Apple M1 Max 400gb 24cores vs. NVIDIA 4080 16GB for LLMs: Which is Faster in Token Generation Speed? Benchmark Analysis
Introduction
The world of large language models (LLMs) is exploding, and everyone wants to get in on the action. But running these models locally can be a real challenge, especially if you're working with large models like Llama 2 or Llama 3.
This article dives into a head-to-head comparison of two popular options for local LLM deployment: the Apple M1 Max 400GB 24-core chip and the NVIDIA 4080 16GB GPU. We'll use real-world benchmarks to analyze their token generation speeds for different LLM models and quantizations, and help you determine which device reigns supreme.
Apple M1 Max Token Speed Generation
The Apple M1 Max is a powerful chip designed for both performance and efficiency. It's a popular choice for developers and creative professionals who need a powerful workstation. Let's see how it stacks up against its NVIDIA counterpart in the realm of token generation.
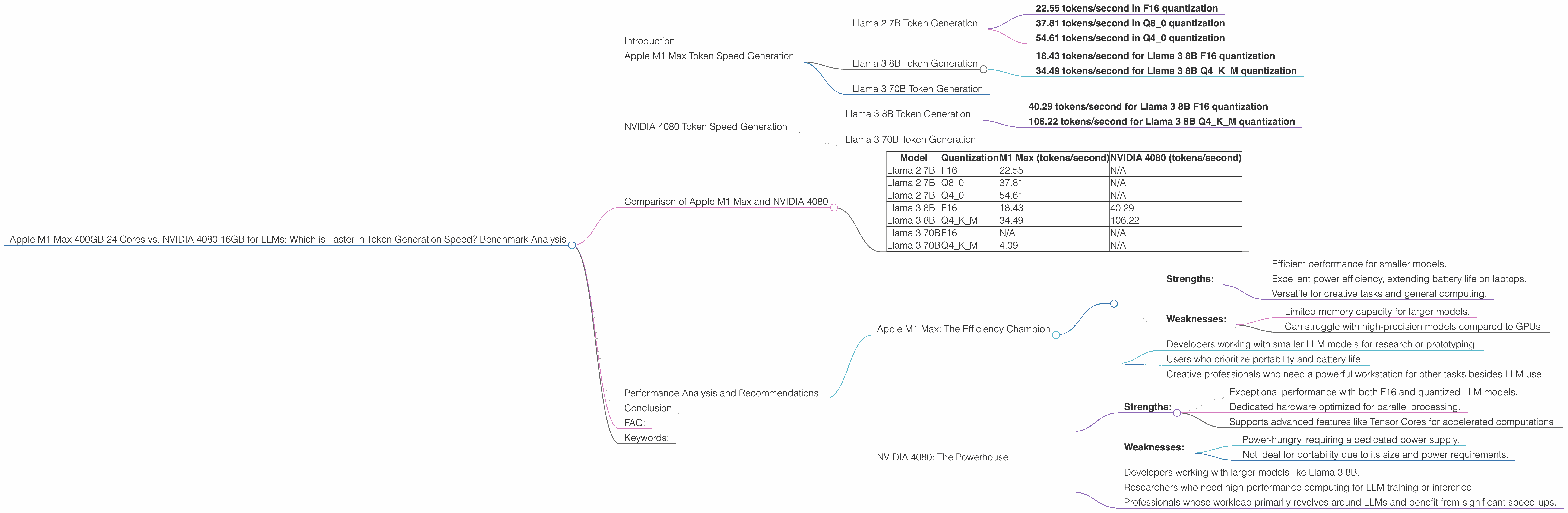
Llama 2 7B Token Generation
The M1 Max 400GB 24-core chip shows impressive performance with the Llama 2 7B model. It achieves a token generation speed of:
- 22.55 tokens/second in F16 quantization
- 37.81 tokens/second in Q8_0 quantization
- 54.61 tokens/second in Q4_0 quantization
We see a clear trend here. The M1 Max shines when using quantized models, delivering significantly faster token generation compared to F16 precision.
Llama 3 8B Token Generation
The M1 Max is also capable of running Llama 3 8B, although it's worth noting that it's using a slightly different configuration with 32 cores and 400GB bandwidth. Here's how it fares:
- 18.43 tokens/second for Llama 3 8B F16 quantization
- 34.49 tokens/second for Llama 3 8B Q4KM quantization
Again, we see faster speeds with quantized models.
Llama 3 70B Token Generation
While the M1 Max can handle Llama 3 70B, we unfortunately have no benchmark data available for this specific combination. This is likely due to the M1 Max's limited memory capacity when handling such a large model.
NVIDIA 4080 Token Speed Generation
The NVIDIA 4080 is a high-end GPU known for its raw processing power and advanced features. Let's see how it holds up against the M1 Max in the world of LLM token generation.
Llama 3 8B Token Generation
The NVIDIA 4080 demonstrates its power with the Llama 3 8B model. Here are its token generation speeds:
- 40.29 tokens/second for Llama 3 8B F16 quantization
- 106.22 tokens/second for Llama 3 8B Q4KM quantization
Even in F16 quantization, the NVIDIA 4080 surpasses the M1 Max, showcasing its dedicated hardware capabilities. Furthermore, in Q4KM quantization, it achieves a significantly higher speed compared to the M1 Max.
Llama 3 70B Token Generation
Unfortunately, we have no data for the NVIDIA 4080 with Llama 3 70B. While theoretically capable, further testing is needed to determine its performance with this larger model.
Comparison of Apple M1 Max and NVIDIA 4080
To better understand the strengths and weaknesses of each device, let's analyze their performance in a table format:
| Model | Quantization | M1 Max (tokens/second) | NVIDIA 4080 (tokens/second) |
|---|---|---|---|
| Llama 2 7B | F16 | 22.55 | N/A |
| Llama 2 7B | Q8_0 | 37.81 | N/A |
| Llama 2 7B | Q4_0 | 54.61 | N/A |
| Llama 3 8B | F16 | 18.43 | 40.29 |
| Llama 3 8B | Q4KM | 34.49 | 106.22 |
| Llama 3 70B | F16 | N/A | N/A |
| Llama 3 70B | Q4KM | 4.09 | N/A |
Observations:
- NVIDIA 4080 reigns supreme in F16 quantization for Llama 3 8B. This highlights the NVIDIA GPU's strength in handling high-precision models.
- NVIDIA 4080 is the clear winner in Q4KM quantization. This highlights its ability to process quantized models with remarkable speed.
- The M1 Max excels in Q4_0 quantization for Llama 2 7B. This showcases its efficiency with smaller models and quantized representations.
- The M1 Max's performance on Llama 3 70B is limited by its memory capacity. This limitation restricts the M1 Max from efficiently handling large models.
- The NVIDIA 4080's ability to run Llama 3 70B requires further investigation. Its capability with larger models remains unclear due to the lack of benchmark data.
Performance Analysis and Recommendations
Apple M1 Max: The Efficiency Champion
The M1 Max excels at handling smaller models like Llama 2 7B, especially with quantized formats.
Strengths:
- Efficient performance for smaller models.
- Excellent power efficiency, extending battery life on laptops.
- Versatile for creative tasks and general computing.
Weaknesses:
- Limited memory capacity for larger models.
- Can struggle with high-precision models compared to GPUs.
Recommended use cases:
- Developers working with smaller LLM models for research or prototyping.
- Users who prioritize portability and battery life.
- Creative professionals who need a powerful workstation for other tasks besides LLM use.
NVIDIA 4080: The Powerhouse
The NVIDIA 4080 is a powerhouse designed for demanding workloads, making it a strong contender for running large LLMs.
Strengths:
- Exceptional performance with both F16 and quantized LLM models.
- Dedicated hardware optimized for parallel processing.
- Supports advanced features like Tensor Cores for accelerated computations.
Weaknesses:
- Power-hungry, requiring a dedicated power supply.
- Not ideal for portability due to its size and power requirements.
Recommended use cases:
- Developers working with larger models like Llama 3 8B.
- Researchers who need high-performance computing for LLM training or inference.
- Professionals whose workload primarily revolves around LLMs and benefit from significant speed-ups.
Conclusion
The choice between the Apple M1 Max and the NVIDIA 4080 ultimately boils down to your priorities. The M1 Max is a great option for efficiency and versatility with smaller models, while the NVIDIA 4080 shines when it comes to raw power and handling larger models.
Consider your specific needs and budget to make the best decision. If you value efficiency and portability, the M1 Max is a solid choice. If you prioritize raw performance and need to push the boundaries of LLM computation, the NVIDIA 4080 is the way to go.
FAQ:
Q. What is quantization, and how does it affect LLM performance?
A. Quantization is a technique used to reduce the size of LLM models by representing their weights with fewer bits. This can significantly improve performance by allowing the model to fit into smaller memory spaces and process data faster. Think of it like using a lower-resolution image. It might not be as detailed, but it takes up less space and loads faster.
Q. How do I choose the right device for my LLM needs?
A. The best way to choose is to consider the size of the model you're working with, your budget, and your priorities. If you're working with smaller models and need efficiency, the M1 Max is a great option. If you need raw performance and are willing to sacrifice portability, the NVIDIA 4080 is the way to go.
Q. Is there anything else I should know about running LLMs locally?
A. Running LLMs locally can be complex, and it requires a specific setup and configuration. Consider using tools like llama.cpp, which provide a convenient framework for running LLMs on different devices.
Keywords:
Apple M1 Max, NVIDIA 4080, LLM, Large Language Model, Token Generation, Benchmark, Performance Analysis, Llama 2, Llama 3, Quantization, F16, Q80, Q40, Q4KM, GPU, CPU, Local Deployment, Performance Comparison, Speed, Efficiency.