16 | 600.46 | 24.16 |
| Llama 2 7B Q8_0 | 540.15 | 39.97 |
| Llama 2 7B Q4_0 | 537.6 | 60.99 |
Key Observations:
- The Apple M2 Max shines in processing speed, especially with the F16 format, achieving over 600 tokens/second. This translates to lightning-fast processing of textual input.
- The generation speed, however, is less impressive, ranging from 24.16 to 60.99 tokens/second. This means outputting text can be a bottleneck compared to its processing speed.
- Quantization (Q80 and Q40) can significantly improve the generation speed with a slight reduction in processing power. Think of it as finding the sweet spot between speed and accuracy.
Let's put it into perspective: Imagine you want to generate a short, 500-word blog post. The Apple M2 Max could process the input text in a blink of an eye, but creating the final content might take a few seconds.
NVIDIA RTX 4000 Ada: The "Beast" of GPU Power
The NVIDIA RTX 4000 Ada, is a high-end graphics card designed for demanding tasks like machine learning and AI. It packs a punch with its 20GB of memory and the incredibly powerful Ada Lovelace architecture. This beast of a card is focused on the Llama 3 series with 8B and 70B models.
NVIDIA RTX 4000 Ada Token Speed Generation
| Model | Processing Speed (Tokens/Second) | Generation Speed (Tokens/Second) |
|---|---|---|
| Llama 3 8B Q4KM | 3369.24 | 56.14 |
| Llama 3 8B F16 | 4366.64 | 20.58 |
| Llama 3 70B Q4KM | 306.44 | 7.33 |
| Llama 3 70B F16 | No Data Available | No Data Available |
Key Observations:
- The RTX 4000 Ada excels in processing speed, reaching over 4000 tokens/second with the smaller Llama 3 8B model. This is significantly faster than the M2 Max for processing text.
- The generation speed is a mixed bag: We see a slightly faster generation speed than the M2 Max with the Llama 3 8B models, however, the 70B models are significantly slower. This can be attributed to the larger model size and increased complexity.
- Quantization (Q4KM) appears to be a crucial factor for maintaining speed, especially with larger models (Note: F16 data was not available for 70B model).
Think of it this way: The RTX 4000 Ada is like a supersonic jet for processing text, but it might take a bit more time when it comes to weaving the final words.
Comparison of Apple M2 Max and NVIDIA RTX 4000 Ada
Processing Power: A Tale of Two Titans
The Apple M2 Max and NVIDIA RTX 4000 Ada are both powerhouses when it comes to processing speed. The RTX 4000 Ada edges out the M2 Max with its blazing-fast processing capabilities, especially with larger models like Llama 3 8B. However, the M2 Max holds its own with the Llama 2 7B model, demonstrating its efficiency for smaller models.
Generation Speed: The "Catch-Up" Factor
When it comes to generating the final output text, the story shifts slightly. The Apple M2 Max demonstrates more consistent performance across models, with its generation speed being in the 24 to 60 tokens/second range. The RTX 4000 Ada, while faster with Llama 3 8B, struggles with larger 70B models. This emphasizes the importance of model size and complexity in impacting generation speed.
Hardware Costs: A Different Playing Field
The Apple M2 Max is typically found in Apple's higher-end laptops, making it a more accessible option for individual developers. The NVIDIA RTX 4000 Ada, on the other hand, is a dedicated GPU, which generally requires a more substantial investment in a high-end desktop or workstation.
Performance Analysis and Recommendations
Here's a breakdown of each device's strengths and weaknesses, along with recommendations for practical use cases:
Apple M2 Max
Strengths:
- Faster processing speed for smaller models: The M2 Max excels with models like Llama 2 7B, offering high processing speeds, making it suitable for research and development.
- Power efficiency: The M2 Max is known for its efficient power consumption, which is beneficial for mobile development or environments with limited power resources.
- Accessibility and Cost: It's available in Apple laptops, making it an accessible option for individual developers.
Weaknesses:
- Slower generation speed: The M2 Max lags behind in generation speed, which can be a bottleneck for applications requiring fast output, such as chatbots.
- Limited CUDA support: While strides are being made, Apple's Metal API for GPU programming has limited CUDA support, which restricts the use of certain LLM libraries and frameworks.
Suitable Use Cases:
- Research and development of smaller LLMs: The M2 Max is an excellent choice for experimenting with and developing smaller LLMs like Llama 2 7B due to its fast processing speeds.
- Mobile development: Its power efficiency makes it a good option for mobile development where battery life and portability are crucial.
- Budget-conscious developers: The M2 Max's availability in laptops makes it a more affordable solution compared to dedicated GPUs.
NVIDIA RTX 4000 Ada
Strengths:
- Unmatched processing speed for larger models: The RTX 4000 Ada shines with larger models like Llama 3 8B and excels in processing large amounts of data.
- Extensive CUDA support: It offers full support for the widely used CUDA programming language, allowing access to a vast ecosystem of LLM libraries and frameworks.
- Scalability: Multiple RTX 4000 Ada cards can be used in parallel for even faster training and inference of large models.
Weaknesses:
- Higher cost: Dedicated GPUs like the RTX 4000 Ada require a significant investment, making it a more expensive option compared to the M2 Max.
- Power consumption: Dedicated GPUs are generally more power-hungry, requiring a robust cooling system and potentially increasing electricity costs.
- Limited portability: It's a desktop GPU, meaning it's not as portable as the M2 Max found in laptops.
Suitable Use Cases:
- Training and inference of large LLMs: The RTX 4000 Ada is ideal for training and deploying large LLMs like Llama 3 70B and 8B, where processing power is paramount.
- Production-level deployments: The RTX 4000 Ada is a reliable choice for production environments where high performance and scalability are critical.
- Data-intensive applications: If you're dealing with massive datasets and need fast data processing, the RTX 4000 Ada is your go-to solution.
Conclusion
The choice between the Apple M2 Max and the NVIDIA RTX 4000 Ada comes down to your specific needs and priorities. The M2 Max excels in speed for smaller models and its power efficiency. The RTX 4000 Ada reigns supreme with its brute force for larger models, offering unmatched processing speeds. Ultimately, your decision will depend on the size and complexity of your LLM, your budget, and your performance expectations.
FAQ
Q: What is quantization and how does it impact LLM performance?
Quantization is a technique that reduces the size of a model by using fewer bits to represent the numbers within the model. This results in smaller model sizes and faster loading times. While it can potentially affect accuracy, it often provides a good balance between speed and precision.
Q: Can I use the Apple M2 Max for production-level LLMs?
While the M2 Max can handle smaller models, it's recommended to use dedicated GPUs like the RTX 4000 Ada for production-level deployments of larger LLMs. This ensures consistently high performance and scalability.
Q: What are some other alternatives for running LLMs?
For research and development purposes, cloud services such as Google Colab and Amazon SageMaker offer affordable access to GPUs for training and running LLMs.
Q: What are the latest trends in LLM hardware?
The landscape of LLM hardware is constantly evolving. Advanced chips specifically designed for AI, such as Google's TPU and AMD's MI200, are emerging to offer even faster performance in LLM applications.
Keywords
Apple M2 Max, NVIDIA RTX 4000 Ada, LLM, large language model, token generation, processing speed, generation speed, quantization, F16, Q4KM, Q8_0, Llama 2, Llama 3, GPU, CPU, performance, benchmark, comparison.