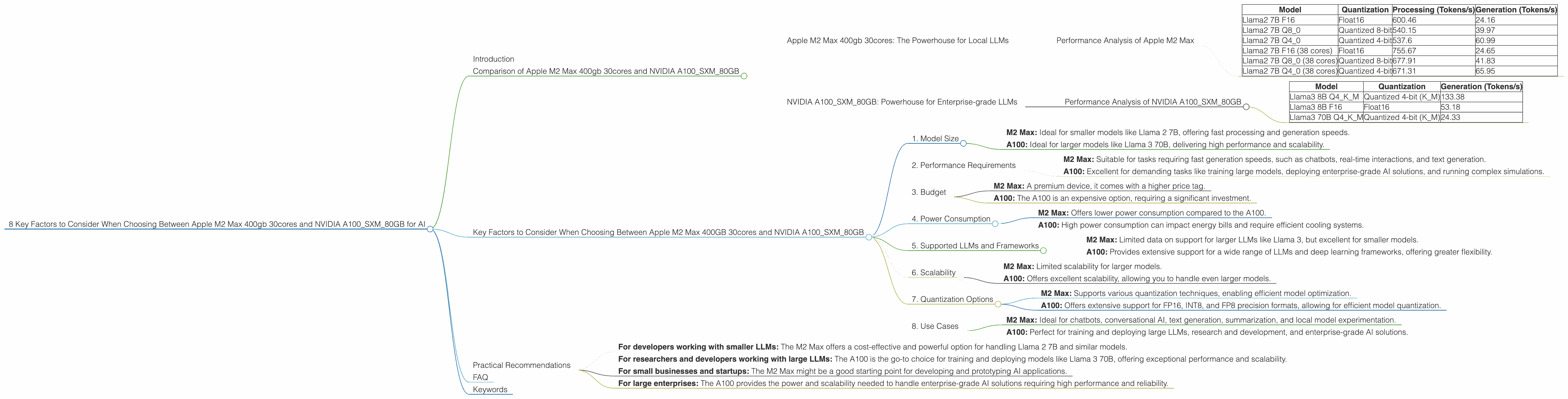
8 Key Factors to Consider When Choosing Between Apple M2 Max 400gb 30cores and NVIDIA A100 SXM 80GB for AI
Introduction
The world of large language models (LLMs) is buzzing with incredible advancements, offering unparalleled capabilities for natural language processing, code generation, and more. However, running these powerful models locally requires specialized hardware designed to handle the demanding computational workload.
Two of the top contenders in this race are the Apple M2 Max 400gb 30cores and NVIDIA A100SXM80GB. Both devices boast impressive performance and are popular choices among developers and data scientists. This article will delve into the key factors to consider when selecting between these two options for running your LLM models.
We will compare their performance on popular LLM models such as Llama 2 and Llama 3, analyzing their strengths and weaknesses. We will also cover important aspects like memory bandwidth, GPU cores, and quantization techniques to help you make an informed decision.
Comparison of Apple M2 Max 400gb 30cores and NVIDIA A100SXM80GB
Let's dive into the nitty-gritty of comparing the M2 Max and the A100, understanding their strengths, weaknesses, and use cases.
Apple M2 Max 400gb 30cores: The Powerhouse for Local LLMs
The Apple M2 Max is a beast of a processor, designed for demanding tasks like video editing, 3D rendering, and surprisingly, running LLMs locally. Its impressive performance comes from a combination of factors:
- High memory bandwidth (BW): The M2 Max offers 400GB/s of memory bandwidth, critical for fast data transfer during model training and inference. Imagine it as a superhighway for data flowing between the CPU and memory, allowing for quicker processing and faster results.
- Numerous GPU cores: With 30 GPU cores, the M2 Max is ideally suited for parallel processing, which is essential for LLM operations. Think of it as having 30 specialized workers simultaneously tackling different parts of the model's computation, speeding up the process significantly.
- Support for various quantization techniques: The M2 Max supports different quantization techniques, reducing model size and making inference faster. This is like compressing a large book into a smaller version while preserving the essential information, making it easier to read and understand.
Performance Analysis of Apple M2 Max
Let's analyze the performance of the M2 Max based on available data. While we have data for the Llama 2 model, we lack information for Llama 3 on this device.
Table 1: Token Speeds of Llama 2 on Apple M2 Max (Tokens/second)
| Model | Quantization | Processing (Tokens/s) | Generation (Tokens/s) |
|---|---|---|---|
| Llama2 7B F16 | Float16 | 600.46 | 24.16 |
| Llama2 7B Q8_0 | Quantized 8-bit | 540.15 | 39.97 |
| Llama2 7B Q4_0 | Quantized 4-bit | 537.6 | 60.99 |
| Llama2 7B F16 (38 cores) | Float16 | 755.67 | 24.65 |
| Llama2 7B Q8_0 (38 cores) | Quantized 8-bit | 677.91 | 41.83 |
| Llama2 7B Q4_0 (38 cores) | Quantized 4-bit | 671.31 | 65.95 |
Observations:
- F16 (Float16) vs. Quantized models: The M2 Max delivers impressive processing speeds for both F16 and quantized models. The quantized models, particularly Q4_0, show slightly lower processing speeds, but significantly faster generation speeds, showcasing the benefits of reduced model size.
- Impact of GPU cores: As expected, models running on 38 cores show a significant performance improvement compared to the 30-core models.
Strengths:
- Faster processing and generation speeds: The M2 Max excels in both processing and generating text, making it suitable for real-time interactions and applications like chatbots.
- Local inference for smaller LLMs: The M2 Max is ideal for running smaller LLMs like Llama 2 7B locally, delivering high-quality results without the need for specialized cloud infrastructure.
Weaknesses:
- Limited data for larger LLMs: While impressive for smaller models, the lack of benchmarks for larger LLMs like Llama 3 on the M2 Max limits its applicability for such tasks.
- Cost: The M2 Max is a premium device, which means it can be expensive for individuals and smaller teams.
Use Cases:
- Chatbots and conversational AI: The M2 Max's fast generation speeds enable real-time conversations and fluid interactions.
- Text generation and summarization: Its processing power makes it suitable for tasks like creating content, generating summaries, and translating languages.
- Local model experimentation and prototyping: The M2 Max provides a powerful platform for exploring and experimenting with smaller LLM models locally.
NVIDIA A100SXM80GB: Powerhouse for Enterprise-grade LLMs
The NVIDIA A100SXM80GB is a high-end GPU designed for demanding workloads, including training and inferring large language models. It comes with powerful hardware:
- High memory bandwidth: With 80GB of high-bandwidth memory, the A100 offers fast and efficient data access, crucial for managing massive LLMs. Imagine this as a vast library with rapid access to information, allowing the model to process data much faster.
- Tensor cores: The A100 is equipped with Tensor cores, specialized hardware for accelerating matrix operations, which are fundamental to deep learning models. Picture this as having specialized workers for matrix calculations, significantly speeding up the process.
- Support for FP16, INT8, and FP8: The A100 supports different precision formats, including FP16, INT8, and FP8, allowing for efficient model quantization. It's like having multiple language translators for your model, allowing it to communicate with different types of data, making it more adaptable and efficient.
Performance Analysis of NVIDIA A100SXM80GB
The A100 is known for its exceptional performance with large LLMs. While we have some benchmarks, we lack data for Llama 2 on the A100.
Table 2: Token Speeds for Llama 3 on NVIDIA A100 (Tokens/second)
| Model | Quantization | Generation (Tokens/s) |
|---|---|---|
| Llama3 8B Q4KM | Quantized 4-bit (K_M) | 133.38 |
| Llama3 8B F16 | Float16 | 53.18 |
| Llama3 70B Q4KM | Quantized 4-bit (K_M) | 24.33 |
Observations:
- Quantization Impact: The A100 demonstrates impressive performance gains with quantization, especially when using the Q4KM format for Llama 3 8B and 70B.
- Model Size Impact: While we don't have data for Llama 2 on the A100, it's expected that the A100 would handle smaller models like Llama 2 with even greater speed, making it equally well-suited for both smaller and larger models.
Strengths:
- Outstanding performance with large LLMs: The A100 excels at handling massive models like Llama 3 70B, showcasing impressive speed and efficiency.
- Extensive support for various models and frameworks: The A100 provides excellent support for various LLMs and deep learning frameworks, making it a versatile option for research and deployment.
- Scalability: The A100 can be scaled to handle even larger models, offering the flexibility to grow with your needs.
Weaknesses:
- High cost: Like the M2 Max, the A100 is an expensive device, often requiring a significant investment.
- Power consumption: The A100 is known for its high power consumption, necessitating efficient cooling systems and potentially higher energy bills.
Use Cases:
- Training and inferring large LLMs: The A100 is perfect for training and deploying large-scale LLMs, offering immense performance and scalability.
- Research and development: The A100 provides a stable and powerful platform for researchers and developers to experiment with and refine advanced AI models.
- Enterprise-grade AI solutions: The A100's capabilities make it ideal for developing and deploying enterprise-grade AI solutions requiring high performance and stability.
Key Factors to Consider When Choosing Between Apple M2 Max 400GB 30cores and NVIDIA A100SXM80GB
Here's a breakdown of the key factors to consider when making your choice:
1. Model Size
- M2 Max: Ideal for smaller models like Llama 2 7B, offering fast processing and generation speeds.
- A100: Ideal for larger models like Llama 3 70B, delivering high performance and scalability.
2. Performance Requirements
- M2 Max: Suitable for tasks requiring fast generation speeds, such as chatbots, real-time interactions, and text generation.
- A100: Excellent for demanding tasks like training large models, deploying enterprise-grade AI solutions, and running complex simulations.
3. Budget
- M2 Max: A premium device, it comes with a higher price tag.
- A100: The A100 is an expensive option, requiring a significant investment.
4. Power Consumption
- M2 Max: Offers lower power consumption compared to the A100.
- A100: High power consumption can impact energy bills and require efficient cooling systems.
5. Supported LLMs and Frameworks
- M2 Max: Limited data on support for larger LLMs like Llama 3, but excellent for smaller models.
- A100: Provides extensive support for a wide range of LLMs and deep learning frameworks, offering greater flexibility.
6. Scalability
- M2 Max: Limited scalability for larger models.
- A100: Offers excellent scalability, allowing you to handle even larger models.
7. Quantization Options
- M2 Max: Supports various quantization techniques, enabling efficient model optimization.
- A100: Offers extensive support for FP16, INT8, and FP8 precision formats, allowing for efficient model quantization.
8. Use Cases
- M2 Max: Ideal for chatbots, conversational AI, text generation, summarization, and local model experimentation.
- A100: Perfect for training and deploying large LLMs, research and development, and enterprise-grade AI solutions.
Practical Recommendations
Here are some practical recommendations based on your specific needs:
- For developers working with smaller LLMs: The M2 Max offers a cost-effective and powerful option for handling Llama 2 7B and similar models.
- For researchers and developers working with large LLMs: The A100 is the go-to choice for training and deploying models like Llama 3 70B, offering exceptional performance and scalability.
- For small businesses and startups: The M2 Max might be a good starting point for developing and prototyping AI applications.
- For large enterprises: The A100 provides the power and scalability needed to handle enterprise-grade AI solutions requiring high performance and reliability.
FAQ
Q: What is quantization, and how does it benefit LLM inference? A: Quantization is a technique that reduces the size of a model by representing its parameters using fewer bits. Think of it as replacing a high-resolution image with a lower-resolution version, but still preserving the essential details. This reduces memory footprint and allows for faster model inference, as the model needs to process less data.
Q: What are the advantages of using a GPU for LLM inference? A: GPUs are specialized processors optimized for parallel processing, making them ideal for tasks like matrix operations and deep learning. Their massive parallel processing power significantly accelerates model inference compared to traditional CPUs.
Q: Can I run an LLM like Llama 3 70B on an Apple M2 Max? A: While the M2 Max is powerful, it's not designed for handling massive LLMs like Llama 3 70B efficiently. It's recommended to use the NVIDIA A100 or similar high-performance GPUs for such tasks.
Q: Which device is better for training LLMs? A: The A100 is the more suitable option for training large LLMs due to its high memory bandwidth, Tensor cores, and scalability.
Keywords
LLM, Large Language Model, Apple M2 Max, NVIDIA A100, GPU, CPU, Memory Bandwidth, GPU Cores, Quantization, Inference, Model Training, Performance, Speed, Token Speed, Llama 2, Llama 3, Cost, Power Consumption, Use Cases, Chatbot, Real-Time Interaction, Content Generation, AI, Deep Learning, Enterprise-grade AI, Research and Development, Scalability, AI Solutions.