6 Key Factors to Consider When Choosing Between Apple M2 Pro 200gb 16cores and NVIDIA RTX 6000 Ada 48GB for AI
Introduction
Running large language models (LLMs) locally is becoming increasingly popular, allowing developers and enthusiasts to experiment with cutting-edge AI without relying on cloud services. But with so many hardware options available, choosing the right device can be a daunting task.
This article dives deep into the performance differences between two powerful contenders: the Apple M2 Pro 200GB 16-core chip and the NVIDIA RTX 6000 Ada 48GB GPU. We'll analyze their strengths and weaknesses in real-world scenarios, helping you make an informed decision based on your specific needs and budget.
Why Choose Between an Apple M2 Pro and an NVIDIA RTX 6000 Ada?
Choosing between an Apple M2 Pro and an NVIDIA RTX 6000 Ada for AI tasks is like deciding between a cheetah and a greyhound for a race. Both are powerful machines, but they excel in different areas.
The Apple M2 Pro is known for its energy efficiency and fast token generation speeds when working with smaller LLMs. It's a great choice for tasks like conversational AI and code completion, where prompt lengths are relatively small.
The NVIDIA RTX 6000 Ada is a beast of a GPU with massive memory (48GB) and powerful tensor cores, which gives it the edge for running larger LLMs with complex models and substantial context. It thrives on tasks that demand high throughput and parallel processing, like text generation, translation, and summarization.
But let's get down to the numbers.
Breakdown of Performance Differences
We'll compare the performance of the Apple M2 Pro 200GB 16-core chip and the NVIDIA RTX 6000 Ada 48GB GPU for the following LLM models using tokens per second (tokens/s) as our primary metric:
- Llama 2 7B (smaller, research-focused model)
- Llama 3 8B (larger, general-purpose model)
- Llama 3 70B (massive, state-of-the-art model)
Token Speed Generation Analysis: M2 Pro vs. RTX 6000 Ada
Let's dive into the nitty-gritty of token generation speeds. This metric tells us how quickly each device can process the inputs and outputs for an LLM, which is crucial for real-time applications.
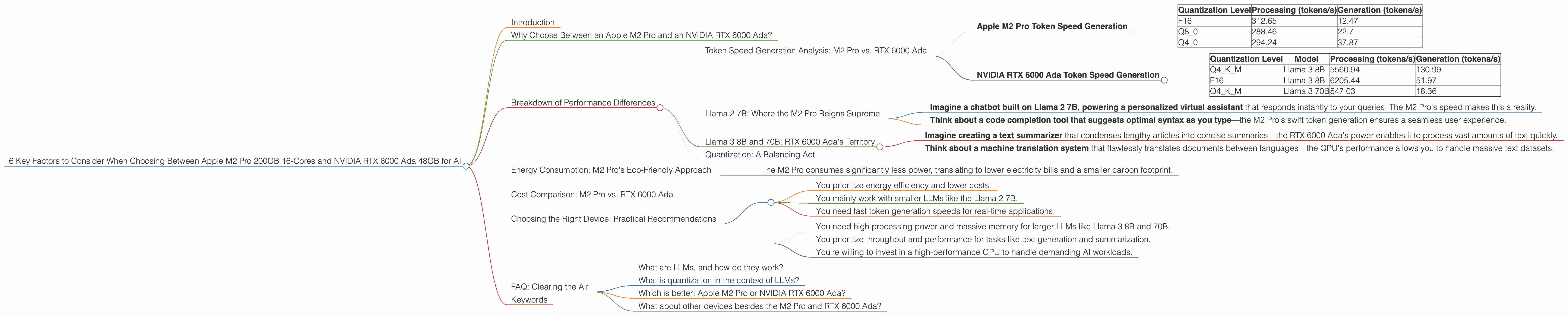
Apple M2 Pro Token Speed Generation
The Apple M2 Pro shows its strength when working with the Llama 2 7B model, delivering impressive token generation speeds across different quantization levels:
| Quantization Level | Processing (tokens/s) | Generation (tokens/s) |
|---|---|---|
| F16 | 312.65 | 12.47 |
| Q8_0 | 288.46 | 22.7 |
| Q4_0 | 294.24 | 37.87 |
Note: The 16-core M2 Pro achieved these results. The 19-core variant offers slightly improved speeds.
Key Takeaways:
- The M2 Pro excels at fast token generation speeds, particularly when dealing with the smaller Llama 2 7B model.
- Processing speeds are significantly higher than generation speeds, which is typical for LLMs, indicating a bottleneck during the output process.
- Quantization levels play a role in performance. Q4_0, the most aggressive quantization, offers the best token generation speed for the M2 Pro.
NVIDIA RTX 6000 Ada Token Speed Generation
NVIDIA's RTX 6000 Ada GPU shines when it comes to larger, more complex models:
| Quantization Level | Model | Processing (tokens/s) | Generation (tokens/s) |
|---|---|---|---|
| Q4KM | Llama 3 8B | 5560.94 | 130.99 |
| F16 | Llama 3 8B | 6205.44 | 51.97 |
| Q4KM | Llama 3 70B | 547.03 | 18.36 |
Note: F16 data for Llama 3 70B is unavailable.
Key Takeaways:
- The RTX 6000 Ada crushes the M2 Pro in throughput for larger models like the 8B and 70B Llama 3 variants.
- The device is capable of handling higher complexity and larger context windows compared to the M2 Pro.
- The 48GB of VRAM is a critical advantage for the RTX 6000 Ada when dealing with the massive 70B model.
Llama 2 7B: Where the M2 Pro Reigns Supreme
If you're working with the smaller Llama 2 7B model, the Apple M2 Pro is your champion. It boasts impressive token generation speeds, making it an ideal choice for real-time applications and interactive experiences:
Imagine a chatbot built on Llama 2 7B, powering a personalized virtual assistant that responds instantly to your queries. The M2 Pro's speed makes this a reality.
Think about a code completion tool that suggests optimal syntax as you type—the M2 Pro's swift token generation ensures a seamless user experience.
Llama 3 8B and 70B: RTX 6000 Ada's Territory
For larger LLM models like Llama 3 8B and 70B, the NVIDIA RTX 6000 Ada is the clear winner. It's a powerhouse for tasks that demand high throughput:
Imagine creating a text summarizer that condenses lengthy articles into concise summaries—the RTX 6000 Ada's power enables it to process vast amounts of text quickly.
Think about a machine translation system that flawlessly translates documents between languages—the GPU's performance allows you to handle massive text datasets.
Quantization: A Balancing Act
Quantization is a technique that reduces the size of LLM models by representing the weights with a smaller number of bits. While it can boost performance by requiring less memory and computation, it can also compromise accuracy.
Both the M2 Pro and RTX 6000 Ada support different quantization levels. The M2 Pro shines with Q40 for the Llama 2 7B model, achieving impressive speeds. However, the RTX 6000 Ada seems to favor Q4K_M for the larger Llama 3 models, demonstrating the device's capability to handle more complex quantizations.
Think of quantization like using a smaller paintbrush to paint—you might not be able to capture all the details, but you can paint much faster.
Energy Consumption: M2 Pro's Eco-Friendly Approach
The Apple M2 Pro reigns supreme regarding energy efficiency. Its power-sipping design makes it an eco-friendly choice for running AI tasks, especially when compared to the power-hungry RTX 6000 Ada:
- The M2 Pro consumes significantly less power, translating to lower electricity bills and a smaller carbon footprint.
Imagine running a chatbot on a M2 Pro, providing 24/7 assistance without breaking the bank. It's a sustainable and cost-effective solution.
Cost Comparison: M2 Pro vs. RTX 6000 Ada
The decision between the M2 Pro and RTX 6000 Ada often boils down to budget. The M2 Pro is generally more affordable than the high-end RTX 6000 Ada, especially when considering the cost of a desktop computer.
However, remember that the RTX 6000 Ada offers significantly more memory and processing power.
Consider your budget and the size of the LLMs you intend to run. If you're starting with smaller models and prioritize cost-effectiveness, the M2 Pro is a more accessible starting point.
Choosing the Right Device: Practical Recommendations
Here's a simplified approach to choosing between the Apple M2 Pro and NVIDIA RTX 6000 Ada for AI tasks:
Choose the Apple M2 Pro if:
- You prioritize energy efficiency and lower costs.
- You mainly work with smaller LLMs like the Llama 2 7B.
- You need fast token generation speeds for real-time applications.
Choose the NVIDIA RTX 6000 Ada if:
- You need high processing power and massive memory for larger LLMs like Llama 3 8B and 70B.
- You prioritize throughput and performance for tasks like text generation and summarization.
- You're willing to invest in a high-performance GPU to handle demanding AI workloads.
FAQ: Clearing the Air
What are LLMs, and how do they work?
LLMs are large language models, artificial intelligence systems trained on massive datasets of text and code. They can understand, generate, and manipulate human language in complex ways. Imagine a computer that has read every book and article ever written, making it incredibly knowledgeable about language.
What is quantization in the context of LLMs?
Quantization is a technique that compresses LLM models by reducing the precision of their weights. It's like replacing a high-resolution image with a lower-resolution version—you lose some detail but gain speed and reduce memory usage.
Which is better: Apple M2 Pro or NVIDIA RTX 6000 Ada?
There is no one "better" device. It depends on your specific needs and budget. The M2 Pro is ideal for smaller LLMs and faster token generation, while the RTX 6000 Ada shines for larger, more complex models and high throughput tasks.
What about other devices besides the M2 Pro and RTX 6000 Ada?
This article focuses on the comparison between the Apple M2 Pro and NVIDIA RTX 6000 Ada. Other devices might offer different advantages, depending on your needs. However, these two contenders represent some of the most powerful options for local LLM execution.
Keywords
Apple M2 Pro, NVIDIA RTX 6000 Ada, LLM, Llama 2, Llama 3, token speed, processing, generation, quantization, energy efficiency, cost, AI, machine learning, developer, geeky, performance, GPU, GPU benchmark, Llama.cpp, GPT, cloud computing, local execution, performance comparison, comparison chart, technical analysis.