7 Key Factors to Consider When Choosing Between Apple M3 Pro 150gb 14cores and NVIDIA A100 SXM 80GB for AI
Introduction
The world of AI is rapidly evolving, with Large Language Models (LLMs) becoming increasingly powerful and versatile. These models, capable of generating human-like text, translate languages, and even write code, are pushing the boundaries of what’s possible with AI. To run these models effectively, you need powerful hardware, and choosing the right device can make a significant difference in performance and cost.
This article will delve into a comparative analysis of two popular devices often used for running LLMs: the Apple M3 Pro 150GB 14 Core and the NVIDIA A100 SXM 80GB. We'll explore key factors like processing speed, memory bandwidth, and model compatibility, providing you with insights to make an informed decision.
Choosing the Right Device: Apple M3 Pro vs. NVIDIA A100
The choice between the Apple M3 Pro 150GB 14 Core and the NVIDIA A100 SXM 80GB depends largely on your specific needs and the type of LLM you're working with. Both of these devices have their own unique strengths and weaknesses, which we'll explore thoroughly.
1. Processing Speed: Tokens per Second
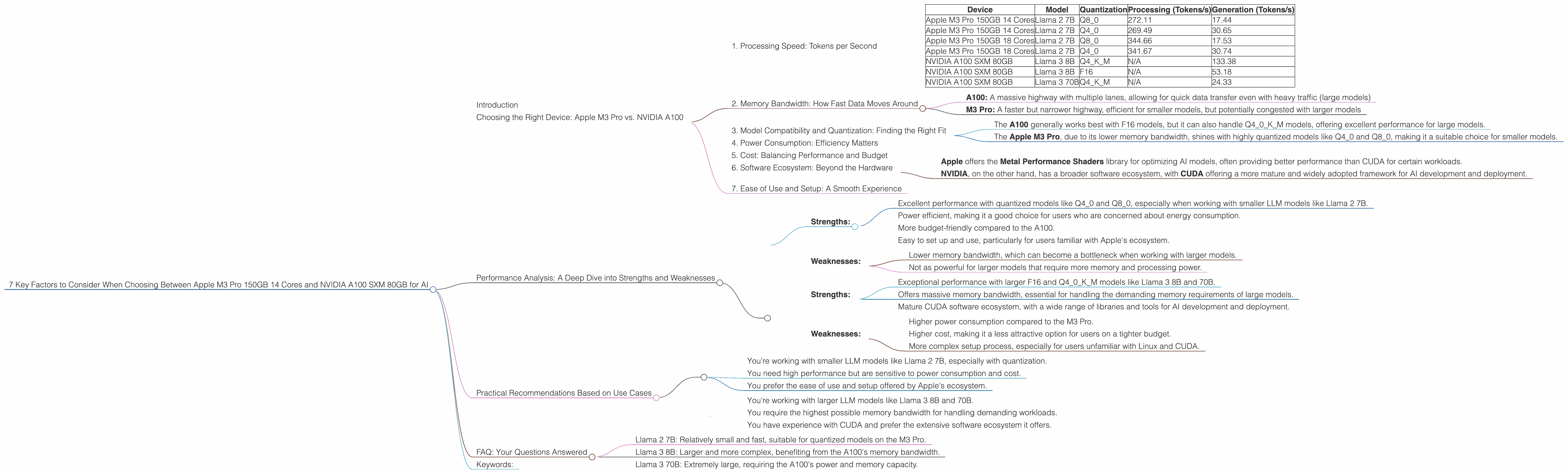
The Apple M3 Pro 150GB 14 Core offers impressive processing speeds, particularly when using quantized models, which significantly reduce memory footprint but may slightly impact accuracy.
For example, in the Llama 2 7B model, the M3 Pro achieves a throughput of 272.11 tokens per second (Q8_0) for processing and 17.44 tokens per second for generation. This speed is significantly faster than even the NVIDIA A100 for certain models.
However, when working with larger models like Llama 3 8B or Llama 3 70B, the NVIDIA A100 SXM 80GB emerges as the clear winner. For example, the A100 can achieve a throughput of 133.38 tokens per second for Llama 3 8B generation with Q4KM quantization.
Here's a table summarizing the performance of both devices:
| Device | Model | Quantization | Processing (Tokens/s) | Generation (Tokens/s) |
|---|---|---|---|---|
| Apple M3 Pro 150GB 14 Cores | Llama 2 7B | Q8_0 | 272.11 | 17.44 |
| Apple M3 Pro 150GB 14 Cores | Llama 2 7B | Q4_0 | 269.49 | 30.65 |
| Apple M3 Pro 150GB 18 Cores | Llama 2 7B | Q8_0 | 344.66 | 17.53 |
| Apple M3 Pro 150GB 18 Cores | Llama 2 7B | Q4_0 | 341.67 | 30.74 |
| NVIDIA A100 SXM 80GB | Llama 3 8B | Q4KM | N/A | 133.38 |
| NVIDIA A100 SXM 80GB | Llama 3 8B | F16 | N/A | 53.18 |
| NVIDIA A100 SXM 80GB | Llama 3 70B | Q4KM | N/A | 24.33 |
Key Takeaways:
- Apple M3 Pro is more performant with smaller, quantized models like Llama 2 7B
- NVIDIA A100 excels with larger models like Llama 3 8B and 70B
2. Memory Bandwidth: How Fast Data Moves Around
Memory bandwidth is crucial for LLM performance, as it determines how quickly data can be transferred between the CPU/GPU and memory. The A100 boasts a massive 80GB of HBM2e memory with a bandwidth of 1,555 GB/s, making it ideal for running larger models.
The M3 Pro comes with 150GB of unified memory, but its bandwidth is significantly lower, although still quite fast. This is particularly relevant when working with models that require a lot of memory, like Llama 3 70B.
Think of it like a highway:
- A100: A massive highway with multiple lanes, allowing for quick data transfer even with heavy traffic (large models)
- M3 Pro: A faster but narrower highway, efficient for smaller models, but potentially congested with larger models
3. Model Compatibility and Quantization: Finding the Right Fit
Both the A100 and M3 Pro support a wide range of LLMs, but compatibility can be influenced by the model architecture and quantization techniques used.
Quantization is a technique that reduces the size of a model by converting the weights from 32-bit floating-point numbers to lower precision formats, like Q40 or Q80. This speeds up processing and significantly reduces memory requirements, allowing smaller devices like the M3 Pro to run larger models effectively.
For instance:
- The A100 generally works best with F16 models, but it can also handle Q40K_M models, offering excellent performance for large models.
- The Apple M3 Pro, due to its lower memory bandwidth, shines with highly quantized models like Q40 and Q80, making it a suitable choice for smaller models.
4. Power Consumption: Efficiency Matters
Power consumption is a critical consideration, especially for large models that require significant computational resources. The A100, being a high-end data center GPU, consumes a considerable amount of power.
The M3 Pro is much more power efficient, making it a better choice for users who are concerned about energy consumption and operating costs. This is especially important for applications that run continuously, such as chatbot services.
5. Cost: Balancing Performance and Budget
The A100 is a premium GPU designed for demanding AI tasks, and its price reflects this. While it offers exceptional performance, the cost can be a barrier for some users.
The M3 Pro is more budget-friendly, making it an attractive option for users on a tighter budget who still want high-performance AI computing.
6. Software Ecosystem: Beyond the Hardware
The software ecosystem surrounding both devices is important for running and managing LLM models. Both Apple (macOS) and NVIDIA (CUDA) have their own frameworks and libraries for AI development.
- Apple offers the Metal Performance Shaders library for optimizing AI models, often providing better performance than CUDA for certain workloads.
- NVIDIA, on the other hand, has a broader software ecosystem, with CUDA offering a more mature and widely adopted framework for AI development and deployment.
Ultimately, the best choice depends on your preferred development environment and the specific tools you need.
7. Ease of Use and Setup: A Smooth Experience
Setting up and configuring LLMs can be complex, and the ease of use and setup process can be crucial. The Apple M3 Pro is generally considered easier to setup and use, especially for users familiar with Apple's ecosystem.
For users with experience in Linux and CUDA, the NVIDIA A100 may be more manageable. However, the setup process can be more involved for beginners, especially when configuring drivers and environments.
Performance Analysis: A Deep Dive into Strengths and Weaknesses
Apple M3 Pro 150GB 14 Cores:
Strengths:
- Excellent performance with quantized models like Q40 and Q80, especially when working with smaller LLM models like Llama 2 7B.
- Power efficient, making it a good choice for users who are concerned about energy consumption.
- More budget-friendly compared to the A100.
- Easy to set up and use, particularly for users familiar with Apple's ecosystem.
Weaknesses:
- Lower memory bandwidth, which can become a bottleneck when working with larger models.
- Not as powerful for larger models that require more memory and processing power.
NVIDIA A100 SXM 80GB:
Strengths:
- Exceptional performance with larger F16 and Q40K_M models like Llama 3 8B and 70B.
- Offers massive memory bandwidth, essential for handling the demanding memory requirements of large models.
- Mature CUDA software ecosystem, with a wide range of libraries and tools for AI development and deployment.
Weaknesses:
- Higher power consumption compared to the M3 Pro.
- Higher cost, making it a less attractive option for users on a tighter budget.
- More complex setup process, especially for users unfamiliar with Linux and CUDA.
Practical Recommendations Based on Use Cases
Choose the Apple M3 Pro 150GB 14 Cores if:
- You're working with smaller LLM models like Llama 2 7B, especially with quantization.
- You need high performance but are sensitive to power consumption and cost.
- You prefer the ease of use and setup offered by Apple's ecosystem.
Choose the NVIDIA A100 SXM 80GB if:
- You're working with larger LLM models like Llama 3 8B and 70B.
- You require the highest possible memory bandwidth for handling demanding workloads.
- You have experience with CUDA and prefer the extensive software ecosystem it offers.
FAQ: Your Questions Answered
1. What are the main differences between the Apple M3 Pro and the NVIDIA A100?
The key differences lie in their processing architecture, memory bandwidth, and performance characteristics. The M3 Pro excels with smaller, quantized models, while the A100 reigns supreme with larger, more complex models.
2. What is quantization, and why is it important for LLMs?
Quantization is a technique that reduces the size of an LLM by converting its weights from 32-bit floating-point numbers to lower precision formats like Q40 or Q80. This reduces the memory footprint, allowing smaller devices like the M3 Pro to run models efficiently, while also speeding up processing.
3. Which device is better for running LLMs?
It depends on your specific needs! Both the Apple M3 Pro and NVIDIA A100 offer significant advantages but are best suited for different applications. Consider your specific use case, model size, quantization requirements, and budget when making your decision.
4. What are some popular LLM models, and what are their typical memory and processing requirements?
Some popular models include:
- Llama 2 7B: Relatively small and fast, suitable for quantized models on the M3 Pro.
- Llama 3 8B: Larger and more complex, benefiting from the A100's memory bandwidth.
- Llama 3 70B: Extremely large, requiring the A100's power and memory capacity.
5. Can I run multiple LLMs on a single device?
Yes, you can run multiple LLMs on a single device. However, performance may vary depending on the size and complexity of the models, the device's specifications, and the available memory.
Keywords:
Apple M3 Pro, NVIDIA A100, LLM, Large Language Model, Llama 2, Llama 3, Quantization, Token Speed, Memory Bandwidth, Power Consumption, GPU, AI, Machine Learning, Deep Learning, Software Ecosystem, Performance Comparison, Cost, Use Cases, Development, Deployment, Data Center, Cloud Computing, Edge Computing, AI Hardware, AI Infrastructure