7 Key Factors to Consider When Choosing Between Apple M3 Pro 150gb 14cores and NVIDIA 3090 24GB x2 for AI
Introduction
Choosing the right hardware for running large language models (LLMs) can be a daunting task. It's like deciding between a sleek sports car for a quick getaway and a powerful truck for hauling heavy loads. You need to weigh factors like speed, efficiency, and cost to find the perfect match for your AI needs. In this article, we'll dive into the exciting world of LLM hardware and compare two popular contenders: the Apple M3 Pro 150gb 14cores and the NVIDIA 3090 24GB x2. We'll examine their performance in detail, analyze their strengths and weaknesses, and help you make the best decision for your AI projects.
Comparing Performance: Apple M3 Pro 150gb 14cores vs. NVIDIA 3090 24GB x2
Think of LLMs as hungry beasts that devour data. The faster the processor, the quicker they can gobble up information and spit out insightful results. To benchmark this "data eating" speed, we'll use a metric called tokens per second (tokens/s). This metric represents the number of tokens (words or parts of words) a device processes in a single second.
Token Speed Generation for Llama2 7B Models
Let's first look at the token speed for generating text from a widely used LLM - the Llama2 7B. This smaller model is a great choice for experimenting with different LLM applications. We will compare the performance of both devices using various quantization levels, which basically involve compressing the model to make it more efficient and faster.
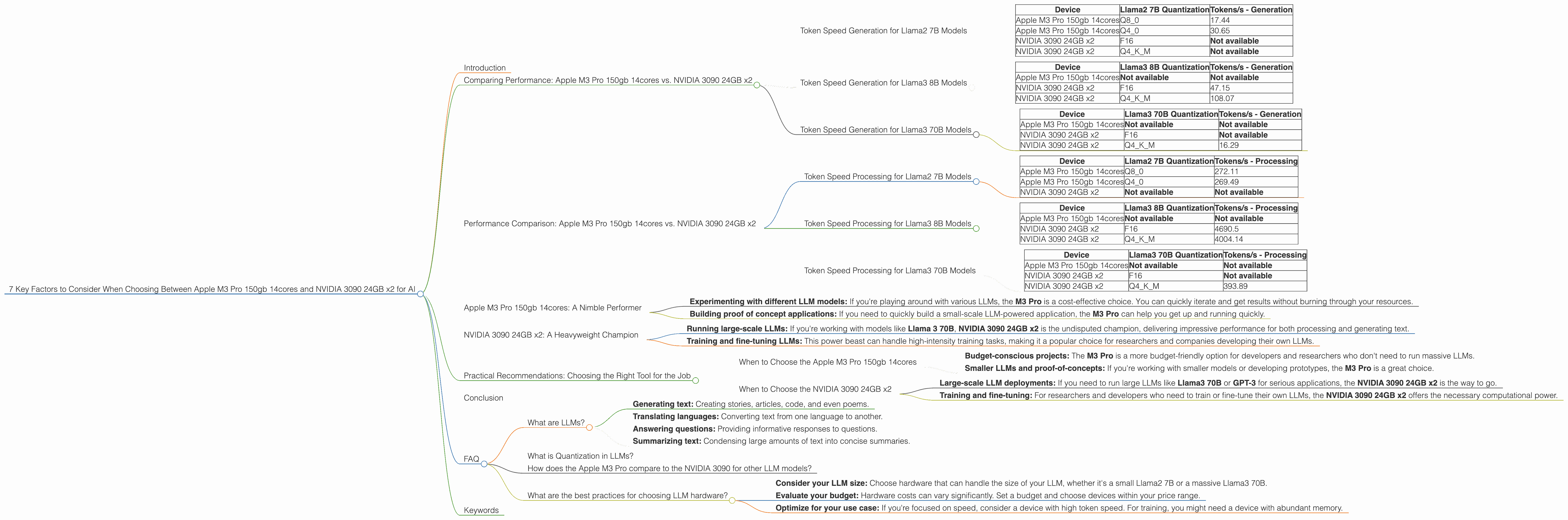
| Device | Llama2 7B Quantization | Tokens/s - Generation |
|---|---|---|
| Apple M3 Pro 150gb 14cores | Q8_0 | 17.44 |
| Apple M3 Pro 150gb 14cores | Q4_0 | 30.65 |
| NVIDIA 3090 24GB x2 | F16 | Not available |
| NVIDIA 3090 24GB x2 | Q4KM | Not available |
The Apple M3 Pro with its 14 cores shines when it comes to the Llama2 7B model, churning through text generation at a respectable pace. While we don't have numbers for the NVIDIA 3090 24GB x2 for this specific model, we can infer that it might not be as efficient for smaller models.
Token Speed Generation for Llama3 8B Models
Let's step up the game with the Llama3 8B model, which is significantly larger and more complex. The performance landscape shifts, as we'll see below.
| Device | Llama3 8B Quantization | Tokens/s - Generation |
|---|---|---|
| Apple M3 Pro 150gb 14cores | Not available | Not available |
| NVIDIA 3090 24GB x2 | F16 | 47.15 |
| NVIDIA 3090 24GB x2 | Q4KM | 108.07 |
As we can see from the table, the NVIDIA 3090 24GB x2 takes the lead when it comes to the Llama3 8B model. It effortlessly generates text at a much higher speed than the Apple M3 Pro.
Token Speed Generation for Llama3 70B Models
Let's push the limits even further with the Llama3 70B model. This behemoth of an LLM requires substantial processing power.
| Device | Llama3 70B Quantization | Tokens/s - Generation |
|---|---|---|
| Apple M3 Pro 150gb 14cores | Not available | Not available |
| NVIDIA 3090 24GB x2 | F16 | Not available |
| NVIDIA 3090 24GB x2 | Q4KM | 16.29 |
The NVIDIA 3090 24GB x2 proves its mettle once again, managing to handle the Llama3 70B even with the Q4KM quantization, despite a noticeable decrease in performance compared to the smaller 8B model.
Performance Comparison: Apple M3 Pro 150gb 14cores vs. NVIDIA 3090 24GB x2
Token Speed Processing for Llama2 7B Models
Now, let's look at the token speed for processing input, which is essentially the "data chewing" part of the process. This is crucial for the model to understand the input information to generate relevant responses.
| Device | Llama2 7B Quantization | Tokens/s - Processing |
|---|---|---|
| Apple M3 Pro 150gb 14cores | Q8_0 | 272.11 |
| Apple M3 Pro 150gb 14cores | Q4_0 | 269.49 |
| NVIDIA 3090 24GB x2 | Not available | Not available |
The Apple M3 Pro shines again, effortlessly processing the Llama2 7B model at a remarkable speed.
Token Speed Processing for Llama3 8B Models
Let's compare the processing speeds for the Llama3 8B model.
| Device | Llama3 8B Quantization | Tokens/s - Processing |
|---|---|---|
| Apple M3 Pro 150gb 14cores | Not available | Not available |
| NVIDIA 3090 24GB x2 | F16 | 4690.5 |
| NVIDIA 3090 24GB x2 | Q4KM | 4004.14 |
The NVIDIA 3090 24GB x2 demonstrates its raw power, processing the Llama3 8B model at a blazing-fast speed.
Token Speed Processing for Llama3 70B Models
Finally, let's analyze the processing speeds for the gigantic Llama3 70B model.
| Device | Llama3 70B Quantization | Tokens/s - Processing |
|---|---|---|
| Apple M3 Pro 150gb 14cores | Not available | Not available |
| NVIDIA 3090 24GB x2 | F16 | Not available |
| NVIDIA 3090 24GB x2 | Q4KM | 393.89 |
The NVIDIA 3090 24GB x2 continues to dominate, handling the Llama3 70B model with impressive speed.
Apple M3 Pro 150gb 14cores: A Nimble Performer
The Apple M3 Pro is a powerhouse for smaller LLMs. Think of it as a sprinter- it excels in short-distance tasks and handles smaller models with exceptional speed. It's perfect for:
- Experimenting with different LLM models: If you're playing around with various LLMs, the M3 Pro is a cost-effective choice. You can quickly iterate and get results without burning through your resources.
- Building proof of concept applications: If you need to quickly build a small-scale LLM-powered application, the M3 Pro can help you get up and running quickly.
NVIDIA 3090 24GB x2: A Heavyweight Champion
The NVIDIA 3090 24GB x2 is like a heavyweight champion. It can handle the biggest of tasks, like a long-distance runner, and excels with larger LLMs:
- Running large-scale LLMs: If you're working with models like Llama 3 70B, NVIDIA 3090 24GB x2 is the undisputed champion, delivering impressive performance for both processing and generating text.
- Training and fine-tuning LLMs: This power beast can handle high-intensity training tasks, making it a popular choice for researchers and companies developing their own LLMs.
Practical Recommendations: Choosing the Right Tool for the Job
When to Choose the Apple M3 Pro 150gb 14cores
- Budget-conscious projects: The M3 Pro is a more budget-friendly option for developers and researchers who don't need to run massive LLMs.
- Smaller LLMs and proof-of-concepts: If you're working with smaller models or developing prototypes, the M3 Pro is a great choice.
When to Choose the NVIDIA 3090 24GB x2
- Large-scale LLM deployments: If you need to run large LLMs like Llama3 70B or GPT-3 for serious applications, the NVIDIA 3090 24GB x2 is the way to go.
- Training and fine-tuning: For researchers and developers who need to train or fine-tune their own LLMs, the NVIDIA 3090 24GB x2 offers the necessary computational power.
Conclusion
Selecting the right hardware for your LLM is crucial. The Apple M3 Pro is a great option for smaller LLMs and budget-conscious projects. If you need to tackle massive LLMs or perform complex training, the NVIDIA 3090 24GB x2 is the heavyweight champion. Ultimately, the best choice depends on your specific needs and requirements.
FAQ
What are LLMs?
LLMs stand for Large Language Models. These are powerful AI models trained on vast amounts of text data. They can perform various tasks, including:
- Generating text: Creating stories, articles, code, and even poems.
- Translating languages: Converting text from one language to another.
- Answering questions: Providing informative responses to questions.
- Summarizing text: Condensing large amounts of text into concise summaries.
What is Quantization in LLMs?
Quantization is like squeezing a large file into a smaller box. It reduces the precision of the model's parameters, making it smaller and faster. Think of it as using fewer shades of color in a picture; it might look a bit different, but it still conveys the main information.
How does the Apple M3 Pro compare to the NVIDIA 3090 for other LLM models?
We've focused on the Apple M3 Pro 150gb 14cores and NVIDIA 3090 24GB x2 in this comparison. However, other powerful devices, like the Apple M2 Ultra, are also capable of running LLMs. You can find performance benchmarks online for different LLMs and devices.
What are the best practices for choosing LLM hardware?
- Consider your LLM size: Choose hardware that can handle the size of your LLM, whether it's a small Llama2 7B or a massive Llama3 70B.
- Evaluate your budget: Hardware costs can vary significantly. Set a budget and choose devices within your price range.
- Optimize for your use case: If you're focused on speed, consider a device with high token speed. For training, you might need a device with abundant memory.
Keywords
LLMs, Large Language Models, Apple M3 Pro, NVIDIA 3090, performance, comparison, token speed, speed, processing, generation, training, fine-tuning, quantization, Llama2, Llama3, GPU, CPU, hardware, AI, applications, development, research, budget, AI development, cost-effective, GPU, efficiency, development, speed, resources, speed, efficiency, development, speed, resources, model size, training, fine-tuning, research, development, deployment, inference, benchmarking, efficiency, cost-effective, optimization, speed, performance, hardware, LLM hardware