5 Key Factors to Consider When Choosing Between Apple M1 Max 400gb 24cores and NVIDIA 3080 Ti 12GB for AI
Introduction
In the world of large language models (LLMs), processing power is king. These powerful AI systems require substantial computational resources to deliver their impressive capabilities. Choosing the right hardware for your LLM deployment can significantly impact the speed, efficiency, and even the accessibility of your models. This article compares two popular options for running LLMs locally: the Apple M1 Max 400gb 24cores and the NVIDIA 3080 Ti 12GB – two powerhouses in the world of computing. We'll explore the key factors you should consider when deciding which device is best for your specific needs.
Key Factors to Consider When Choosing Hardware for Running LLMs
1. Model Size and Complexity
The size and complexity of your LLM are paramount considerations. Smaller models like Llama 7B can be run on both the Apple M1 Max and NVIDIA 3080 Ti with relative ease. However, larger LLM models, such as Llama 13B, Llama 30B, or Llama 70B, might require greater resources. The choice depends on the specific model you plan to run and the desired performance level.
2. Quantization and Memory Constraints
Quantization is a technique used to reduce the storage space required for LLM models. It essentially compresses the model by converting its data from high-precision floating-point numbers to lower-precision formats like Q8 or Q4. 🤯 This means you can potentially run larger models on limited hardware.
Think of it like this: imagine you're trying to fit a suitcase full of clothes (your full-precision LLM) into a smaller bag (your GPU). Quantization is like changing your clothes to smaller sizes, allowing you to pack more in the same space.
For example, the Apple M1 Max, with its 400 GB memory capacity, might handle larger models effectively when quantized to Q8 or Q4. However, while the NVIDIA 3080 Ti is known for its raw processing power, limited memory (12 GB) might pose a challenge when running massive models, especially without quantization.
3. Token Speed Generation
Token speed generation refers to how quickly the model processes and generates new text. The higher the token speed, the faster your LLM can respond to prompts and churn out text.
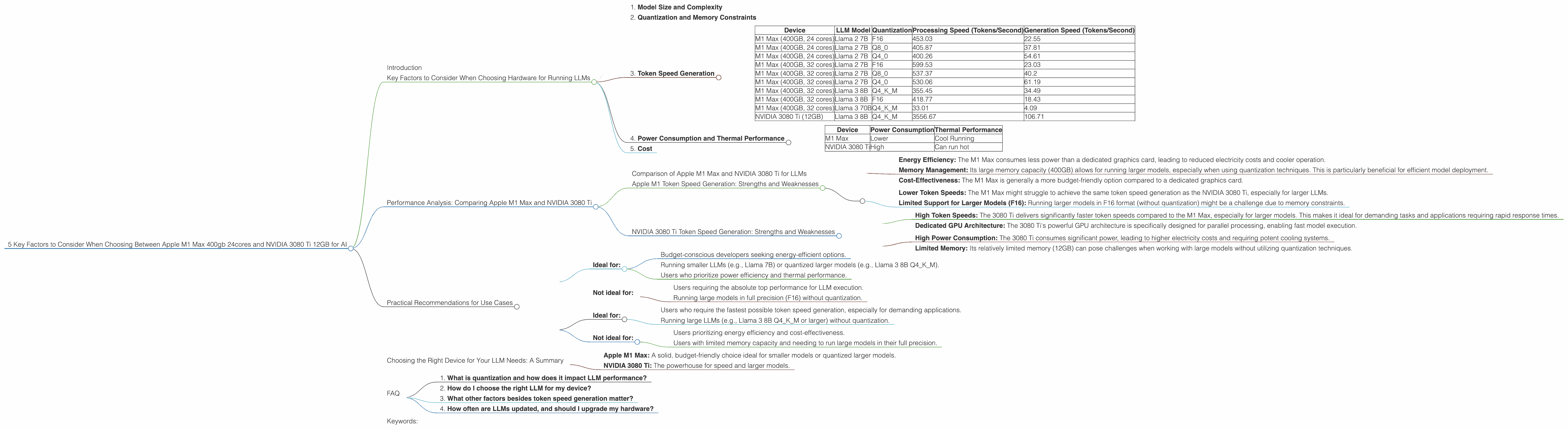
Here's a table comparing the token speed generation for different LLM models on the M1 Max and NVIDIA 3080 Ti:
| Device | LLM Model | Quantization | Processing Speed (Tokens/Second) | Generation Speed (Tokens/Second) |
|---|---|---|---|---|
| M1 Max (400GB, 24 cores) | Llama 2 7B | F16 | 453.03 | 22.55 |
| M1 Max (400GB, 24 cores) | Llama 2 7B | Q8_0 | 405.87 | 37.81 |
| M1 Max (400GB, 24 cores) | Llama 2 7B | Q4_0 | 400.26 | 54.61 |
| M1 Max (400GB, 32 cores) | Llama 2 7B | F16 | 599.53 | 23.03 |
| M1 Max (400GB, 32 cores) | Llama 2 7B | Q8_0 | 537.37 | 40.2 |
| M1 Max (400GB, 32 cores) | Llama 2 7B | Q4_0 | 530.06 | 61.19 |
| M1 Max (400GB, 32 cores) | Llama 3 8B | Q4KM | 355.45 | 34.49 |
| M1 Max (400GB, 32 cores) | Llama 3 8B | F16 | 418.77 | 18.43 |
| M1 Max (400GB, 32 cores) | Llama 3 70B | Q4KM | 33.01 | 4.09 |
| NVIDIA 3080 Ti (12GB) | Llama 3 8B | Q4KM | 3556.67 | 106.71 |
Note: Data for Llama 3 70B and Llama 3 8B on the 3080 Ti in F16 is not available. Data for Llama 3 70B on the M1 Max in F16 is not available.
Observations:
- Speed Advantage of * *NVIDIA 3080 Ti: The NVIDIA 3080 Ti generally demonstrates significantly faster processing and generation speeds compared to the M1 Max, especially for larger models like the Llama 3 8B. This is mainly driven by the dedicated GPU architecture of the 3080 Ti, designed for parallel processing.
- M1 Max for Quantized Models: The M1 Max shines when running quantized models, particularly Q4 and Q8. The improved memory efficiency of quantization allows the M1 Max to handle substantial models like Llama 2 7B or Llama 3 8B, while still providing decent token speeds.
4. Power Consumption and Thermal Performance
Power consumption and thermal performance are important considerations, especially for long-term LLM usage. The Apple M1 Max is known for its energy efficiency, consuming less power than the NVIDIA 3080 Ti. This translates to lower electricity bills and less heat generated, making it suitable for prolonged AI tasks.
The NVIDIA 3080 Ti, however, is a power-hungry beast. Its high performance comes at the cost of significant power consumption, leading to higher electricity costs and potentially requiring substantial cooling systems.
| Device | Power Consumption | Thermal Performance |
|---|---|---|
| M1 Max | Lower | Cool Running |
| NVIDIA 3080 Ti | High | Can run hot |
5. Cost
Finally, cost is a critical factor. The Apple M1 Max is generally more affordable than a dedicated NVIDIA 3080 Ti gaming card. However, the NVIDIA 3080 Ti often comes with a wider range of options, including pre-built desktop PCs or workstations, which might increase the overall cost.
Performance Analysis: Comparing Apple M1 Max and NVIDIA 3080 Ti
Comparison of Apple M1 Max and NVIDIA 3080 Ti for LLMs
The Apple M1 Max and the NVIDIA 3080 Ti offer contrasting performance profiles when running LLMs. The M1 Max excels in energy efficiency and memory management, making it suitable for running quantized models on a budget. The NVIDIA 3080 Ti, on the other hand, is a processing powerhouse, delivering significantly faster token speeds, especially for larger models.
Apple M1 Token Speed Generation: Strengths and Weaknesses
The Apple M1 Max demonstrates reasonable performance with smaller LLMs, particularly when using quantization. It offers a good balance between speed and power consumption. However, its performance with larger models, especially in F16 format, might be less impressive compared to the NVIDIA 3080 Ti.
Here's a breakdown of Apple M1 Max strengths and weaknesses regarding token speed generation:
Strengths:
- Energy Efficiency: The M1 Max consumes less power than a dedicated graphics card, leading to reduced electricity costs and cooler operation.
- Memory Management: Its large memory capacity (400GB) allows for running larger models, especially when using quantization techniques. This is particularly beneficial for efficient model deployment.
- Cost-Effectiveness: The M1 Max is generally a more budget-friendly option compared to a dedicated graphics card.
Weaknesses:
- Lower Token Speeds: The M1 Max might struggle to achieve the same token speed generation as the NVIDIA 3080 Ti, especially for larger LLMs.
- Limited Support for Larger Models (F16): Running larger models in F16 format (without quantization) might be a challenge due to memory constraints.
NVIDIA 3080 Ti Token Speed Generation: Strengths and Weaknesses
The NVIDIA 3080 Ti is a true powerhouse for LLM processing. Its dedicated GPU architecture enables blazing-fast token speed generation, particularly for larger models. However, its high power consumption and limited memory (12GB) are significant drawbacks.
Here's a breakdown of the 3080 Ti strengths and weaknesses regarding token speed generation:
Strengths:
- High Token Speeds: The 3080 Ti delivers significantly faster token speeds compared to the M1 Max, especially for larger models. This makes it ideal for demanding tasks and applications requiring rapid response times.
- Dedicated GPU Architecture: The 3080 Ti's powerful GPU architecture is specifically designed for parallel processing, enabling fast model execution.
Weaknesses:
- High Power Consumption: The 3080 Ti consumes significant power, leading to higher electricity costs and requiring potent cooling systems.
- Limited Memory: Its relatively limited memory (12GB) can pose challenges when working with large models without utilizing quantization techniques.
Practical Recommendations for Use Cases
Apple M1 Max:
- Ideal for:
- Budget-conscious developers seeking energy-efficient options.
- Running smaller LLMs (e.g., Llama 7B) or quantized larger models (e.g., Llama 3 8B Q4KM).
- Users who prioritize power efficiency and thermal performance.
- Not ideal for:
- Users requiring the absolute top performance for LLM execution.
- Running large models in full precision (F16) without quantization.
NVIDIA 3080 Ti:
- Ideal for:
- Users who require the fastest possible token speed generation, especially for demanding applications.
- Running large LLMs (e.g., Llama 3 8B Q4KM or larger) without quantization.
- Not ideal for:
- Users prioritizing energy efficiency and cost-effectiveness.
- Users with limited memory capacity and needing to run large models in their full precision.
Choosing the Right Device for Your LLM Needs: A Summary
Choosing the right device for your LLM depends on your specific needs, priorities, and the models you plan to use.
- Apple M1 Max: A solid, budget-friendly choice ideal for smaller models or quantized larger models.
- NVIDIA 3080 Ti: The powerhouse for speed and larger models.
FAQ
1. What is quantization and how does it impact LLM performance?
Quantization is a technique for compressing LLM models and reducing their memory footprint. It replaces full-precision (F16) numbers with lower-precision formats (e.g., Q8 or Q4). This results in smaller models that can fit into limited memory, but it can also impact token speed generation.
Think of it like comparing a detailed map with a simplified one. The detailed map (F16) provides precise information but is bulky. The simplified map (Q8 or Q4) is smaller and easier to carry but might lack some finer details. Similarly, quantized models are faster to load and process but may have slightly reduced accuracy.
2. How do I choose the right LLM for my device?
The choice depends on your device's memory and processing power. Smaller LLMs like Llama 7B can be run on both M1 Max and NVIDIA 3080 Ti. For larger models, the NVIDIA 3080 Ti might be your better bet for performance, but quantization might be necessary for the M1 Max.
3. What other factors besides token speed generation matter?
While token speed generation is important, consider model accuracy, latency (the time it takes to respond to a prompt), and power consumption. For example, a model that generates text quickly but with low accuracy might not be useful.
4. How often are LLMs updated, and should I upgrade my hardware?
LLMs are constantly being updated, so it's essential to stay informed. Consider upgrading your hardware if you find your current device is struggling to keep up with newer models or if your application demands significant processing power.
Keywords:
Apple M1 Max, NVIDIA 3080 Ti, LLM, Large Language Model, Llama 2 7B, Llama 3 8B, Llama 3 70B, Quantization, F16, Q8, Q4, Token Speed Generation, Processing Speed, Generation Speed, Memory, GPU, Power Consumption, Thermal Performance, Performance Analysis, AI, Machine Learning, Deep Learning, Comparison.