6 Key Factors to Consider When Choosing Between Apple M1 Pro 200gb 14cores and NVIDIA RTX 4000 Ada 20GB x4 for AI
Introduction
The world of large language models (LLMs) is rapidly evolving, and with it, the need for powerful hardware to run these models effectively. Two popular choices for developers and researchers are the Apple M1 Pro chip and the NVIDIA RTX 4000 Ada graphics card. These devices offer different strengths and weaknesses, which can make choosing the right one for your AI project challenging.
This guide will compare the performance of the Apple M1 Pro 200gb 14cores and NVIDIA RTX 4000 Ada 20GB x4 for running popular LLM models like Llama 2 and Llama 3. We'll explore six key factors that can help you make an informed decision:
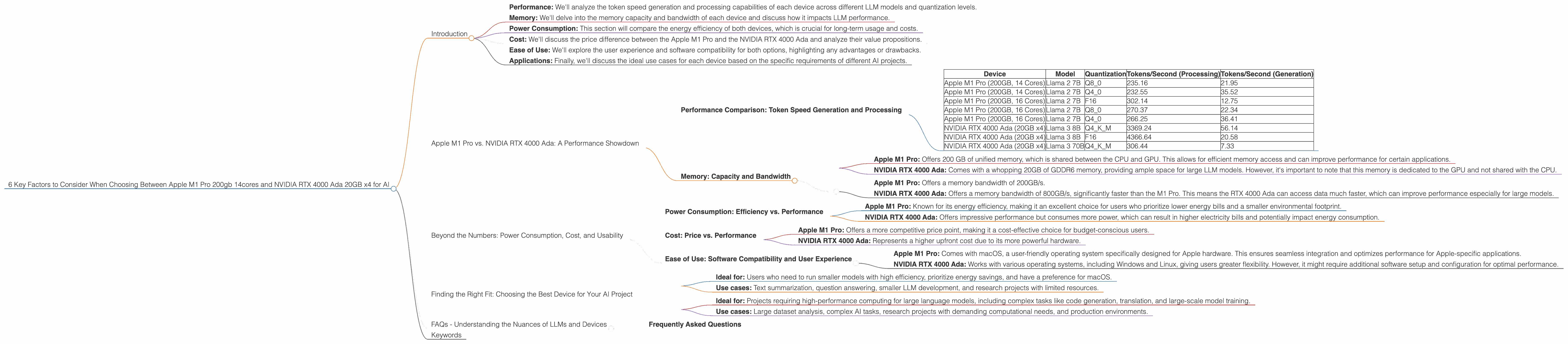
- Performance: We'll analyze the token speed generation and processing capabilities of each device across different LLM models and quantization levels.
- Memory: We'll delve into the memory capacity and bandwidth of each device and discuss how it impacts LLM performance.
- Power Consumption: This section will compare the energy efficiency of both devices, which is crucial for long-term usage and costs.
- Cost: We'll discuss the price difference between the Apple M1 Pro and the NVIDIA RTX 4000 Ada and analyze their value propositions.
- Ease of Use: We'll explore the user experience and software compatibility for both options, highlighting any advantages or drawbacks.
- Applications: Finally, we'll discuss the ideal use cases for each device based on the specific requirements of different AI projects.
Apple M1 Pro vs. NVIDIA RTX 4000 Ada: A Performance Showdown
Performance Comparison: Token Speed Generation and Processing
The heart of any LLM is its ability to generate and process tokens at a rapid pace. The Apple M1 Pro and NVIDIA RTX 4000 Ada excel in different areas, as we can see in the table below.
| Device | Model | Quantization | Tokens/Second (Processing) | Tokens/Second (Generation) |
|---|---|---|---|---|
| Apple M1 Pro (200GB, 14 Cores) | Llama 2 7B | Q8_0 | 235.16 | 21.95 |
| Apple M1 Pro (200GB, 14 Cores) | Llama 2 7B | Q4_0 | 232.55 | 35.52 |
| Apple M1 Pro (200GB, 16 Cores) | Llama 2 7B | F16 | 302.14 | 12.75 |
| Apple M1 Pro (200GB, 16 Cores) | Llama 2 7B | Q8_0 | 270.37 | 22.34 |
| Apple M1 Pro (200GB, 16 Cores) | Llama 2 7B | Q4_0 | 266.25 | 36.41 |
| NVIDIA RTX 4000 Ada (20GB x4) | Llama 3 8B | Q4KM | 3369.24 | 56.14 |
| NVIDIA RTX 4000 Ada (20GB x4) | Llama 3 8B | F16 | 4366.64 | 20.58 |
| NVIDIA RTX 4000 Ada (20GB x4) | Llama 3 70B | Q4KM | 306.44 | 7.33 |
Note: Data for Llama 2 7B F16 processing and generation on the Apple M1 Pro and Llama 3 70B F16 on the NVIDIA RTX 4000 Ada is unavailable.
Let's break down these numbers to understand the context.
Apple M1 Pro:
- Token Speed: The Apple M1 Pro shines in processing tokens, especially with the Q80 and Q40 quantization levels. This means it can quickly understand and analyze text, making it suitable for tasks like summarization and question answering. However, its token generation speed is significantly slower than the RTX 4000 Ada, especially in the F16 quantization.
- Strengths: Its strengths lie in its energy efficiency and handling smaller LLM models efficiently. For tasks involving text analysis and smaller models, the M1 Pro is a great choice.
NVIDIA RTX 4000 Ada:
- Token Speed: The NVIDIA RTX 4000 Ada excels in both processing and generating tokens, particularly with the Q4KM level. Its processing speed is far superior for larger models, making it a powerhouse for complex tasks like code generation and translation.
- Strengths: Its strengths lie in handling larger models and achieving high token speeds, making it more suitable for demanding applications with larger datasets.
To put it simply, imagine a marathon runner (Apple M1 Pro) and a sprinter (NVIDIA RTX 4000 Ada). The marathon runner can consistently maintain a good pace for long distances, while the sprinter bursts out at amazing speed for short sprints. Similarly, the M1 Pro is a steady performer for smaller tasks, while the RTX 4000 Ada delivers powerful bursts for more complex and demanding tasks.
Understanding Quantization:
Quantization is a technique used to compress the size of LLM models, which can improve performance and reduce memory usage. Lower quantization levels, like Q4_0, reduce the precision of calculations but are more computationally efficient. Higher levels, like F16, offer greater precision but require more resources.
Memory: Capacity and Bandwidth
Memory is crucial for storing and accessing the LLM model and the data it processes. Let's see how the M1 Pro and RTX 4000 Ada stack up.
- Apple M1 Pro: Offers 200 GB of unified memory, which is shared between the CPU and GPU. This allows for efficient memory access and can improve performance for certain applications.
- NVIDIA RTX 4000 Ada: Comes with a whopping 20GB of GDDR6 memory, providing ample space for large LLM models. However, it's important to note that this memory is dedicated to the GPU and not shared with the CPU.
Memory Bandwidth:
- Apple M1 Pro: Offers a memory bandwidth of 200GB/s.
- NVIDIA RTX 4000 Ada: Offers a memory bandwidth of 800GB/s, significantly faster than the M1 Pro. This means the RTX 4000 Ada can access data much faster, which can improve performance especially for large models.
The Verdict:
While the M1 Pro's unified memory offers advantages for smaller models and applications, the RTX 4000 Ada excels in memory capacity and bandwidth. This makes it a superior choice for running larger models like Llama 3 70B, which requires a significant amount of memory.
Beyond the Numbers: Power Consumption, Cost, and Usability
Power Consumption: Efficiency vs. Performance
Power consumption is a critical factor, especially for applications that run for extended periods.
- Apple M1 Pro: Known for its energy efficiency, making it an excellent choice for users who prioritize lower energy bills and a smaller environmental footprint.
- NVIDIA RTX 4000 Ada: Offers impressive performance but consumes more power, which can result in higher electricity bills and potentially impact energy consumption.
The Verdict:
The M1 Pro excels in energy efficiency, making it a budget-friendly option for long-term use, while the RTX 4000 Ada sacrifices energy efficiency for superior performance.
Cost: Price vs. Performance
The price point is another critical factor to consider. The M1 Pro generally falls into a more affordable price range, while the RTX 4000 Ada represents a significant investment.
- Apple M1 Pro: Offers a more competitive price point, making it a cost-effective choice for budget-conscious users.
- NVIDIA RTX 4000 Ada: Represents a higher upfront cost due to its more powerful hardware.
The Verdict:
The M1 Pro is more budget-friendly for those looking for a cost-effective solution, while the RTX 4000 Ada caters to users willing to invest in top-tier performance.
Ease of Use: Software Compatibility and User Experience
Both the Apple M1 Pro and NVIDIA RTX 4000 Ada offer user-friendly experiences, but there are subtle differences in software compatibility.
- Apple M1 Pro: Comes with macOS, a user-friendly operating system specifically designed for Apple hardware. This ensures seamless integration and optimizes performance for Apple-specific applications.
- NVIDIA RTX 4000 Ada: Works with various operating systems, including Windows and Linux, giving users greater flexibility. However, it might require additional software setup and configuration for optimal performance.
The Verdict:
The Apple M1 Pro offers a streamlined and optimized user experience for Apple users, while the NVIDIA RTX 4000 Ada provides wider software compatibility and flexibility.
Finding the Right Fit: Choosing the Best Device for Your AI Project
Choosing between the Apple M1 Pro and NVIDIA RTX 4000 Ada is ultimately about aligning the device's strengths with the specific needs of your AI project.
Apple M1 Pro:
- Ideal for: Users who need to run smaller models with high efficiency, prioritize energy savings, and have a preference for macOS.
- Use cases: Text summarization, question answering, smaller LLM development, and research projects with limited resources.
NVIDIA RTX 4000 Ada:
- Ideal for: Projects requiring high-performance computing for large language models, including complex tasks like code generation, translation, and large-scale model training.
- Use cases: Large dataset analysis, complex AI tasks, research projects with demanding computational needs, and production environments.
FAQs - Understanding the Nuances of LLMs and Devices
Frequently Asked Questions
Q: What are LLMs, and how do they work?
A: LLMs are large language models, which are AI systems trained on massive datasets of text and code. They can understand, generate, and translate human language in various ways, making them powerful tools for tasks like text summarization, question answering, and machine translation. Imagine LLMs as super-smart robots trained to understand and communicate like humans. They can learn from massive amounts of data and use that knowledge to perform complex tasks, like writing stories, translating languages, or even composing music.
Q: What is quantization, and why is it important for LLMs?
A: Quantization is a technique used to compress the size of LLM models. Think of it like using a smaller-sized file to store the same information, which allows for faster processing and reduced memory usage. Imagine a book with a lot of detailed illustrations. To make it smaller and easier to carry, you could remove some of the details and replace them with simpler symbols or outlines, thus retaining the core information but reducing the file size. Quantization works similarly by simplifying calculations in the LLM model.
Q: What are the benefits of using a device like the Apple M1 Pro or NVIDIA RTX 4000 Ada for LLMs?
A: These devices provide specialized hardware that accelerates the processing and generation of tokens, which are the building blocks of language. This leads to faster inference times, allowing your AI model to run more efficiently and produce results much faster.
Q: Which device is better for a particular LLM like Llama 2 7B or Llama 3 70B?
A: For Llama 2 7B, the Apple M1 Pro is an excellent choice, especially if you prioritize energy efficiency and cost-effectiveness. However, for Llama 3 70B, the NVIDIA RTX 4000 Ada is recommended due to its exceptional performance with larger models.
Keywords
Apple M1 Pro, NVIDIA RTX 4000 Ada, LLM, Llama 2, Llama 3, Token Speed, Processing, Generation, Quantization, Memory, Power Consumption, Cost, Ease of Use, Applications, AI, Developer, Researcher, Machine Learning, Deep Learning, Natural Language Processing.