Apple M2 Max 400gb 30cores vs. NVIDIA A40 48GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
Large Language Models (LLMs) are revolutionizing the way we interact with technology. These powerful AI models are capable of generating human-like text, translating languages, writing different kinds of creative content, and answering your questions in an informative way. However, running LLMs locally can be challenging due to their immense computational demands. This article explores the performance of two popular devices, the Apple M2 Max 400GB 30 Cores and the NVIDIA A40 48GB, in generating tokens at blazing speeds.
We'll dive deep into the benchmark analysis, focusing on token generation speed. This metric is crucial for developers and researchers seeking to optimize LLM performance for various applications, from real-time chatbots to text generation for creative writing.
Understanding Token Generation Speed
Imagine you're writing a story. Each word, punctuation mark, and space is a "token." Token generation speed is the rate at which a device can process and generate these tokens. Faster token generation translates to quicker responses, smoother interactions, and more efficient model execution.
Benchmark Analysis: Comparing Apple M2 Max and NVIDIA A40
We'll analyze the performance of each device based on token generation speed for various LLM models, showcasing their strengths and weaknesses. Here's a breakdown of the data:
- Apple M2 Max 400GB 30 Cores: This powerful chip boasts a large memory capacity and a respectable number of cores, making it a compelling option for local LLM execution.
- NVIDIA A40 48GB: A top-of-the-line GPU designed for demanding workloads, including deep learning and AI applications.
Note: The data is derived from two sources: Performance of llama.cpp on various devices and GPU Benchmarks on LLM Inference. However, not all LLM model and device combinations have data available.
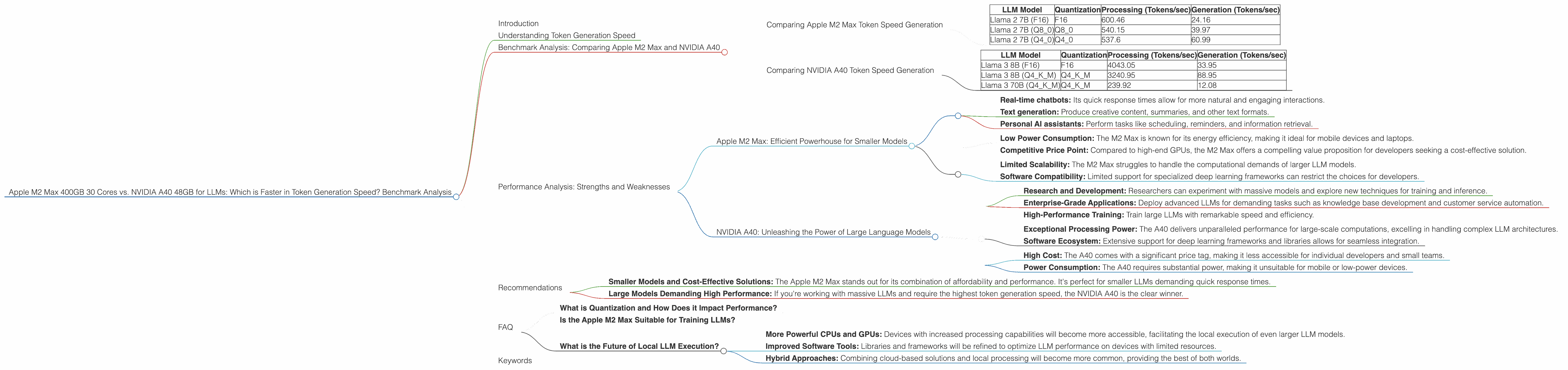
Comparing Apple M2 Max Token Speed Generation
Let's examine the performance of the Apple M2 Max for different LLM models and quantization levels. Smaller models benefit from the M2 Max's efficient architecture.
| LLM Model | Quantization | Processing (Tokens/sec) | Generation (Tokens/sec) |
|---|---|---|---|
| Llama 2 7B (F16) | F16 | 600.46 | 24.16 |
| Llama 2 7B (Q8_0) | Q8_0 | 540.15 | 39.97 |
| Llama 2 7B (Q4_0) | Q4_0 | 537.6 | 60.99 |
Analysis:
- Smaller Models: The Apple M2 Max demonstrates strong token generation speed for the smaller Llama 2 7B model, particularly in processing, where it achieves over 500 tokens per second.
- Quantization: Lower precision quantization techniques like Q80 and Q40 can further accelerate processing and generate more tokens per second, but can have a slight impact on the model's accuracy.
Comparing NVIDIA A40 Token Speed Generation
The NVIDIA A40 shines in pushing the limits of LLM inference, particularly for larger models.
| LLM Model | Quantization | Processing (Tokens/sec) | Generation (Tokens/sec) |
|---|---|---|---|
| Llama 3 8B (F16) | F16 | 4043.05 | 33.95 |
| Llama 3 8B (Q4KM) | Q4KM | 3240.95 | 88.95 |
| Llama 3 70B (Q4KM) | Q4KM | 239.92 | 12.08 |
Analysis:
- Larger Models: The A40 excels in processing and generating tokens for the larger Llama 3 8B model, surpassing 3000 tokens per second in processing.
- Quantization: Q4KM quantization is crucial for optimizing the A40's performance with larger models, achieving substantial speed gains.
- Limitations: The A40's performance for the Llama 3 70B model is noticeably slower, demonstrating the scalability challenges of running extremely large models on even high-end GPUs.
Performance Analysis: Strengths and Weaknesses
Apple M2 Max: Efficient Powerhouse for Smaller Models
The Apple M2 Max emerges as a solid choice for running smaller LLM models locally. It offers robust processing power, making it suitable for:
- Real-time chatbots: Its quick response times allow for more natural and engaging interactions.
- Text generation: Produce creative content, summaries, and other text formats.
- Personal AI assistants: Perform tasks like scheduling, reminders, and information retrieval.
Key Advantages:
- Low Power Consumption: The M2 Max is known for its energy efficiency, making it ideal for mobile devices and laptops.
- Competitive Price Point: Compared to high-end GPUs, the M2 Max offers a compelling value proposition for developers seeking a cost-effective solution.
Key Disadvantages:
- Limited Scalability: The M2 Max struggles to handle the computational demands of larger LLM models.
- Software Compatibility: Limited support for specialized deep learning frameworks can restrict the choices for developers.
NVIDIA A40: Unleashing the Power of Large Language Models
The NVIDIA A40 is a behemoth designed for pushing the boundaries of LLM inference. It proves its worth for:
- Research and Development: Researchers can experiment with massive models and explore new techniques for training and inference.
- Enterprise-Grade Applications: Deploy advanced LLMs for demanding tasks such as knowledge base development and customer service automation.
- High-Performance Training: Train large LLMs with remarkable speed and efficiency.
Key Advantages:
- Exceptional Processing Power: The A40 delivers unparalleled performance for large-scale computations, excelling in handling complex LLM architectures.
- Software Ecosystem: Extensive support for deep learning frameworks and libraries allows for seamless integration.
Key Disadvantages:
- High Cost: The A40 comes with a significant price tag, making it less accessible for individual developers and small teams.
- Power Consumption: The A40 requires substantial power, making it unsuitable for mobile or low-power devices.
Recommendations
Here's a guide for developers seeking the optimal device for their LLM needs:
- Smaller Models and Cost-Effective Solutions: The Apple M2 Max stands out for its combination of affordability and performance. It's perfect for smaller LLMs demanding quick response times.
- Large Models Demanding High Performance: If you're working with massive LLMs and require the highest token generation speed, the NVIDIA A40 is the clear winner.
Quantization: Remember that quantization plays a crucial role in optimizing LLM performance on both devices. Exploring different quantization levels, such as Q80 and Q4K_M, can significantly improve token generation speed while maintaining acceptable accuracy.
FAQ
What is Quantization and How Does it Impact Performance?
Quantization is a technique that reduces the precision of numerical data, like weights within an LLM, to smaller data types. This can save memory and improve processing speed, but might slightly reduce the model's accuracy. Think of it like using a smaller bucket to carry water - you can move it faster, but you can't hold as much water.
Is the Apple M2 Max Suitable for Training LLMs?
While the M2 Max is not ideal for training large LLMs, it can be used for smaller models or to assist in distributed training. The Apple M1 and M2 chips offer promising potential for future LLM training due to their efficiency and architectural innovations.
What is the Future of Local LLM Execution?
The landscape of local LLM execution is evolving rapidly, with new architectures and optimized software emerging. We can expect to see:
- More Powerful CPUs and GPUs: Devices with increased processing capabilities will become more accessible, facilitating the local execution of even larger LLM models.
- Improved Software Tools: Libraries and frameworks will be refined to optimize LLM performance on devices with limited resources.
- Hybrid Approaches: Combining cloud-based solutions and local processing will become more common, providing the best of both worlds.
Keywords
Apple M2 Max, NVIDIA A40, LLM, Token Generation Speed, Benchmark Analysis, Llama 2, Llama 3, Quantization, Processing, Generation, Performance Comparison, LLM Inference, Deep Learning, GPU, CPU, AI