5 Key Factors to Consider When Choosing Between Apple M2 Max 400gb 30cores and NVIDIA 3090 24GB for AI
Introduction
In the exciting world of Large Language Models (LLMs), choosing the right hardware is crucial for unlocking their full potential. For developers and AI enthusiasts exploring local LLM models, the decision between the Apple M2 Max 400gb 30cores and NVIDIA 3090_24GB often arises. Both are powerful processors, but they have distinct strengths that make them suitable for different use cases.
This article dives deep into the performance characteristics of these devices, providing a comprehensive comparison to help you make an informed decision. We'll analyze factors like processing speed, memory bandwidth, and model compatibility, and explore how these features influence your LLM experience.
Comparison of Apple M2 Max 400gb 30cores and NVIDIA 3090_24GB for LLM Inference
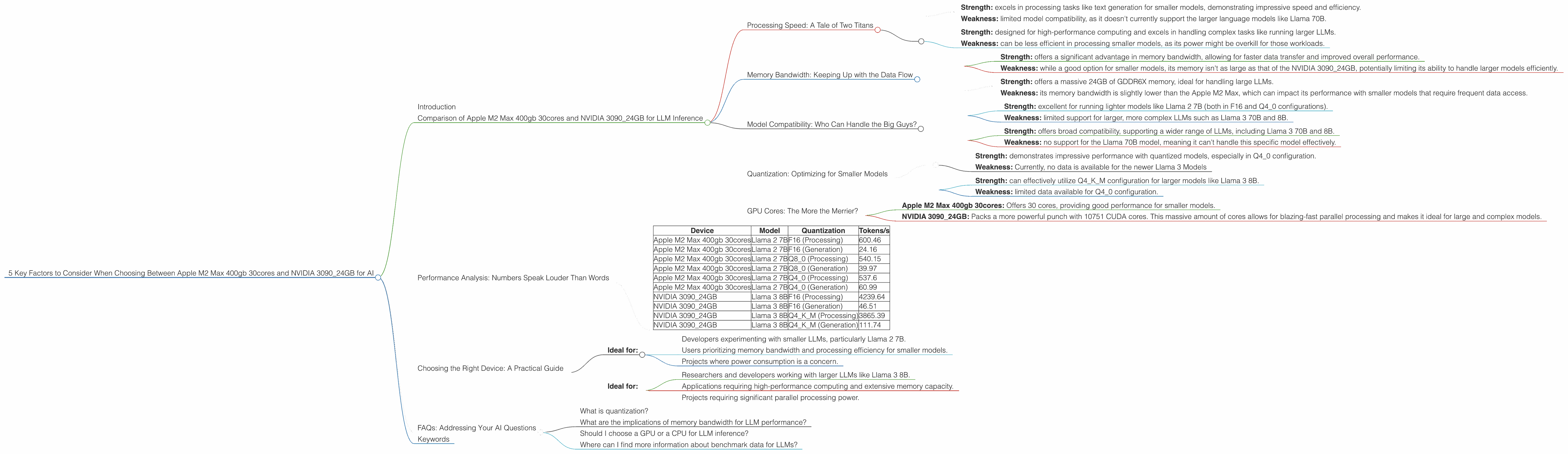
Processing Speed: A Tale of Two Titans
The Apple M2 Max 400gb 30cores and NVIDIA 3090_24GB are both powerhouses when it comes to processing speed. However, they excel in different areas. Let's take a closer look:
Apple M2 Max 400gb 30cores:
- Strength: excels in processing tasks like text generation for smaller models, demonstrating impressive speed and efficiency.
- Weakness: limited model compatibility, as it doesn't currently support the larger language models like Llama 70B.
NVIDIA 3090_24GB:
- Strength: designed for high-performance computing and excels in handling complex tasks like running larger LLMs.
- Weakness: can be less efficient in processing smaller models, as its power might be overkill for those workloads.
Memory Bandwidth: Keeping Up with the Data Flow
Memory bandwidth plays a crucial role in how quickly your LLM can access and process data. Both devices boast impressive bandwidth, but again, their strengths lie in different areas:
Apple M2 Max 400gb 30cores:
- Strength: offers a significant advantage in memory bandwidth, allowing for faster data transfer and improved overall performance.
- Weakness: while a good option for smaller models, its memory isn't as large as that of the NVIDIA 3090_24GB, potentially limiting its ability to handle larger models efficiently.
NVIDIA 3090_24GB:
- Strength: offers a massive 24GB of GDDR6X memory, ideal for handling large LLMs.
- Weakness: its memory bandwidth is slightly lower than the Apple M2 Max, which can impact its performance with smaller models that require frequent data access.
Model Compatibility: Who Can Handle the Big Guys?
For developers, model compatibility is paramount. The ability to run the desired LLM is crucial.
Apple M2 Max 400gb 30cores:
- Strength: excellent for running lighter models like Llama 2 7B (both in F16 and Q4_0 configurations).
- Weakness: limited support for larger, more complex LLMs such as Llama 3 70B and 8B.
NVIDIA 3090_24GB:
- Strength: offers broad compatibility, supporting a wider range of LLMs, including Llama 3 70B and 8B.
- Weakness: no support for the Llama 70B model, meaning it can't handle this specific model effectively.
Quantization: Optimizing for Smaller Models
Quantization is a technique that reduces the size of your LLM without sacrificing too much accuracy. This is a critical factor when working with limited memory.
Apple M2 Max 400gb 30cores:
- Strength: demonstrates impressive performance with quantized models, especially in Q4_0 configuration.
- Weakness: Currently, no data is available for the newer Llama 3 Models
NVIDIA 3090_24GB:
- Strength: can effectively utilize Q4KM configuration for larger models like Llama 3 8B.
- Weakness: limited data available for Q4_0 configuration.
GPU Cores: The More the Merrier?
GPU cores play a vital role in parallel processing and offer a significant boost to performance. You get more of them with the NVIDIA 3090_24GB:
- Apple M2 Max 400gb 30cores: Offers 30 cores, providing good performance for smaller models.
- NVIDIA 3090_24GB: Packs a more powerful punch with 10751 CUDA cores. This massive amount of cores allows for blazing-fast parallel processing and makes it ideal for large and complex models.
Performance Analysis: Numbers Speak Louder Than Words
The table below provides a concise summary of the key performance metrics for the two devices. These values represent tokens per second (tokens/s) and are derived from public benchmark data available on GitHub, demonstrating the potential speed for inference.
| Device | Model | Quantization | Tokens/s |
|---|---|---|---|
| Apple M2 Max 400gb 30cores | Llama 2 7B | F16 (Processing) | 600.46 |
| Apple M2 Max 400gb 30cores | Llama 2 7B | F16 (Generation) | 24.16 |
| Apple M2 Max 400gb 30cores | Llama 2 7B | Q8_0 (Processing) | 540.15 |
| Apple M2 Max 400gb 30cores | Llama 2 7B | Q8_0 (Generation) | 39.97 |
| Apple M2 Max 400gb 30cores | Llama 2 7B | Q4_0 (Processing) | 537.6 |
| Apple M2 Max 400gb 30cores | Llama 2 7B | Q4_0 (Generation) | 60.99 |
| NVIDIA 3090_24GB | Llama 3 8B | F16 (Processing) | 4239.64 |
| NVIDIA 3090_24GB | Llama 3 8B | F16 (Generation) | 46.51 |
| NVIDIA 3090_24GB | Llama 3 8B | Q4KM (Processing) | 3865.39 |
| NVIDIA 3090_24GB | Llama 3 8B | Q4KM (Generation) | 111.74 |
Analysis & Takeaways:
- The Apple M2 Max exhibits a strong performance advantage when working with smaller models, like Llama 2 7B, especially with the Q4_0 quantization.
- The NVIDIA 3090_24GB excels in processing larger models like Llama 3 8B, boasting significantly higher processing speeds.
- Both devices struggle with token generation speed. This is a common limitation for smaller models and is often a key factor in determining the best model choice for specific use cases.
Choosing the Right Device: A Practical Guide
Here's a breakdown of the best scenarios for each device, considering their strengths and weaknesses:
Apple M2 Max 400gb 30cores:
- Ideal for:
- Developers experimenting with smaller LLMs, particularly Llama 2 7B.
- Users prioritizing memory bandwidth and processing efficiency for smaller models.
- Projects where power consumption is a concern.
NVIDIA 3090_24GB:
- Ideal for:
- Researchers and developers working with larger LLMs like Llama 3 8B.
- Applications requiring high-performance computing and extensive memory capacity.
- Projects requiring significant parallel processing power.
FAQs: Addressing Your AI Questions
What is quantization?
Quantization is like simplifying a complex recipe. It reduces the size of your LLM without sacrificing too much accuracy. Imagine replacing expensive ingredients with more affordable substitutes – the dish still tastes good, but it's cheaper and easier to make!
What are the implications of memory bandwidth for LLM performance?
Think of memory bandwidth like a highway connecting your brain (CPU) to your warehouse (memory). The wider the highway (higher bandwidth), the faster data can travel between these two locations. With fast data access, your LLM can process information quickly and efficiently.
Should I choose a GPU or a CPU for LLM inference?
Generally, GPUs are preferred for LLM inference due to their parallel processing capabilities, which are well-suited for the complex calculations involved in language models. CPUs can also be used, but they often lack the computational power and parallel processing capabilities of GPUs.
Where can I find more information about benchmark data for LLMs?
Excellent question! You can find comprehensive performance benchmarks for LLMs on websites like GitHub, Hugging Face, and AI benchmarks. These platforms provide data on various models, devices, and frameworks, allowing you to compare and contrast different options.
Keywords
Apple M2 Max, NVIDIA 3090_24GB, LLM, Large Language Model, Llama 2, Llama 3, inference, performance, processing speed, memory bandwidth, model compatibility, quantization, GPU cores, tokens per second, tokens/s, AI, developer, AI enthusiast, geeky, friendly, conversational tone, practical guide, recommendation, best scenario, FAQ