5 Key Factors to Consider When Choosing Between Apple M1 Max 400gb 24cores and NVIDIA RTX 5000 Ada 32GB for AI
Introduction
Running large language models (LLMs) locally has become increasingly popular, empowering developers and enthusiasts to explore the power of AI directly on their machines. But with diverse hardware options available, choosing the right device for LLM inference can feel like navigating a maze. This article dives deep into a head-to-head comparison between two popular choices: the Apple M1 Max 400gb 24cores and the NVIDIA RTX 5000 Ada 32GB, helping you decipher the best match for your needs.
Think of it as a battle of the titans, where each device has its own strengths and weaknesses – and your project's needs will ultimately be the deciding factor. Whether you're a seasoned developer or a curious newbie, this guide will provide the insights and technical details to make an informed decision.
Performance Comparison: Apple M1 Max vs. NVIDIA RTX 5000 Ada 32GB
Let's jump into the heart of the matter – performance! We'll dissect the benchmark scores, analyze their strengths and weaknesses, and offer practical recommendations for real-world use cases.
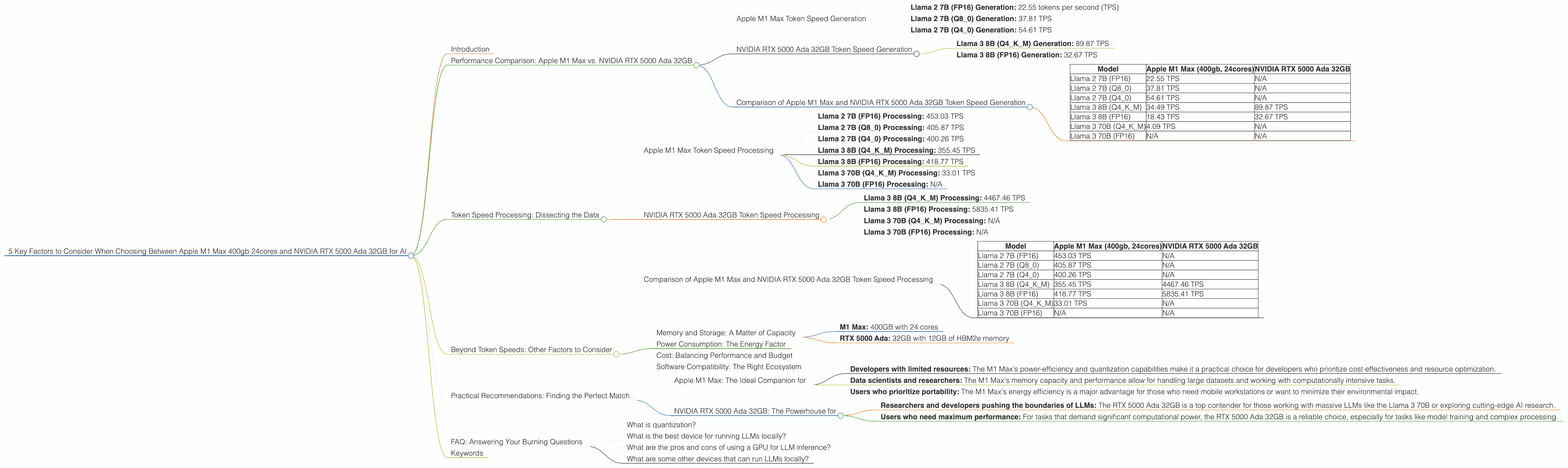
Apple M1 Max Token Speed Generation
The Apple M1 Max is a beast in its own right, especially when it comes to token generation. It's like a nimble sprinter, clocking in impressive speeds for smaller LLMs, like the Llama 2 7B model:
- Llama 2 7B (FP16) Generation: 22.55 tokens per second (TPS)
- Llama 2 7B (Q8_0) Generation: 37.81 TPS
- Llama 2 7B (Q4_0) Generation: 54.61 TPS
The M1 Max shines with its quantization capabilities, achieving remarkable speed boosts when using Q80 and Q40. Think of quantization as similar to compressing data, allowing the model to run more efficiently on a smaller device. The M1 Max's ability to handle these compressed formats makes it a great contender for developers working on projects with limited resources.
NVIDIA RTX 5000 Ada 32GB Token Speed Generation
The NVIDIA RTX 5000 Ada 32GB boasts a different kind of strength – it's a powerhouse for larger LLMs. With its more powerful processing ability, it excels at generating tokens for models like the Llama 3 8B and even 70B (though specific benchmarks for the latter are not available).
- Llama 3 8B (Q4KM) Generation: 89.87 TPS
- Llama 3 8B (FP16) Generation: 32.67 TPS
While the RTX 5000 Ada 32GB might not be as fast as the M1 Max for smaller LLMs, it truly shines when it comes to larger models, offering unparalleled performance.
Comparison of Apple M1 Max and NVIDIA RTX 5000 Ada 32GB Token Speed Generation
Let's summarize the token generation capabilities:
| Model | Apple M1 Max (400gb, 24cores) | NVIDIA RTX 5000 Ada 32GB |
|---|---|---|
| Llama 2 7B (FP16) | 22.55 TPS | N/A |
| Llama 2 7B (Q8_0) | 37.81 TPS | N/A |
| Llama 2 7B (Q4_0) | 54.61 TPS | N/A |
| Llama 3 8B (Q4KM) | 34.49 TPS | 89.87 TPS |
| Llama 3 8B (FP16) | 18.43 TPS | 32.67 TPS |
| Llama 3 70B (Q4KM) | 4.09 TPS | N/A |
| Llama 3 70B (FP16) | N/A | N/A |
Key Takeaways:
- The M1 Max is a good choice for smaller LLMs and those who prioritize quantization for performance.
- The RTX 5000 Ada 32GB excels when handling larger models. Its raw processing power gives it an edge for models like Llama 3 8B and beyond.
Token Speed Processing: Dissecting the Data
Now let's turn our attention to the other side of the coin – token speed processing. This metric measures how quickly the device can process and understand the input text before generating output.
Apple M1 Max Token Speed Processing
Here's how the Apple M1 Max performs on token speed processing:
- Llama 2 7B (FP16) Processing: 453.03 TPS
- Llama 2 7B (Q8_0) Processing: 405.87 TPS
- Llama 2 7B (Q4_0) Processing: 400.26 TPS
- Llama 3 8B (Q4KM) Processing: 355.45 TPS
- Llama 3 8B (FP16) Processing: 418.77 TPS
- Llama 3 70B (Q4KM) Processing: 33.01 TPS
- Llama 3 70B (FP16) Processing: N/A
The M1 Max consistently delivers respectable performance across different models and quantization levels, illustrating its overall efficiency in processing textual input. It's important to note that the model size does have an impact, with the M1 Max's performance dropping for the larger Llama 3 70B.
NVIDIA RTX 5000 Ada 32GB Token Speed Processing
The NVIDIA RTX 5000 Ada 32GB takes a different approach to token speed processing:
- Llama 3 8B (Q4KM) Processing: 4467.46 TPS
- Llama 3 8B (FP16) Processing: 5835.41 TPS
- Llama 3 70B (Q4KM) Processing: N/A
- Llama 3 70B (FP16) Processing: N/A
As expected, the RTX 5000 Ada 32GB shines in processing speed, significantly outperforming the M1 Max, especially for larger models. This is a testament to its powerful processing capabilities, demonstrating its strengths in handling complex AI tasks.
Comparison of Apple M1 Max and NVIDIA RTX 5000 Ada 32GB Token Speed Processing
Let's view this head-to-head:
| Model | Apple M1 Max (400gb, 24cores) | NVIDIA RTX 5000 Ada 32GB |
|---|---|---|
| Llama 2 7B (FP16) | 453.03 TPS | N/A |
| Llama 2 7B (Q8_0) | 405.87 TPS | N/A |
| Llama 2 7B (Q4_0) | 400.26 TPS | N/A |
| Llama 3 8B (Q4KM) | 355.45 TPS | 4467.46 TPS |
| Llama 3 8B (FP16) | 418.77 TPS | 5835.41 TPS |
| Llama 3 70B (Q4KM) | 33.01 TPS | N/A |
| Llama 3 70B (FP16) | N/A | N/A |
Key Takeaways:
- The M1 Max offers consistent and reliable processing performance across different model sizes and quantization levels.
- The RTX 5000 Ada 32GB shows its powerhouse status, providing immense processing speed for larger LLMs.
Beyond Token Speeds: Other Factors to Consider
While token speeds are crucial, they're not the only factors determining the best device for your LLM journey. Let's explore several other aspects to help you make a well-rounded decision:
Memory and Storage: A Matter of Capacity
- M1 Max: 400GB with 24 cores
- RTX 5000 Ada: 32GB with 12GB of HBM2e memory
The M1 Max boasts a massive storage capacity, providing ample room for large datasets and models. However, the RTX 5000 Ada compensates with a substantial dedicated GPU with 12GB HBM2e memory. This makes the RTX 5000 Ada a better choice for memory-intensive tasks like training large LLMs.
Power Consumption: The Energy Factor
The M1 Max is known for its energy efficiency, ideal for users mindful of power consumption. The RTX 5000 Ada, on the other hand, demands more power, especially when pushing its limits. This is a crucial factor for users who want to minimize their environmental impact or work with mobile workstations.
Cost: Balancing Performance and Budget
Both devices are in the higher price range, making cost a major consideration. The M1 Max and RTX 5000 Ada are not budget-friendly options, but they offer high-performance gains. Compare the specific pricing of each device across different retailers to find the best deal.
Software Compatibility: The Right Ecosystem
Both the M1 Max and RTX 5000 Ada have dedicated software ecosystems. The M1 Max benefits from Apple's optimized software environment, while the RTX 5000 Ada is favored by its integration with NVIDIA's CUDA platform. Consider your existing software tools and preferences when making your choice.
Practical Recommendations: Finding the Perfect Match
Now that we've dissected the key factors, let's translate them into practical recommendations for your LLM needs:
Apple M1 Max: The Ideal Companion for
- Developers with limited resources: The M1 Max's power-efficiency and quantization capabilities make it a practical choice for developers who prioritize cost-effectiveness and resource optimization.
- Data scientists and researchers: The M1 Max's memory capacity and performance allow for handling large datasets and working with computationally intensive tasks.
- Users who prioritize portability: The M1 Max's energy efficiency is a major advantage for those who need mobile workstations or want to minimize their environmental impact.
NVIDIA RTX 5000 Ada 32GB: The Powerhouse for
- Researchers and developers pushing the boundaries of LLMs: The RTX 5000 Ada 32GB is a top contender for those working with massive LLMs like the Llama 3 70B or exploring cutting-edge AI research.
- Users who need maximum performance: For tasks that demand significant computational power, the RTX 5000 Ada 32GB is a reliable choice, especially for tasks like model training and complex processing.
FAQ: Answering Your Burning Questions
What is quantization?
Quantization is like compressing data to make it smaller and easier to process. It's a technique used to reduce the size of LLM models, allowing them to run faster on devices with limited resources.
What is the best device for running LLMs locally?
The best device depends on your specific needs. For smaller LLMs, the Apple M1 Max is a great choice. However, for larger models like the Llama 3 70B, the NVIDIA RTX 5000 Ada 32GB is a better option.
What are the pros and cons of using a GPU for LLM inference?
GPUs are known for their parallel processing capabilities, making them ideal for accelerating LLM inference. However, they can be expensive and power-hungry.
What are some other devices that can run LLMs locally?
Other popular devices for running LLMs locally include the Google Tensor Processing Unit (TPU) and the AMD Radeon RX 7900 XTX.
Keywords
Apple M1 Max, NVIDIA RTX 5000 Ada 32GB, LLM, Large Language Model, token speed, inference, processing, quantization, FP16, Q80, Q40, Llama 2, Llama 3, memory, storage, power consumption, cost, software compatibility, CUDA, AI, machine learning, deep learning, performance, comparison, recommendation, FAQ, keywords, SEO.