6 Key Factors to Consider When Choosing Between Apple M1 Ultra 800gb 48cores and NVIDIA 3080 10GB for AI
Introduction
The world of AI is buzzing with excitement, and a key player in this revolution is the Large Language Model (LLM). These powerful AI models can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way. But to unleash the full potential of LLMs, you need the right hardware. This is where the Apple M1 Ultra and the NVIDIA 3080 come into play.
This article delves into the complex world of LLM hardware, guiding you through the process of picking the best device for your needs. We'll compare the Apple M1 Ultra 800GB 48-core processor with the NVIDIA 3080 10GB graphics card, highlighting their strengths and weaknesses in running various LLMs.
Comparison of Apple M1 Ultra and NVIDIA 3080 for LLM Model Performance
Choosing the right hardware for LLM model inference can be tricky. The Apple M1 Ultra and NVIDIA 3080 are both popular choices, but they excel in different areas. Let's dive into the key factors to help you make the best decision for your AI projects.
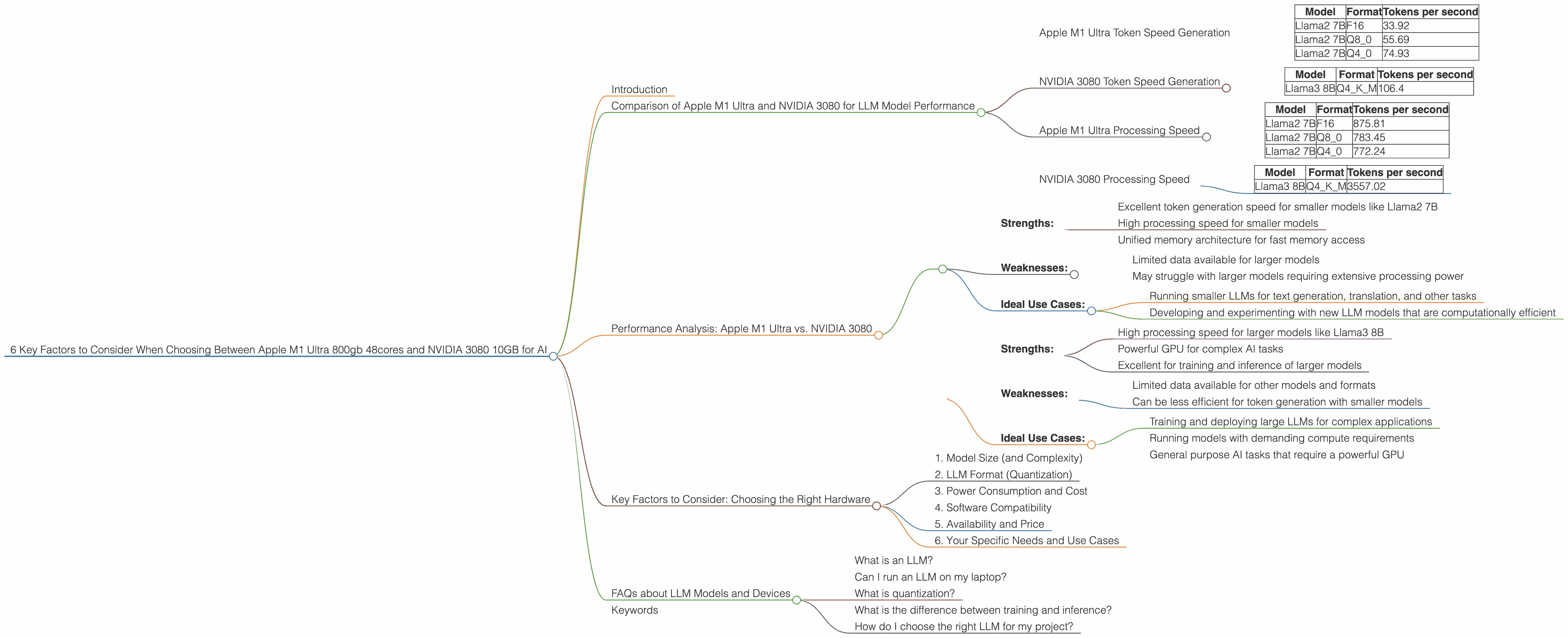
Apple M1 Ultra Token Speed Generation
The Apple M1 Ultra is a powerhouse when it comes to generating tokens – the building blocks of text. It shines in this area due to its incredible processing capabilities and the fast memory access that its unified memory architecture provides. Just picture this: the M1 Ultra is like a Formula 1 race car for processing text, zipping through tokens with lightning speed.
Let's look at the data:
| Model | Format | Tokens per second |
|---|---|---|
| Llama2 7B | F16 | 33.92 |
| Llama2 7B | Q8_0 | 55.69 |
| Llama2 7B | Q4_0 | 74.93 |
As you can see, the Apple M1 Ultra delivers impressive token generation speeds for the Llama2 7B model, even when using quantized representations like Q80 and Q40. Quantization is a technique that compresses the model, making it smaller and faster, but it can slightly affect the accuracy of the results.
NVIDIA 3080 Token Speed Generation
The NVIDIA 3080, while a powerful GPU, lags behind the M1 Ultra when it comes to token generation speed. This is mainly due to the memory bandwidth limitations of the 3080. The 3080 is more like a sleek sports car, fast but not as fast as the M1 Ultra in a drag race.
Here's the data we have:
| Model | Format | Tokens per second |
|---|---|---|
| Llama3 8B | Q4KM | 106.4 |
As you can see, the NVIDIA 3080 performs better than the M1 Ultra with the Llama3 8B model using Q4KM quantization. However, we don't have data for the 3080 for other formats or models, so it's challenging to make a direct comparison.
Apple M1 Ultra Processing Speed
The M1 Ultra shines in processing speed as well, with its multi-core architecture and lightning-fast memory access. Imagine it as a chef cooking up a delicious dish – it can quickly process all the ingredients simultaneously.
Let's look at the data for processing speed:
| Model | Format | Tokens per second |
|---|---|---|
| Llama2 7B | F16 | 875.81 |
| Llama2 7B | Q8_0 | 783.45 |
| Llama2 7B | Q4_0 | 772.24 |
NVIDIA 3080 Processing Speed
The NVIDIA 3080 is a processing powerhouse, excelling in handling large, computationally intensive tasks. It's like a massive industrial oven that can handle a huge batch of food.
Here's the data we have for processing speed:
| Model | Format | Tokens per second |
|---|---|---|
| Llama3 8B | Q4KM | 3557.02 |
As you can see, the NVIDIA 3080 significantly outperforms the M1 Ultra in processing speed for the Llama3 8B model using Q4KM quantization. However, we lack data for the 3080 with different formats or models, making it difficult to draw definitive conclusions.
Performance Analysis: Apple M1 Ultra vs. NVIDIA 3080
To sum up, the Apple M1 Ultra is a compelling choice for LLM inference for its high token generation speed and overall processing performance. It excels with smaller, more computationally efficient models like Llama2 7B. However, the NVIDIA 3080 takes the lead in processing speed, demonstrated by its performance with the Llama3 8B model.
Here's a breakdown:
Apple M1 Ultra:
- Strengths:
- Excellent token generation speed for smaller models like Llama2 7B
- High processing speed for smaller models
- Unified memory architecture for fast memory access
- Weaknesses:
- Limited data available for larger models
- May struggle with larger models requiring extensive processing power
- Ideal Use Cases:
- Running smaller LLMs for text generation, translation, and other tasks
- Developing and experimenting with new LLM models that are computationally efficient
NVIDIA 3080:
- Strengths:
- High processing speed for larger models like Llama3 8B
- Powerful GPU for complex AI tasks
- Excellent for training and inference of larger models
- Weaknesses:
- Limited data available for other models and formats
- Can be less efficient for token generation with smaller models
- Ideal Use Cases:
- Training and deploying large LLMs for complex applications
- Running models with demanding compute requirements
- General purpose AI tasks that require a powerful GPU
Key Factors to Consider: Choosing the Right Hardware
Now that you know the strengths and weaknesses of each device, let's explore six key factors to consider when choosing between the Apple M1 Ultra and the NVIDIA 3080 for your LLM projects:
1. Model Size (and Complexity)
The size of your chosen LLM model is a critical factor. The Apple M1 Ultra is well-suited for smaller models like Llama2 7B, while the NVIDIA 3080 reigns supreme for larger models like Llama3 8B. Think of it like this: if you're baking a small cake, you can handle it in a regular oven. But if you want to bake a giant cake, you'll need a professional industrial oven.
2. LLM Format (Quantization)
The format of your LLM model also matters. Quantization is a technique that reduces the model's size and can help improve performance. The Apple M1 Ultra excels with quantized formats like Q80 and Q40, while the NVIDIA 3080 is also efficient with these formats, though data is limited for other models and formats.
3. Power Consumption and Cost
Power consumption can be a concern for both devices. The Apple M1 Ultra is known for its power efficiency, while the NVIDIA 3080 can consume significantly more power, especially during intensive tasks. This can affect your electricity bill and your overall cost of operations.
4. Software Compatibility
Make sure your chosen hardware is compatible with the software you plan to use for LLM inference. Both the Apple M1 Ultra and NVIDIA 3080 have their own ecosystem of tools and libraries.
5. Availability and Price
Availability and price are crucial factors to consider. The Apple M1 Ultra is readily available, while the NVIDIA 3080 may be more difficult to find, especially during periods of high demand.
6. Your Specific Needs and Use Cases
Ultimately, the best hardware depends on your specific needs and use cases. Are you working with small, efficient models for simple tasks? The Apple M1 Ultra might be perfect for you. Do you need to train and deploy massive LLMs for complex applications? The NVIDIA 3080 could be your best bet.
FAQs about LLM Models and Devices
What is an LLM?
An LLM is a Large Language Model, a type of artificial intelligence that can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
Can I run an LLM on my laptop?
It depends on the LLM model and your laptop's hardware. Smaller LLMs can be run on some laptops with powerful processors. However, for larger LLMs, you'll likely need a dedicated GPU or a more powerful machine.
What is quantization?
Quantization is a technique used to reduce the size of a model without losing too much accuracy. Imagine it like reducing the number of colors in an image - you'll get a smaller file size, but you might lose some detail.
What is the difference between training and inference?
Training an LLM involves feeding it massive amounts of data to learn its patterns and relationships. Inference is the process of using the trained model to perform tasks like generating text or answering questions.
How do I choose the right LLM for my project?
The best LLM depends on your specific needs and the type of task you want to perform. Consider factors like model size, accuracy, and your available hardware.
Keywords
LLM, Large Language Model, Apple M1 Ultra, NVIDIA 3080, token speed, generation, processing, performance, inference, quantization, training, GPU, CPU, AI, machine learning, hardware, software, cost, power consumption, availability, use case, application.