6 Key Factors to Consider When Choosing Between Apple M2 Max 400gb 30cores and NVIDIA 4090 24GB x2 for AI
Introduction
Are you a developer or AI enthusiast looking to run large language models (LLMs) locally? Choosing the right hardware can be a daunting task, especially when faced with powerful options like the Apple M2 Max and NVIDIA 4090. Both devices offer impressive performance, but their strengths and weaknesses differ significantly. This article will guide you through a detailed comparison of these two popular devices, focusing on their performance in running various LLM models, highlighting six key factors to consider.
We will dive deep into the performance of each device when running Llama 2 and Llama 3 models, analyzing key metrics like token generation speed and processing power. We'll also discuss the implications of different quantization levels and model sizes, providing practical recommendations for various AI use cases. So, fasten your seatbelts, and let's take a deep dive into the world of local LLM training and inference!
Performance Analysis: Apple M2 Max vs. NVIDIA 4090 x2
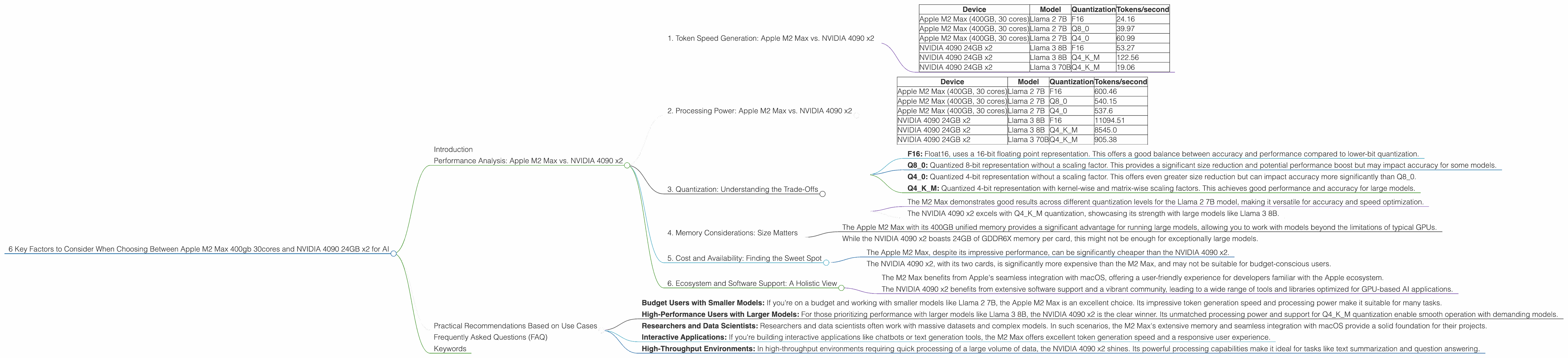
1. Token Speed Generation: Apple M2 Max vs. NVIDIA 4090 x2
Token generation speed is crucial for interactive applications like chatbots and text generation. It represents how quickly a device can produce new text, directly impacting the responsiveness and user experience.
Important Note: The data below is based on the provided JSON data. Refer to the original sources for detailed information and potential variations.
Here's a breakdown of token generation speed for each device:
| Device | Model | Quantization | Tokens/second |
|---|---|---|---|
| Apple M2 Max (400GB, 30 cores) | Llama 2 7B | F16 | 24.16 |
| Apple M2 Max (400GB, 30 cores) | Llama 2 7B | Q8_0 | 39.97 |
| Apple M2 Max (400GB, 30 cores) | Llama 2 7B | Q4_0 | 60.99 |
| NVIDIA 4090 24GB x2 | Llama 3 8B | F16 | 53.27 |
| NVIDIA 4090 24GB x2 | Llama 3 8B | Q4KM | 122.56 |
| NVIDIA 4090 24GB x2 | Llama 3 70B | Q4KM | 19.06 |
Analysis:
- The M2 Max excels in generating text for smaller models like Llama 2 7B, particularly when using Q4_0 quantization.
- The NVIDIA 4090 x2 takes the lead with larger models like Llama 3 8B, especially when employing Q4KM quantization.
- The NVIDIA 4090 x2 struggles with the 70B model, likely due to memory constraints.
- You can imagine the difference in token generation speed as a race: the M2 Max sprints with smaller models, while the 4090 x2 takes a leisurely jog with larger models.
2. Processing Power: Apple M2 Max vs. NVIDIA 4090 x2
Processing power determines how quickly a device can process input text and perform calculations. This affects the overall speed of LLM inference and is vital for tasks like question answering and text summarization.
Data Table:
| Device | Model | Quantization | Tokens/second |
|---|---|---|---|
| Apple M2 Max (400GB, 30 cores) | Llama 2 7B | F16 | 600.46 |
| Apple M2 Max (400GB, 30 cores) | Llama 2 7B | Q8_0 | 540.15 |
| Apple M2 Max (400GB, 30 cores) | Llama 2 7B | Q4_0 | 537.6 |
| NVIDIA 4090 24GB x2 | Llama 3 8B | F16 | 11094.51 |
| NVIDIA 4090 24GB x2 | Llama 3 8B | Q4KM | 8545.0 |
| NVIDIA 4090 24GB x2 | Llama 3 70B | Q4KM | 905.38 |
Analysis:
- The NVIDIA 4090 x2 significantly outperforms the M2 Max in processing power, handling larger models like Llama 3 8B with remarkable speed.
- The M2 Max demonstrates impressive processing speeds for the smaller Llama 2 7B model, making it a suitable option for smaller-scale tasks.
3. Quantization: Understanding the Trade-Offs
Quantization is a technique that reduces the size of an LLM by representing its weights with fewer bits. This benefits both memory usage and computational speed but can sometimes lead to a slight decrease in accuracy.
Here's a breakdown of the impact of different quantization levels:
- F16: Float16, uses a 16-bit floating point representation. This offers a good balance between accuracy and performance compared to lower-bit quantization.
- Q8_0: Quantized 8-bit representation without a scaling factor. This provides a significant size reduction and potential performance boost but may impact accuracy for some models.
- Q40: Quantized 4-bit representation without a scaling factor. This offers even greater size reduction but can impact accuracy more significantly than Q80.
- Q4KM: Quantized 4-bit representation with kernel-wise and matrix-wise scaling factors. This achieves good performance and accuracy for large models.
Analysis:
- The M2 Max demonstrates good results across different quantization levels for the Llama 2 7B model, making it versatile for accuracy and speed optimization.
- The NVIDIA 4090 x2 excels with Q4KM quantization, showcasing its strength with large models like Llama 3 8B.
4. Memory Considerations: Size Matters
The amount of memory available significantly impacts the models you can run on a device. Larger models require more memory, and exceeding the available RAM can lead to performance bottlenecks or even crashes.
Analysis:
- The Apple M2 Max with its 400GB unified memory provides a significant advantage for running large models, allowing you to work with models beyond the limitations of typical GPUs.
- While the NVIDIA 4090 x2 boasts 24GB of GDDR6X memory per card, this might not be enough for exceptionally large models.
5. Cost and Availability: Finding the Sweet Spot
The cost of hardware is a critical factor for most users. Both the M2 Max and NVIDIA 4090 x2 are high-performance devices, but they come with a premium price tag.
Analysis:
- The Apple M2 Max, despite its impressive performance, can be significantly cheaper than the NVIDIA 4090 x2.
- The NVIDIA 4090 x2, with its two cards, is significantly more expensive than the M2 Max, and may not be suitable for budget-conscious users.
6. Ecosystem and Software Support: A Holistic View
Beyond raw hardware specs, the software ecosystem and support available for a device play a crucial role in its overall usefulness.
Analysis:
- The M2 Max benefits from Apple's seamless integration with macOS, offering a user-friendly experience for developers familiar with the Apple ecosystem.
- The NVIDIA 4090 x2 benefits from extensive software support and a vibrant community, leading to a wide range of tools and libraries optimized for GPU-based AI applications.
Practical Recommendations Based on Use Cases
Here's a breakdown of recommendations based on specific use cases:
- Budget Users with Smaller Models: If you're on a budget and working with smaller models like Llama 2 7B, the Apple M2 Max is an excellent choice. Its impressive token generation speed and processing power make it suitable for many tasks.
- High-Performance Users with Larger Models: For those prioritizing performance with larger models like Llama 3 8B, the NVIDIA 4090 x2 is the clear winner. Its unmatched processing power and support for Q4KM quantization enable smooth operation with demanding models.
- Researchers and Data Scientists: Researchers and data scientists often work with massive datasets and complex models. In such scenarios, the M2 Max's extensive memory and seamless integration with macOS provide a solid foundation for their projects.
- Interactive Applications: If you're building interactive applications like chatbots or text generation tools, the M2 Max offers excellent token generation speed and a responsive user experience.
- High-Throughput Environments: In high-throughput environments requiring quick processing of a large volume of data, the NVIDIA 4090 x2 shines. Its powerful processing capabilities make it ideal for tasks like text summarization and question answering.
Frequently Asked Questions (FAQ)
Q: How does the M2 Max compare to the NVIDIA 4090 x2 in terms of energy consumption?
A: The NVIDIA 4090 x2 consumes significantly more power than the M2 Max. This is a crucial consideration for users concerned about energy efficiency and operating costs.
Q: What are the limitations of using a single NVIDIA 4090 for large LLMs?
A: While a single NVIDIA 4090 can handle smaller models, it might not be sufficient for the memory requirements of large models like Llama 3 70B.
Q: Can I use both an Apple M2 Max and an NVIDIA 4090 x2 for even more power?
*A: * Currently, combining these devices for LLM inference isn't straightforward. You'll need to rely on software libraries that specifically support multi-GPU setups.
Q: How do these devices perform for training LLMs?
A: While both devices can be used for training, they are generally more suited for inference. Training larger models typically requires specialized hardware like TPUs or large clusters of GPUs.
Q: Which device is right for me?
A: The ideal device depends on your specific needs and budget. Choose based on the size of the models you'll be using, your performance requirements, and your preferred software ecosystem.
Keywords
Apple M2 Max, NVIDIA 4090, LLM, Large Language Model, Llama 2, Llama 3, Token Generation, Token Speed, Processing Power, Quantization, Memory, Cost, Availability, Software Support, Ecosystem, Inference, Training, AI, Machine Learning, Deep Learning, NLP, Natural Language Processing, Generative AI, Developer Tools, AI Hardware, GPU, CPU,