5 Key Factors to Consider When Choosing Between Apple M1 Ultra 800gb 48cores and NVIDIA 3090 24GB x2 for AI
Introduction
The world of Large Language Models (LLMs) is booming. These powerful AI models are changing the way we interact with computers, revolutionizing fields like natural language processing, code generation, and even creative writing. Harnessing the power of LLMs requires significant computing resources, making the choice of hardware crucial.
This article dives deep into the comparison of two powerhouse machines: the Apple M1 Ultra 800GB 48 Core and the NVIDIA 3090 24GB x2 setup, exploring their strengths and weaknesses for running various LLM models. We'll analyze the performance of these devices across different LLM sizes and quantization levels, providing a comprehensive guide for developers and enthusiasts looking to optimize their AI endeavors.
Why This Comparison Matters
The Apple M1 Ultra and the NVIDIA 3090 x2 represent distinct approaches to AI computing. The M1 Ultra is a high-performance, integrated chip, designed for efficiency and energy savings. In contrast, the NVIDIA 3090 x2 is a powerful GPU setup, known for its raw processing power. Understanding the differences between these setups can help you choose the right tool for your specific LLM project.
Performance Analysis: A Deep Dive
To better understand the performance difference between the Apple M1 Ultra and the NVIDIA 3090 24GB x2, we'll analyze their capabilities in terms of processing and token speed generation for various LLM models.
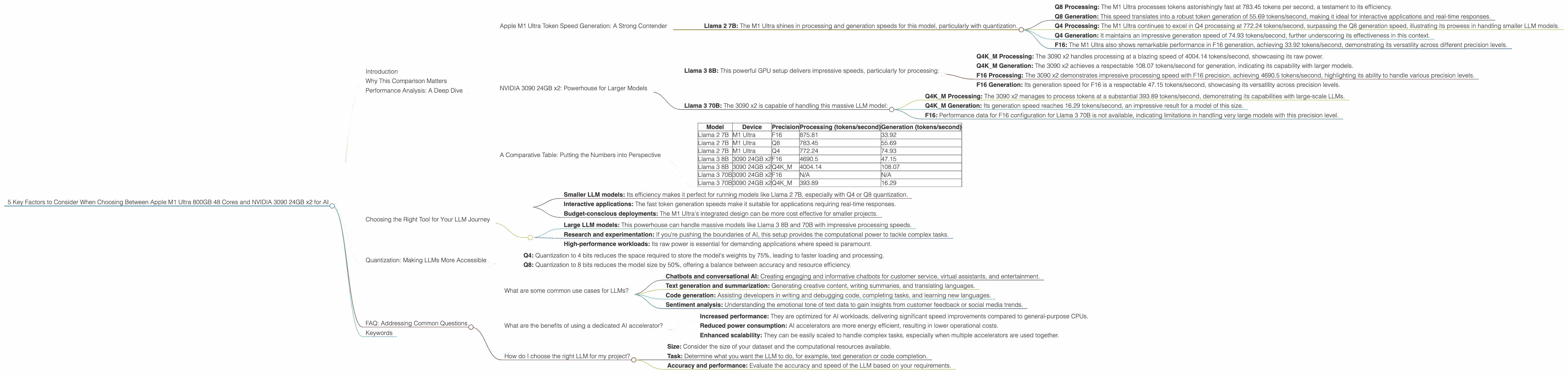
Apple M1 Ultra Token Speed Generation: A Strong Contender
The Apple M1 Ultra demonstrates impressive performance in token speed generation, especially for smaller LLM models like Llama 2 7B. Let's break it down:
- Llama 2 7B: The M1 Ultra shines in processing and generation speeds for this model, particularly with quantization.
- Q8 Processing: The M1 Ultra processes tokens astonishingly fast at 783.45 tokens per second, a testament to its efficiency.
- Q8 Generation: This speed translates into a robust token generation of 55.69 tokens/second, making it ideal for interactive applications and real-time responses.
- Q4 Processing: The M1 Ultra continues to excel in Q4 processing at 772.24 tokens/second, surpassing the Q8 generation speed, illustrating its prowess in handling smaller LLM models.
- Q4 Generation: It maintains an impressive generation speed of 74.93 tokens/second, further underscoring its effectiveness in this context.
- F16: The M1 Ultra also shows remarkable performance in F16 generation, achieving 33.92 tokens/second, demonstrating its versatility across different precision levels.
Key Takeaway: The Apple M1 Ultra is an excellent choice for running smaller LLM models like Llama 2 7B. Its efficiency and integrated design deliver impressive performance, especially for generating responses and interacting with users in real-time.
NVIDIA 3090 24GB x2: Powerhouse for Larger Models
The NVIDIA 3090 24GB x2, a dual GPU setup, excels in processing power, enabling it to handle larger, more complex LLM models with ease. Here's a breakdown:
- Llama 3 8B: This powerful GPU setup delivers impressive speeds, particularly for processing:
- Q4KM Processing: The 3090 x2 handles processing at a blazing speed of 4004.14 tokens/second, showcasing its raw power.
- Q4KM Generation: The 3090 x2 achieves a respectable 108.07 tokens/second for generation, indicating its capability with larger models.
- F16 Processing: The 3090 x2 demonstrates impressive processing speed with F16 precision, achieving 4690.5 tokens/second, highlighting its ability to handle various precision levels.
- F16 Generation: Its generation speed for F16 is a respectable 47.15 tokens/second, showcasing its versatility across precision levels.
- Llama 3 70B: The 3090 x2 is capable of handling this massive LLM model:
- Q4KM Processing: The 3090 x2 manages to process tokens at a substantial 393.89 tokens/second, demonstrating its capabilities with large-scale LLMs.
- Q4KM Generation: Its generation speed reaches 16.29 tokens/second, an impressive result for a model of this size.
- F16: Performance data for F16 configuration for Llama 3 70B is not available, indicating limitations in handling very large models with this precision level.
Key Takeaway: The NVIDIA 3090 24GB x2 excels in processing large LLM models like Llama 3 8B and 70B. This setup is ideal for research and experimentation, where speed and computational power are crucial.
A Comparative Table: Putting the Numbers into Perspective
To make the comparison clearer, let's present the performance data in a table format:
| Model | Device | Precision | Processing (tokens/second) | Generation (tokens/second) |
|---|---|---|---|---|
| Llama 2 7B | M1 Ultra | F16 | 875.81 | 33.92 |
| Llama 2 7B | M1 Ultra | Q8 | 783.45 | 55.69 |
| Llama 2 7B | M1 Ultra | Q4 | 772.24 | 74.93 |
| Llama 3 8B | 3090 24GB x2 | F16 | 4690.5 | 47.15 |
| Llama 3 8B | 3090 24GB x2 | Q4K_M | 4004.14 | 108.07 |
| Llama 3 70B | 3090 24GB x2 | F16 | N/A | N/A |
| Llama 3 70B | 3090 24GB x2 | Q4K_M | 393.89 | 16.29 |
Note: The table clearly shows that performance data for Llama 3 70B F16 is unavailable. It's important to note that the absence of data for certain configurations is a limitation of the current dataset.
Choosing the Right Tool for Your LLM Journey
The decision between Apple M1 Ultra and NVIDIA 3090 24GB x2 depends heavily on your needs:
Apple M1 Ultra is ideal for:
- Smaller LLM models: Its efficiency makes it perfect for running models like Llama 2 7B, especially with Q4 or Q8 quantization.
- Interactive applications: The fast token generation speeds make it suitable for applications requiring real-time responses.
- Budget-conscious deployments: The M1 Ultra's integrated design can be more cost effective for smaller projects.
NVIDIA 3090 24GB x2 is ideal for:
- Large LLM models: This powerhouse can handle massive models like Llama 3 8B and 70B with impressive processing speeds.
- Research and experimentation: If you're pushing the boundaries of AI, this setup provides the computational power to tackle complex tasks.
- High-performance workloads: Its raw power is essential for demanding applications where speed is paramount.
Quantization: Making LLMs More Accessible
Quantization is a technique that reduces the precision of LLM weights, resulting in smaller model sizes and faster processing. Think of it like using a smaller ruler to measure a room. You might not get the exact dimensions, but you get a good enough approximation.
- Q4: Quantization to 4 bits reduces the space required to store the model's weights by 75%, leading to faster loading and processing.
- Q8: Quantization to 8 bits reduces the model size by 50%, offering a balance between accuracy and resource efficiency.
The choice between different quantization levels depends on the trade-off between accuracy and performance. For applications where speed is crucial, Q4 or Q8 quantization can be beneficial, while for tasks requiring high accuracy, F16 or F32 may be preferred.
FAQ: Addressing Common Questions
What are some common use cases for LLMs?
LLMs have a wide range of applications, including:
- Chatbots and conversational AI: Creating engaging and informative chatbots for customer service, virtual assistants, and entertainment.
- Text generation and summarization: Generating creative content, writing summaries, and translating languages.
- Code generation: Assisting developers in writing and debugging code, completing tasks, and learning new languages.
- Sentiment analysis: Understanding the emotional tone of text data to gain insights from customer feedback or social media trends.
What are the benefits of using a dedicated AI accelerator?
Dedicated AI accelerators like the Apple M1 Ultra or NVIDIA 3090 24GB x2 offer several advantages:
- Increased performance: They are optimized for AI workloads, delivering significant speed improvements compared to general-purpose CPUs.
- Reduced power consumption: AI accelerators are more energy efficient, resulting in lower operational costs.
- Enhanced scalability: They can be easily scaled to handle complex tasks, especially when multiple accelerators are used together.
How do I choose the right LLM for my project?
The choice of LLM depends on your specific needs:
- Size: Consider the size of your dataset and the computational resources available.
- Task: Determine what you want the LLM to do, for example, text generation or code completion.
- Accuracy and performance: Evaluate the accuracy and speed of the LLM based on your requirements.
Keywords
LLM, Apple M1 Ultra, NVIDIA 3090, AI, Machine Learning, Deep Learning, Token Speed, Processing, Generation, Quantization, Q4, Q8, F16, Llama 2, Llama 3, AI accelerator, GPU, CPU, performance, efficiency, cost-effective, research, experimentation, use cases, chatbots, text generation, code generation, sentiment analysis.