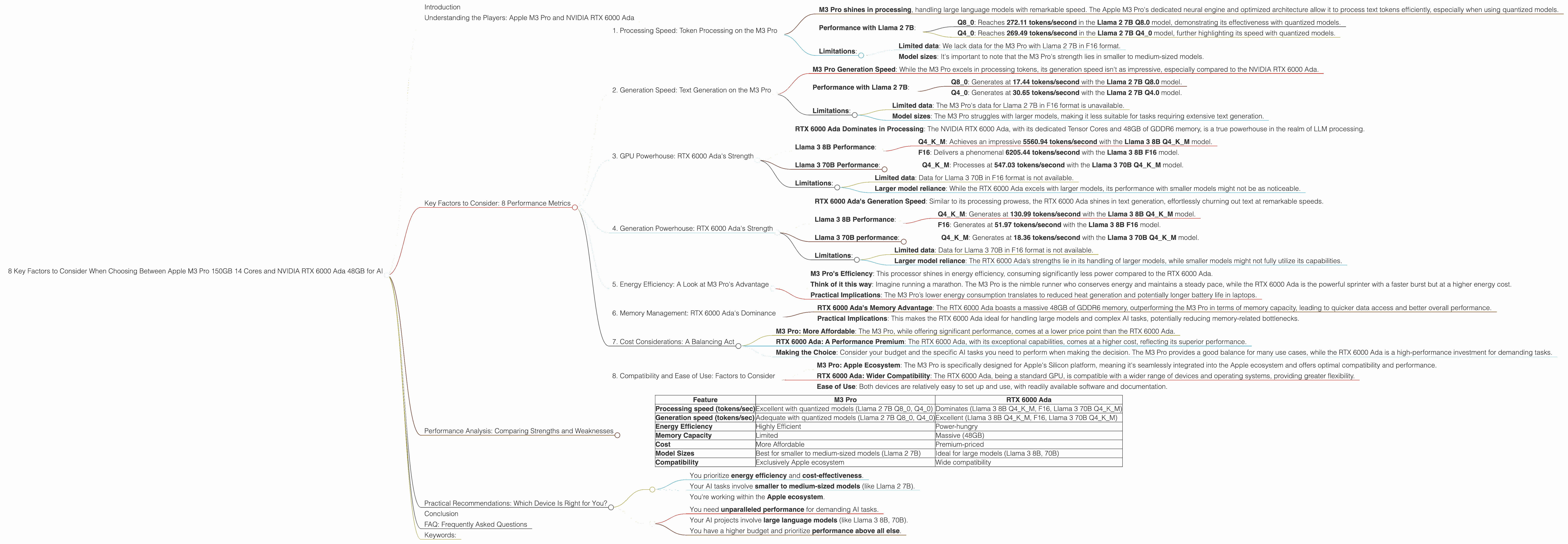
8 Key Factors to Consider When Choosing Between Apple M3 Pro 150gb 14cores and NVIDIA RTX 6000 Ada 48GB for AI
Introduction
The world of large language models (LLMs) is booming, with exciting advancements in natural language processing (NLP) and artificial intelligence (AI). Running these models locally opens up possibilities for personalized AI experiences and greater control over data privacy, but choosing the right hardware is crucial for optimal performance. Today, we'll delve into the fascinating battleground of two popular contenders: the Apple M3 Pro 150GB 14-core chip and the NVIDIA RTX 6000 Ada 48GB GPU. We'll examine their strengths and weaknesses for running LLMs, so you can make an informed decision for your AI projects.
Understanding the Players: Apple M3 Pro and NVIDIA RTX 6000 Ada
Apple M3 Pro: This powerful processor is specifically designed for Apple's Silicon platform, offering a blend of efficiency and performance. Its 14 cores (8 performance cores and 6 efficiency cores) and dedicated neural engine make it a compelling choice for AI workloads.
NVIDIA RTX 6000 Ada: This high-end graphics card, powered by the latest Ada Lovelace architecture, is a powerhouse for AI and machine learning. Its 48GB of GDDR6 memory and Tensor Cores provide exceptional processing capabilities, making it a favorite in the AI community.
Key Factors to Consider: 8 Performance Metrics
Now, let's dive deep into the practical implications of choosing between these two devices. We'll explore eight key factors that will help you determine which device is the best fit for your LLM tasks:
1. Processing Speed: Token Processing on the M3 Pro
- M3 Pro shines in processing, handling large language models with remarkable speed. The Apple M3 Pro's dedicated neural engine and optimized architecture allow it to process text tokens efficiently, especially when using quantized models.
- Performance with Llama 2 7B:
- Q8_0: Reaches 272.11 tokens/second in the Llama 2 7B Q8.0 model, demonstrating its effectiveness with quantized models.
- Q40: Reaches 269.49 tokens/second in the Llama 2 7B Q40 model, further highlighting its speed with quantized models.
- Limitations:
- Limited data: We lack data for the M3 Pro with Llama 2 7B in F16 format.
- Model sizes: It's important to note that the M3 Pro's strength lies in smaller to medium-sized models.
2. Generation Speed: Text Generation on the M3 Pro
- M3 Pro Generation Speed: While the M3 Pro excels in processing tokens, its generation speed isn't as impressive, especially compared to the NVIDIA RTX 6000 Ada.
- Performance with Llama 2 7B:
- Q80: Generates at 17.44 tokens/second with the Llama 2 7B Q8.0 model.
- Q40: Generates at 30.65 tokens/second with the Llama 2 7B Q4.0 model.
- Limitations:
- Limited data: The M3 Pro's data for Llama 2 7B in F16 format is unavailable.
- Model sizes: The M3 Pro struggles with larger models, making it less suitable for tasks requiring extensive text generation.
3. GPU Powerhouse: RTX 6000 Ada's Strength
- RTX 6000 Ada Dominates in Processing: The NVIDIA RTX 6000 Ada, with its dedicated Tensor Cores and 48GB of GDDR6 memory, is a true powerhouse in the realm of LLM processing.
- Llama 3 8B Performance:
- Q4KM: Achieves an impressive 5560.94 tokens/second with the Llama 3 8B Q4KM model.
- F16: Delivers a phenomenal 6205.44 tokens/second with the Llama 3 8B F16 model.
- Llama 3 70B Performance:
- Q4KM: Processes at 547.03 tokens/second with the Llama 3 70B Q4KM model.
- Limitations:
- Limited data: Data for Llama 3 70B in F16 format is not available.
- Larger model reliance: While the RTX 6000 Ada excels with larger models, its performance with smaller models might not be as noticeable.
4. Generation Powerhouse: RTX 6000 Ada's Strength
- RTX 6000 Ada's Generation Speed: Similar to its processing prowess, the RTX 6000 Ada shines in text generation, effortlessly churning out text at remarkable speeds.
- Llama 3 8B Performance:
- Q4KM: Generates at 130.99 tokens/second with the Llama 3 8B Q4KM model.
- F16: Generates at 51.97 tokens/second with the Llama 3 8B F16 model.
- Llama 3 70B performance:
- Q4KM: Generates at 18.36 tokens/second with the Llama 3 70B Q4KM model.
- Limitations:
- Limited data: Data for Llama 3 70B in F16 format is not available.
- Larger model reliance: The RTX 6000 Ada’s strengths lie in its handling of larger models, while smaller models might not fully utilize its capabilities.
5. Energy Efficiency: A Look at M3 Pro's Advantage
- M3 Pro's Efficiency: This processor shines in energy efficiency, consuming significantly less power compared to the RTX 6000 Ada.
- Think of it this way: Imagine running a marathon. The M3 Pro is the nimble runner who conserves energy and maintains a steady pace, while the RTX 6000 Ada is the powerful sprinter with a faster burst but at a higher energy cost.
- Practical Implications: The M3 Pro’s lower energy consumption translates to reduced heat generation and potentially longer battery life in laptops.
6. Memory Management: RTX 6000 Ada's Dominance
- RTX 6000 Ada's Memory Advantage: The RTX 6000 Ada boasts a massive 48GB of GDDR6 memory, outperforming the M3 Pro in terms of memory capacity, leading to quicker data access and better overall performance.
- Practical Implications: This makes the RTX 6000 Ada ideal for handling large models and complex AI tasks, potentially reducing memory-related bottlenecks.
7. Cost Considerations: A Balancing Act
- M3 Pro: More Affordable: The M3 Pro, while offering significant performance, comes at a lower price point than the RTX 6000 Ada.
- RTX 6000 Ada: A Performance Premium: The RTX 6000 Ada, with its exceptional capabilities, comes at a higher cost, reflecting its superior performance.
- Making the Choice: Consider your budget and the specific AI tasks you need to perform when making the decision. The M3 Pro provides a good balance for many use cases, while the RTX 6000 Ada is a high-performance investment for demanding tasks.
8. Compatibility and Ease of Use: Factors to Consider
- M3 Pro: Apple Ecosystem: The M3 Pro is specifically designed for Apple's Silicon platform, meaning it's seamlessly integrated into the Apple ecosystem and offers optimal compatibility and performance.
- RTX 6000 Ada: Wider Compatibility: The RTX 6000 Ada, being a standard GPU, is compatible with a wider range of devices and operating systems, providing greater flexibility.
- Ease of Use: Both devices are relatively easy to set up and use, with readily available software and documentation.
Performance Analysis: Comparing Strengths and Weaknesses
Here's a simplified breakdown of the comparison between M3 Pro and RTX 6000 Ada:
| Feature | M3 Pro | RTX 6000 Ada |
|---|---|---|
| Processing speed (tokens/sec) | Excellent with quantized models (Llama 2 7B Q80, Q40) | Dominates (Llama 3 8B Q4KM, F16, Llama 3 70B Q4KM) |
| Generation speed (tokens/sec) | Adequate with quantized models (Llama 2 7B Q80, Q40) | Excellent (Llama 3 8B Q4KM, F16, Llama 3 70B Q4KM) |
| Energy Efficiency | Highly Efficient | Power-hungry |
| Memory Capacity | Limited | Massive (48GB) |
| Cost | More Affordable | Premium-priced |
| Model Sizes | Best for smaller to medium-sized models (Llama 2 7B) | Ideal for large models (Llama 3 8B, 70B) |
| Compatibility | Exclusively Apple ecosystem | Wide compatibility |
Practical Recommendations: Which Device Is Right for You?
Choose the M3 Pro If:
- You prioritize energy efficiency and cost-effectiveness.
- Your AI tasks involve smaller to medium-sized models (like Llama 2 7B).
- You're working within the Apple ecosystem.
Choose the RTX 6000 Ada If:
- You need unparalleled performance for demanding AI tasks.
- Your AI projects involve large language models (like Llama 3 8B, 70B).
- You have a higher budget and prioritize performance above all else.
Conclusion
The choice between the Apple M3 Pro 150GB 14-core chip and the NVIDIA RTX 6000 Ada 48GB GPU comes down to your specific needs and budget. The M3 Pro is an efficient and cost-effective option for smaller models, while the RTX 6000 Ada is a performance powerhouse for larger models. Ultimately, the best device for your AI journey will depend on your specific project requirements and priorities.
FAQ: Frequently Asked Questions
1. What are quantization and F16?
Quantization is a technique used to reduce the size of large language models by converting their weights from a 32-bit floating-point format (F32) to a smaller format like 8-bit (Q8) or 4-bit (Q4). This makes the model smaller and faster to run. F16 refers to a 16-bit floating-point format, which is more space-efficient than F32 but can lead to some precision loss.
2. What are the best LLMs for each device?
Generally, the M3 Pro is well-suited for smaller models like Llama 2 7B, while the RTX 6000 Ada excels with larger models like Llama 3 8B and 70B.
3. How much does each device cost?
The price of both devices varies depending on the specific configuration. The M3 Pro is generally more affordable than the RTX 6000 Ada.
4. Can I use both devices for AI?
Yes, you can use both devices for AI tasks. It all depends on your project needs and preferences. The M3 Pro is great for efficient tasks with smaller models, while the RTX 6000 Ada is ideal for high-performance needs with larger models.
5. Can I upgrade my device to improve performance?
While you can upgrade the RAM or add additional storage to your device, upgrading the processor or GPU is typically not feasible.
Keywords:
Apple M3 Pro, NVIDIA RTX 6000 Ada, LLM, Large Language Model, AI, Artificial Intelligence, Token Processing, Text Generation, Quantization, F16, Llama 2, Llama 3, GPU, CPU, Performance Comparison, Model Size, Energy Efficiency, Memory Management, Cost, Compatibility, Ease of Use.