8 Key Factors to Consider When Choosing Between Apple M2 100gb 10cores and NVIDIA RTX 5000 Ada 32GB for AI
Introduction
The world of AI is rapidly evolving, with Large Language Models (LLMs) becoming increasingly powerful and versatile. One of the key challenges for developers and researchers is finding the right hardware to run these models efficiently. Two popular choices for this task are the Apple M2 100GB 10-Core chip and the NVIDIA RTX5000Ada_32GB GPU. This article will compare these two devices in detail, highlighting the strengths and weaknesses of each, and helping you make an informed decision based on your specific needs.
Understanding the Basics: A Quick Glimpse into LLMs and Hardware
Before diving into the comparison, let's have a quick chat about what LLMs are and why hardware matters. Think of an LLM like a super-smart chatbot that's been trained on a massive dataset of text and code. They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
But running these models requires a lot of processing power, which is where hardware comes into play. The right hardware can make the difference between a smooth, efficient experience and a frustrating, slow one.
Comparison of Apple M2 100GB 10-Cores and NVIDIA RTX5000Ada_32GB
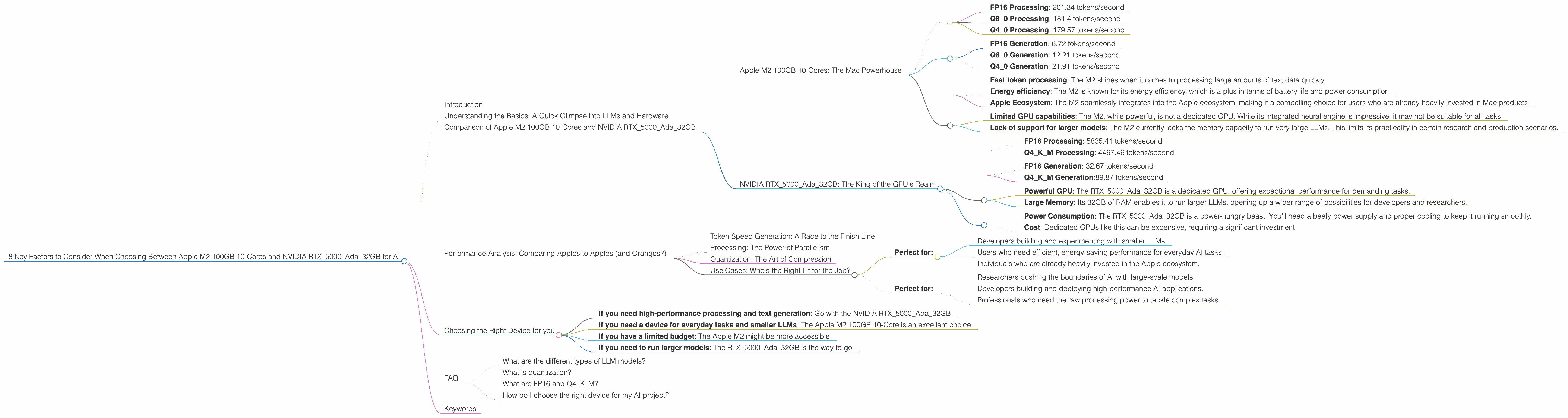
Apple M2 100GB 10-Cores: The Mac Powerhouse
The Apple M2 is built with speed in mind. The M2 chip boasts a powerful, energy-efficient architecture specifically designed for machine learning. Let's see how it performs with different LLM models:
Processing Llama2 7B:
- FP16 Processing: 201.34 tokens/second
- Q8_0 Processing: 181.4 tokens/second
- Q4_0 Processing: 179.57 tokens/second
Generating Text with Llama2 7B:
- FP16 Generation: 6.72 tokens/second
- Q8_0 Generation: 12.21 tokens/second
- Q4_0 Generation: 21.91 tokens/second
What does it mean? The M2 delivers impressive performance with Llama2 7B. Its ability to process text quickly is noteworthy. Quantization, a technique that compresses model size and reduces memory usage, further enhances its capabilities.
Strengths:
- Fast token processing: The M2 shines when it comes to processing large amounts of text data quickly.
- Energy efficiency: The M2 is known for its energy efficiency, which is a plus in terms of battery life and power consumption.
- Apple Ecosystem: The M2 seamlessly integrates into the Apple ecosystem, making it a compelling choice for users who are already heavily invested in Mac products.
Weaknesses:
- Limited GPU capabilities: The M2, while powerful, is not a dedicated GPU. While its integrated neural engine is impressive, it may not be suitable for all tasks.
- Lack of support for larger models: The M2 currently lacks the memory capacity to run very large LLMs. This limits its practicality in certain research and production scenarios.
NVIDIA RTX5000Ada_32GB: The King of the GPU's Realm
Now let's dive into the world of dedicated GPUs. The NVIDIA RTX5000Ada_32GB is a powerhouse designed for intensive gaming and demanding applications like AI. This card is equipped with 32GB of RAM, which is significantly more than the M2, allowing it to handle larger models.
Processing Llama3 8B:
- FP16 Processing: 5835.41 tokens/second
- Q4KM Processing: 4467.46 tokens/second
Generating Text with Llama3 8B:
- FP16 Generation: 32.67 tokens/second
- Q4KM Generation:89.87 tokens/second
Important Note: We don't have data available for the RTX5000Ada_32GB running Llama3 70B. This is because the specific combination of hardware and LLM size is not readily available.
Strengths:
- Powerful GPU: The RTX5000Ada_32GB is a dedicated GPU, offering exceptional performance for demanding tasks.
- Large Memory: Its 32GB of RAM enables it to run larger LLMs, opening up a wider range of possibilities for developers and researchers.
Weaknesses:
- Power Consumption: The RTX5000Ada_32GB is a power-hungry beast. You'll need a beefy power supply and proper cooling to keep it running smoothly.
- Cost: Dedicated GPUs like this can be expensive, requiring a significant investment.
Performance Analysis: Comparing Apples to Apples (and Oranges?)
Token Speed Generation: A Race to the Finish Line
When it comes to generating text, the RTX5000Ada32GB emerges as the clear winner. It can generate tokens at a significantly faster rate than the M2, especially when using FP16 and Q4K_M quantization.
Think of it like this: Imagine you're writing a novel. The RTX5000Ada_32GB is like having a team of super-fast typists, churning out words at lightning speed. The M2 is more like a single, efficient typist who can still get the job done, but not as quickly.
Processing: The Power of Parallelism
The RTX5000Ada_32GB also takes the lead in processing power. It can process tokens at an astounding pace, thanks to its dedicated GPU. Think of it like having multiple lanes on a highway, allowing you to process information simultaneously. The M2, while fast, only has one lane to work with,
Quantization: The Art of Compression
Quantization is a technique used to reduce the size of models and make them more efficient. The RTX5000Ada32GB boasts impressive performance, particularly with Q4K_M quantization. It can handle larger LLMs with ease. While the M2 also supports quantization, its performance may be limited by its memory capacity.
Use Cases: Who's the Right Fit for the Job?
Apple M2 100GB 10-Core: The Everyday AI Companion
- Perfect for:
- Developers building and experimenting with smaller LLMs.
- Users who need efficient, energy-saving performance for everyday AI tasks.
- Individuals who are already heavily invested in the Apple ecosystem.
NVIDIA RTX5000Ada_32GB: The High-Performance Powerhouse
- Perfect for:
- Researchers pushing the boundaries of AI with large-scale models.
- Developers building and deploying high-performance AI applications.
- Professionals who need the raw processing power to tackle complex tasks.
Choosing the Right Device for you
Ultimately, the best device for you will depend on your specific use case and budget. Here's a quick guide to help you make the right choice:
- If you need high-performance processing and text generation: Go with the NVIDIA RTX5000Ada_32GB.
- If you need a device for everyday tasks and smaller LLMs: The Apple M2 100GB 10-Core is an excellent choice.
- If you have a limited budget: The Apple M2 might be more accessible.
- If you need to run larger models: The RTX5000Ada_32GB is the way to go.
FAQ
What are the different types of LLM models?
LLM models come in various sizes, ranging from small models like Llama 7B to enormous ones like GPT-3. The size of the model influences its capabilities and the resources needed to run it.
What is quantization?
Quantization is a technique that compresses the size of a model by reducing the number of bits used to represent its data. This makes the model smaller, faster, and more efficient.
What are FP16 and Q4KM?
These are different quantization schemes used to reduce the size and improve the efficiency of LLM models. FP16 uses half-precision floating-point numbers, while Q4KM uses 4 bits per number and combines it with a technique called "K-means" clustering.
How do I choose the right device for my AI project?
Consider your LLM model needs: What size model must you run? What is your budget? What is your priority: speed, efficiency, or cost?
Keywords
LLM, Large Language Model, Apple M2, NVIDIA RTX5000Ada32GB, Llama2, Llama3, GPU, CPU, token speed, processing, generation, quantization, FP16, Q4K_M, AI, Artificial Intelligence, machine learning, development, research, performance, efficiency, cost, use case, everyday, high-performance, power, memory, speed, budget, choose.