Apple M1 Ultra 800gb 48cores vs. NVIDIA 3090 24GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The world of Large Language Models (LLMs) is exploding, with increasingly sophisticated models like Llama 2 and Llama 3 becoming available. Running these models locally requires powerful hardware, and two popular contenders for LLM performance are the Apple M1 Ultra and the NVIDIA 3090.
This article dives deep into a performance comparison of these two processors, focusing on their token generation speeds for various LLM configurations. We'll explore different quantization levels and model sizes, revealing which device reigns supreme in this exciting battle.
Whether you're a developer building custom applications, a researcher pushing the boundaries of AI, or a curious tech enthusiast, understanding the performance differences between these processors is crucial for making informed choices. Join us as we dissect the data and discover who wins the token generation race!
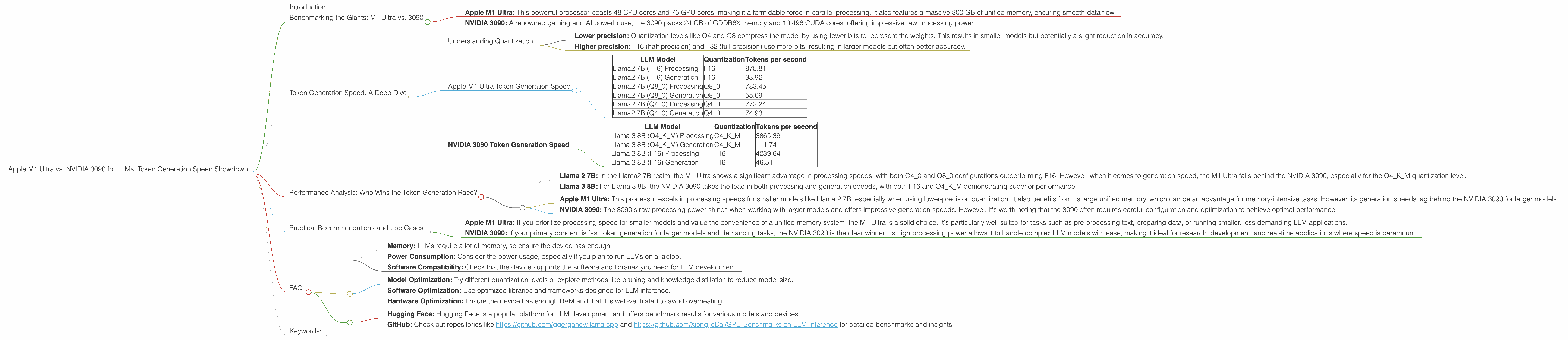
Benchmarking the Giants: M1 Ultra vs. 3090
To get a clear picture, let's look at our contestants:
- Apple M1 Ultra: This powerful processor boasts 48 CPU cores and 76 GPU cores, making it a formidable force in parallel processing. It also features a massive 800 GB of unified memory, ensuring smooth data flow.
- NVIDIA 3090: A renowned gaming and AI powerhouse, the 3090 packs 24 GB of GDDR6X memory and 10,496 CUDA cores, offering impressive raw processing power.
We'll be comparing these processors on their ability to generate tokens for various LLM configurations.
Token Generation Speed: A Deep Dive
Token generation speed is crucial for any LLM application. It determines how quickly a model can translate prompts into coherent outputs, affecting responsiveness, real-time interaction, and overall user experience.
For this comparison, we'll be using the following metrics:
- Tokens per second (token/s): A direct measure of how many tokens the device can generate per second. Higher numbers indicate faster token generation.
Understanding Quantization
Quantization plays a crucial role in LLM performance. It's a technique that reduces the size of the model by compressing its weights, making it more efficient and faster.
Here's what you need to know about quantization:
- Lower precision: Quantization levels like Q4 and Q8 compress the model by using fewer bits to represent the weights. This results in smaller models but potentially a slight reduction in accuracy.
- Higher precision: F16 (half precision) and F32 (full precision) use more bits, resulting in larger models but often better accuracy.
Apple M1 Ultra Token Generation Speed
Let's start with the Apple M1 Ultra and see how it performs with different LLM configurations.
| LLM Model | Quantization | Tokens per second |
|---|---|---|
| Llama2 7B (F16) Processing | F16 | 875.81 |
| Llama2 7B (F16) Generation | F16 | 33.92 |
| Llama2 7B (Q8_0) Processing | Q8_0 | 783.45 |
| Llama2 7B (Q8_0) Generation | Q8_0 | 55.69 |
| Llama2 7B (Q4_0) Processing | Q4_0 | 772.24 |
| Llama2 7B (Q4_0) Generation | Q4_0 | 74.93 |
NVIDIA 3090 Token Generation Speed
Now, let's turn our attention to the NVIDIA 3090 and see how it stacks up against the M1 Ultra.
| LLM Model | Quantization | Tokens per second |
|---|---|---|
| Llama 3 8B (Q4KM) Processing | Q4KM | 3865.39 |
| Llama 3 8B (Q4KM) Generation | Q4KM | 111.74 |
| Llama 3 8B (F16) Processing | F16 | 4239.64 |
| Llama 3 8B (F16) Generation | F16 | 46.51 |
Unfortunately, we don't have data for Llama 3 70B on the NVIDIA 3090. The benchmarks used for this comparison didn't include these configurations.
Performance Analysis: Who Wins the Token Generation Race?
Generation Speed:
- Llama 2 7B: In the Llama2 7B realm, the M1 Ultra shows a significant advantage in processing speeds, with both Q40 and Q80 configurations outperforming F16. However, when it comes to generation speed, the M1 Ultra falls behind the NVIDIA 3090, especially for the Q4KM quantization level.
- Llama 3 8B: For Llama 3 8B, the NVIDIA 3090 takes the lead in both processing and generation speeds, with both F16 and Q4KM demonstrating superior performance.
Strengths and Weaknesses
- Apple M1 Ultra: This processor excels in processing speeds for smaller models like Llama 2 7B, especially when using lower-precision quantization. It also benefits from its large unified memory, which can be an advantage for memory-intensive tasks. However, its generation speeds lag behind the NVIDIA 3090 for larger models.
- NVIDIA 3090: The 3090's raw processing power shines when working with larger models and offers impressive generation speeds. However, it's worth noting that the 3090 often requires careful configuration and optimization to achieve optimal performance.
Practical Recommendations and Use Cases
Choosing the right device depends on your specific needs and priorities.
- Apple M1 Ultra: If you prioritize processing speed for smaller models and value the convenience of a unified memory system, the M1 Ultra is a solid choice. It's particularly well-suited for tasks such as pre-processing text, preparing data, or running smaller, less demanding LLM applications.
- NVIDIA 3090: If your primary concern is fast token generation for larger models and demanding tasks, the NVIDIA 3090 is the clear winner. Its high processing power allows it to handle complex LLM models with ease, making it ideal for research, development, and real-time applications where speed is paramount.
FAQ:
Q: What is tokenization?
A: Tokenization is the process of breaking down text into smaller units called tokens. These tokens can be individual words, characters, or even sub-word units. LLMs use tokenization to process and understand text efficiently.
Q: What is quantization and why does it matter for LLMs?
*A: * Quantization is a technique used to compress the weights of an LLM, making it smaller and faster. By reducing the precision of the weights, LLMs can operate more efficiently on devices with limited resources.
Q: What are some other factors to consider when choosing a device for LLMs?
A: Besides token generation speed, other important factors include: * Memory: LLMs require a lot of memory, so ensure the device has enough. * Power Consumption: Consider the power usage, especially if you plan to run LLMs on a laptop. * Software Compatibility: Check that the device supports the software and libraries you need for LLM development.
Q: How can I further improve LLM performance?
A: Here are some techniques to enhance LLM performance:
- Model Optimization: Try different quantization levels or explore methods like pruning and knowledge distillation to reduce model size.
- Software Optimization: Use optimized libraries and frameworks designed for LLM inference.
- Hardware Optimization: Ensure the device has enough RAM and that it is well-ventilated to avoid overheating.
Q: Where can I find more information about LLM performance benchmarks?
A: The following resources provide valuable insights:
- Hugging Face: Hugging Face is a popular platform for LLM development and offers benchmark results for various models and devices.
- GitHub: Check out repositories like https://github.com/ggerganov/llama.cpp and https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference for detailed benchmarks and insights.
Keywords:
Apple M1 Ultra, NVIDIA 3090, LLM, Large Language Model, Token Generation, Token Speed, Benchmark, Performance, Llama 2, Llama 3, Quantization, F16, Q4, Q8, Processing Speed, Generation Speed, Use Cases, Recommendations, GPU, CPU, Software Optimization, Hardware Optimization, Hugging Face, GitHub