7 Key Factors to Consider When Choosing Between Apple M2 Ultra 800gb 60cores and NVIDIA 4090 24GB for AI
Introduction
The world of AI is exploding, and with it, the need for powerful hardware to run these complex models. Two top contenders in the race for AI supremacy are the Apple M2 Ultra 800GB 60-cores and the NVIDIA 4090 24GB. Both offer incredible performance, but choosing the right one depends on your specific needs and the LLM you are running. In this article, we'll dive deep into a performance comparison of these two behemoths, exploring key factors that can help you decide which one fits your AI journey best.
Imagine you're training a large language model, like a 70-billion parameter behemoth, on your computer. It's like trying to fit a gigantic elephant into a tiny room. You need a powerful machine, a machine that can handle the computational demands of such a complex task. Both the Apple M2 Ultra 800GB and the NVIDIA 4090 24GB are designed for such a purpose.
Key Factors to Consider When Choosing Between Apple M2 Ultra 800GB 60-cores and NVIDIA 4090 24GB for AI
Think of choosing between the M2 Ultra and the 4090 as picking the right tool for the job. Both are powerful, but they excel in different areas, just like a hammer is great for pounding nails but not so good for driving screws!
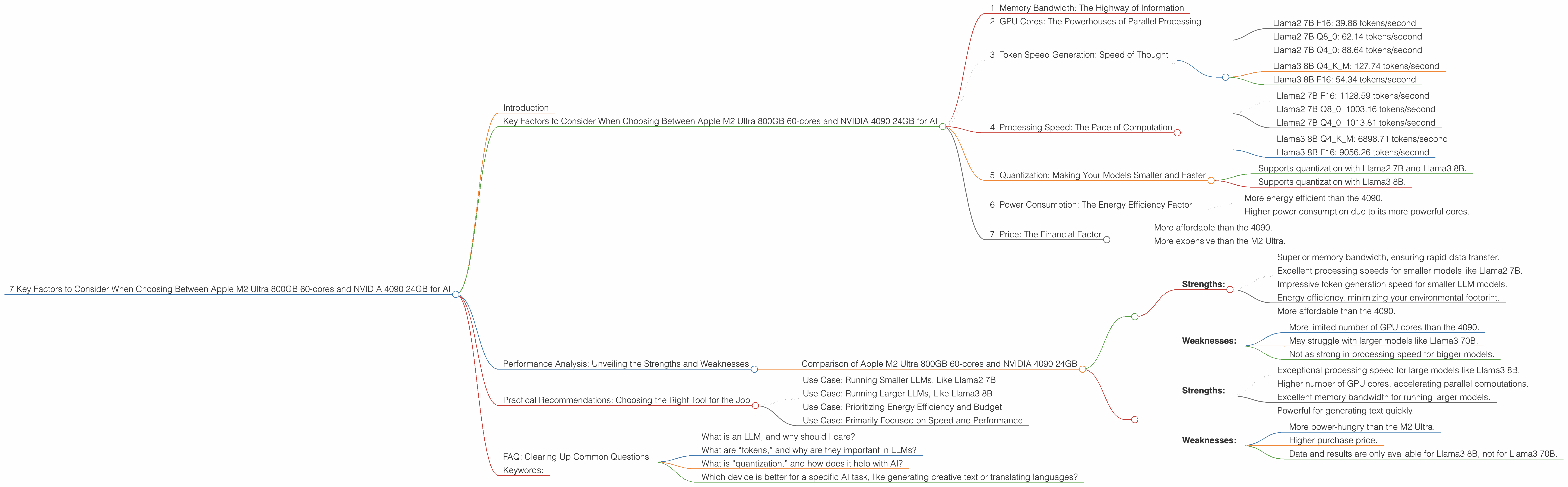
1. Memory Bandwidth: The Highway of Information
The speed at which your computer can move data around its memory is crucial for AI models. Think of it as a highway for information. The wider the highway (more bandwidth), the faster your model can churn through data and generate responses. The Apple M2 Ultra boasts incredible memory bandwidth, reaching 800GB/s! The NVIDIA 4090, while powerful, generally has lower memory bandwidth.
M2 Ultra: 800GB/s 4090: Varies depending on the specific model, but usually lower than the M2 Ultra
2. GPU Cores: The Powerhouses of Parallel Processing
These are the core units dedicated to handling complex calculations, the core units that work in tandem for AI inference. The more GPU cores you have, the more calculations your machine can perform at once. The 4090 packs a punch with its massive number of cores, while the M2 Ultra maintains a respectable number.
M2 Ultra: 60 (base) 4090: More than the M2 Ultra
3. Token Speed Generation: Speed of Thought
Token speed generation is the speed at which your AI model can process and generate text. This metric is crucial for real-time applications and interactive experiences. The faster the token generation, the more fluent and responsive your AI model feels.
M2 Ultra: * Llama2 7B F16: 39.86 tokens/second * Llama2 7B Q80: 62.14 tokens/second * Llama2 7B Q40: 88.64 tokens/second
4090: * Llama3 8B Q4KM: 127.74 tokens/second * Llama3 8B F16: 54.34 tokens/second
Note: The data shows that the 4090 generally outperforms the M2 Ultra in token generation. The M2 Ultra, however, excels in processing speed (see the next section).
4. Processing Speed: The Pace of Computation
Processing speed, also known as inference speed, is the speed at which your AI model can perform the calculations needed to understand and generate text. The faster the processing, the quicker your model can analyze text, translate languages, and answer questions.
M2 Ultra: * Llama2 7B F16: 1128.59 tokens/second * Llama2 7B Q80: 1003.16 tokens/second * Llama2 7B Q40: 1013.81 tokens/second
4090: * Llama3 8B Q4KM: 6898.71 tokens/second * Llama3 8B F16: 9056.26 tokens/second
Note: The data shows that the 4090 significantly outperforms the M2 Ultra in processing speed. This is primarily due to the 4090's higher number of GPU cores.
5. Quantization: Making Your Models Smaller and Faster
Quantization is a technique that reduces the size of your AI model while maintaining its performance. This can be crucial for devices with limited memory or when you need to deploy your model on a resource-constrained platform. Think of it as compressing a large file to make it smaller and easier to share.
M2 Ultra: * Supports quantization with Llama2 7B and Llama3 8B.
4090: * Supports quantization with Llama3 8B.
Note: The M2 Ultra and the 4090 both offer quantization capabilities for certain models. This is beneficial for optimizing performance and resource utilization.
6. Power Consumption: The Energy Efficiency Factor
Power consumption is the amount of energy your device uses. This is a critical factor, especially for users who want to minimize their environmental impact or operate their AI models on battery power. The M2 Ultra is known for its efficiency, while the 4090, with its powerful cores, consumes more energy.
M2 Ultra:
* More energy efficient than the 4090.
4090:
* Higher power consumption due to its more powerful cores.
7. Price: The Financial Factor
The price is a significant factor for anyone looking to buy a device for AI. The 4090, with its top-of-the-line performance, comes with a premium price tag. The M2 Ultra, while still high-end, is generally more affordable than the 4090.
M2 Ultra:
* More affordable than the 4090.
4090:
* More expensive than the M2 Ultra.
Performance Analysis: Unveiling the Strengths and Weaknesses
Comparison of Apple M2 Ultra 800GB 60-cores and NVIDIA 4090 24GB
Let's break down the performance numbers and compare the strengths and weaknesses of each device in the realm of AI.
M2 Ultra:
* Strengths:
* Superior memory bandwidth, ensuring rapid data transfer.
* Excellent processing speeds for smaller models like Llama2 7B.
* Impressive token generation speed for smaller LLM models.
* Energy efficiency, minimizing your environmental footprint.
* More affordable than the 4090.
* Weaknesses:
* More limited number of GPU cores than the 4090.
* May struggle with larger models like Llama3 70B.
* Not as strong in processing speed for bigger models.
4090:
* Strengths:
* Exceptional processing speed for large models like Llama3 8B.
* Higher number of GPU cores, accelerating parallel computations.
* Excellent memory bandwidth for running larger models.
* Powerful for generating text quickly.
* Weaknesses:
* More power-hungry than the M2 Ultra.
* Higher purchase price.
* Data and results are only available for Llama3 8B, not for Llama3 70B.
Practical Recommendations: Choosing the Right Tool for the Job
The best device for your AI needs depends on your specific use case and model requirements. Here are some practical recommendations:
Use Case: Running Smaller LLMs, Like Llama2 7B
If you're working with smaller LLMs, like the Llama2 7B, the Apple M2 Ultra is an excellent choice. Its impressive memory bandwidth and efficient design make it perfect for achieving fast processing and token generation speeds while keeping your energy consumption low.
Use Case: Running Larger LLMs, Like Llama3 8B
If you're working with larger LLMs, like the Llama3 8B, the NVIDIA 4090 might be the better pick due to its superior processing speed and impressive number of GPU cores. This combination can accelerate your AI computations and make your model run faster.
Use Case: Prioritizing Energy Efficiency and Budget
If you're looking for a device that is energy-efficient and fits your budget, the Apple M2 Ultra might be the best option.
Use Case: Primarily Focused on Speed and Performance
If speed and performance are your top priorities, the NVIDIA 4090 might be the better choice.
FAQ: Clearing Up Common Questions
What is an LLM, and why should I care?
LLMs, short for Large Language Models, are powerful AI models that can understand and generate human-like text. They're behind many cool applications like chatbots, translation tools, and even creative writing assistants. Think of it like having a super-intelligent friend who can write poems, translate languages, and answer your questions in a way that feels almost human!
What are “tokens,” and why are they important in LLMs?
Tokens are the building blocks of text in LLMs. They are like the words or characters your AI model uses to understand and generate text. The speed at which a model processes and generates these tokens impacts the overall performance, fluency, and responsiveness of the model.
What is “quantization,” and how does it help with AI?
Quantization is a process of reducing the size of your AI model without sacrificing too much performance. Think of it as compressing a large file so you can download and open it quickly on your phone. This technique saves valuable memory space and allows you to run your model on devices with limited resources.
Which device is better for a specific AI task, like generating creative text or translating languages?
The best device for a specific AI task depends on the size of the model you're using and the specific requirements of the task. For tasks involving smaller models, the M2 Ultra might be a good choice due to its efficiency. For tasks that demand fast processing and involve larger models, the 4090 might be more appropriate.
Keywords:
Apple M2 Ultra, NVIDIA 4090, LLM, Large Language Model, AI, Token Speed Generation, Processing Speed, Memory Bandwidth, GPU Cores, Quantization, Power Consumption, Inference, Llama2, Llama3, Performance, Comparison, Data, Practical Recommendations, Use Case, FAQ, keywords, SEO